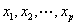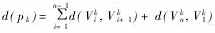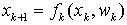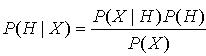我国区域物流节点城市发展的统计评价分析
来源:岁月联盟
时间:2014-10-15
关键词:区域物流;节点城市;因子分析;聚类分析
一、 引言
本文综合以前学者的研究成果,突出不同区域的物流产业发展水平,提出更为简便可行的指标体系,同时运用因子分析和聚类分析,对这些区域节点城市的物流发展水平进行比较研究,最后针对分析结果提出一些改进建议。
二、 区域物流发展指标体系的构建
1. 评价指标体系的建立。本文选取的指标力图能够反映区域物流发展的整体水平,通过对各种物流评价指标体系的比较,按照指标设置的原则,经过反复筛选,最终从人口规模、经济实力、工业规模、第三产业规模、物流主导产业规模五个方面确立了现代区域物流评价指标体系,并将这些方面分解为9项二级指标(表1)。
2. 数据来源与分析步骤。本研究的数据来源于《中国城市统计年鉴2009》以及各城市统计年鉴,由于在17个区域物流节点城市中,数据符合要求的有11个城市,包括哈尔滨、长春、包头、呼和浩特、太原、合肥、福州、长沙、昆明、海口、银川,本文就以这些城市为研究对象。在数据准备阶段完成之后,利用SPSS17.0for windows统计软件从以下几个方面展开分析。首先检验构建的区域物流评估指标系统,然后选择因子分析法从9个具体指标中提取出n个公共因子,根据得到的因子得分,建立模型计算综合得分,从而对各节点城市的物流综合水平进行排序,为确保研究结果的科学性和可靠性,在因子分析的基础上进一步进行聚类分析, 并利用聚类分析结果对全国区域物流节点城市的发展水平进行总体评价,并给出相应的政策建议。
三、 因子分析
1. 因子分析适用性检验。在指标综合评价中利用因子分析的目的是从众多的原有指标变量中提取出少量的具有代表性的因子,提取出的因子必须能够代表不同的评价维度。其应用的前提是要求原指标之间具有较强的相关关系,否则就不能运用因子分析法,我们将原始数据进行标准化处理之后,采用KMO和Bartlett检验方法来检测因子分析法的适用性。其检测结果如表2所示。
Bartlett球度检验表明:Bartlett值=131.602。P接近于0,若显著性水平为0.01,则拒绝相关矩阵为单位矩阵的原假设,相关矩阵与单位矩阵存在显著差异,可以进行因子分析。取样足够的Kaiser-Meyer-Olkin检验是用于比较观测相关系数值与偏相关数值的一个指标,其值越逼近1,表明对这些变量进行因子分析的效果越好,从表2中可见,KMO值大于0.5,因而可以对指标变量进行因子分析。
2. 因子提取。本文采用主成分分析法对指标数据进行因子分析,按照相关系数矩阵特征值大于1的标准,从原9个统计指标中提取二个主因子来表达其信息含量。表3是指标数据作因子分析后的因子提取和因子旋转结果。第二列至第四列描述了因子分析的初始解对原有变量总体的刻画情况;第二列合计是各成分的特征值。第一成分特征值合计=4.883,第二成分特征值为合计=1.797,这里只有前两个因子的特征值大于1。第三列是各因子变量的方差贡献率,即该因子刻画的方差占原有变量总方差的比例;第四列是因子变量的累计方差贡献率,表示前m个因子刻画的总方差占原有变量总方差的比例。从表3中可见,如果提取2个公共因子,那么它们可描述原变量总方差的90.536%,大于80%,可以认为,这2个公因子基本反映了原变量的绝大部分信息。
3. 因子旋转。因子分析的目的不仅是要找出主因子,更重要的是知道每个主因子的具体经济意义。为便于对主因子进行解释,一般须对因子载荷矩阵进行旋转。本研究采用方差极大值法进行正交旋转之后,得到9个指标的两个因子负荷,如表4所示。
从表4可以看出,第一主成分对社会消费品零售总额、国内生产总值、第三产业增加值、年末总人口、工业总产值有绝对值较大的相关系数,第二个因子相关系数绝对数较大的正好是九个原始变量中的另外四个,即货运总量、公路货运量、铁路货物运量、交通运输、仓储及邮政业增加值。根据这些变量的原始含义可以对两个因子进行命名。第一个因子主要概括了一般的社会人口规模、经济实力、工业和第三产业的规模,可以命名为社会经济因子。第二个因子主要概括了物流主导产业的情况,可以称为物流产业因子。
根据表4的最终因子载荷矩阵,由此可以写出如下因子分析的模型:
X1=0.979F1+0.024F2;X2=0.974F1+0.183F2;……;X9=0.324F1+0.879F2
Xi(i=1,2,…,9)代表了9个评价指标,公共因子F1表示社会经济因子,F2表示物流产业因子。由于因子载荷矩阵是正交旋转,这两个因子之间不存在相关,避免了因子综合评价的多重共线性,故可以代表不同的评价维度。
4. 因子得分。因子分析把原来的9个指标浓缩成相互独立的2个公因子,一方面达到了降维的目的;另一方面也排除了指标之间的相关性,同时,SPSS根据因子得分函数自动计算各样本的因子得分,并选取各因子的方差贡献率为因子得分权重,计算各城市的综合因子得分,其计算形式为:
F=0.511 09F1+0.394 26F2
每个城市的综合因子得分反映了各节点城市区域物流综合实力的强弱,将11个城市的综合因子得分从高到低排序,如表5所示。
四、 聚类分析
聚类分析是研究“物以类聚”的一种多元统计分析方法。最常用最基本的一种聚类分析方法是层次聚类分析,此外还有动态聚类法、模糊聚类法、有序聚类法等,本研究采用层次聚类法。
层次聚类法的基本思想是,一开始将要归类的n个变量看成一类,然后按事先规定好的方法计算各类之间的归类指数(相似系数或距离),根据指数大小衡量两类之间的密切程度,将关系最密切的两类并成一类,其余不变,即得n-1类;重新计算各类之间的归类指数,再将关系最密切的两类并成一类,其余不变,即得n-2类;如此进行下去,直到最后n个变量都归成一类。
下一篇:影子价格长短期划分及其计算