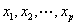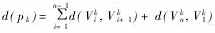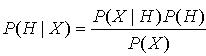基于蒙特卡洛方法的高斯混合采样粒子滤波算法研究
来源:岁月联盟
时间:2010-07-10
1 引言
贝叶斯方法为动态系统的估计问题提供了一类严谨的解决框架。它利用已知的信息建立系统的概率密度函数可以得到对系统状态估计的最优解。对于线性高斯的估计问题,期望的概率密度函数仍是高斯分布,它的分布特性可用均值和方差来描述。卡尔曼滤波器很好地解决了这类估计问题[1]。对于非线性系统的估计问题,最经典并得到广泛应用的方法以扩展的卡尔曼滤波为代表,这类方法需要对模型进行线性化,同时要求期望的概率密度函数满足高斯分布,然而在对实际系统建模时,模型往往是非线性非高斯的。此时,最优估计很难实现。 粒子(particle)滤波器——序列重要性采样粒子滤波器,是一种适用于强非线性、无高斯约束的基于模拟的统计滤波器[2]。它利用一定数量的粒子来表示随机变量的后验概率分布,从而可以近似得到任意函数的数学期望,并且能应用于任意非线性随机系统。本文介绍一种估计性能更好的粒子滤波算法——高斯混合采样粒子滤波器(GMSPPF),相比通常意义上的粒子滤波算法(SIR-PF),GMSPPF粒子滤波器具有更小的系统状态估计的均方误差和均值。2 贝叶斯滤波问题
贝叶斯滤波用概率统计的方法从已观察到的数据中获得动态状态空间(DSS)模型参数。在DSS模型中,包含状态和观测两个方程[3][4]。其中状态转移方程(State Equation)通常写作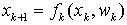 (1)这里,
(1)这里,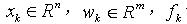 是已知,且
是已知,且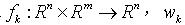 是白噪声独立的随机序列,而且分布是已知的。观测方程表达式写为
是白噪声独立的随机序列,而且分布是已知的。观测方程表达式写为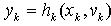 (2)这里:
(2)这里: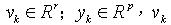 是白噪声序列,独立且分布已知。并且
是白噪声序列,独立且分布已知。并且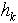 满足
满足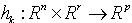 。 图1描述了DSS模型中状态转移和似然函数的关系。假设初始时刻系统的状态分布
。 图1描述了DSS模型中状态转移和似然函数的关系。假设初始时刻系统的状态分布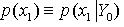 已知,k时刻的已知信息序列表示
已知,k时刻的已知信息序列表示 。
。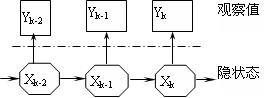 图1 动态状态空间模型(DSSM) 这样,贝叶斯估计的问题理解为:利用观测到的信息Yk,求解系统状态的概率分布
图1 动态状态空间模型(DSSM) 这样,贝叶斯估计的问题理解为:利用观测到的信息Yk,求解系统状态的概率分布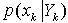 。若系统状态的变化是隐马尔柯夫过程,即当前系统的状态信息只与上一个时刻的状态有关,可以通过预测和更新的途径求解。
。若系统状态的变化是隐马尔柯夫过程,即当前系统的状态信息只与上一个时刻的状态有关,可以通过预测和更新的途径求解。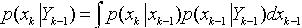 (3)这里:
(3)这里: 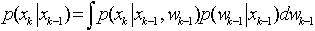 (4) 假设xk,wk是相互独立的随机变量,满足。于是,(1)式可以把(4)式写为
(4) 假设xk,wk是相互独立的随机变量,满足。于是,(1)式可以把(4)式写为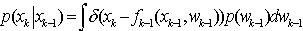 (5) 其中,
(5) 其中,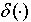 是采样函数。当
是采样函数。当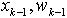 是已知时,xk可以通过确定性方程(1)得到。 依据贝叶斯准则,系统状态估计量
是已知时,xk可以通过确定性方程(1)得到。 依据贝叶斯准则,系统状态估计量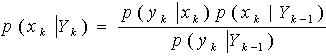 (6) 其中,
(6) 其中,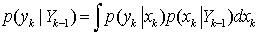 (7) 另外,在给定 xk,vk,分布的条件下, yk的条件概率依据测量方程(2)可以表示为如下形式
(7) 另外,在给定 xk,vk,分布的条件下, yk的条件概率依据测量方程(2)可以表示为如下形式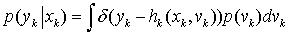 (8) 由(6)式可以看出,后验概率密度包含3个部分。先验概率
(8) 由(6)式可以看出,后验概率密度包含3个部分。先验概率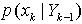 似然函数
似然函数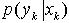 和证据
和证据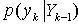 。如何获得这三项的近似是贝叶斯滤波的核心问题。更新方程(5)中观测值 用来对 的先验预测值修正,从而获得状态 的后验概率。方程(3)和(6)的递归关系构成了求解贝叶斯估计问题的两个步骤:预测与更新。如果(1),(2)中的hk,fk是线性的,且噪声wk,vk满足高斯白噪声,可以把贝叶斯估计问题简化为卡尔曼分析解。但这类问题仅仅是实际问题中很小的一个部分。对于更多的问题,很难得到分析解。只有通过对问题的近似线性处理(扩展卡尔曼滤波)或其它途径(蒙特卡洛方法)实现非线性、非高斯问题的解。依据后面分析问题需要,这里重点对蒙特卡洛方法积分进行说明。
。如何获得这三项的近似是贝叶斯滤波的核心问题。更新方程(5)中观测值 用来对 的先验预测值修正,从而获得状态 的后验概率。方程(3)和(6)的递归关系构成了求解贝叶斯估计问题的两个步骤:预测与更新。如果(1),(2)中的hk,fk是线性的,且噪声wk,vk满足高斯白噪声,可以把贝叶斯估计问题简化为卡尔曼分析解。但这类问题仅仅是实际问题中很小的一个部分。对于更多的问题,很难得到分析解。只有通过对问题的近似线性处理(扩展卡尔曼滤波)或其它途径(蒙特卡洛方法)实现非线性、非高斯问题的解。依据后面分析问题需要,这里重点对蒙特卡洛方法积分进行说明。3 蒙特卡洛方法
在过去的二十多年,蒙特卡洛方法得到了很大的。其优点就是用系列满足条件的采样点及其权重来表示后验概率密度。蒙特卡洛方法采用统计抽样和估计对数学问题进行求解。按照其用途,可以把蒙特卡洛方法分为三类[5]:蒙特卡洛抽样、计算、优化。其中,蒙特卡洛抽样是寻找有效的、方差很小的、用于估计的抽样方法。蒙特卡洛计算则是设计产生满足特定要求随机数的随机发生器的问题。而蒙特卡洛优化是采用蒙特卡洛思想对实际中的非凸非差分函数优化求解。对于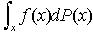 ,可以由概率空间p(x)中抽取N个样本
,可以由概率空间p(x)中抽取N个样本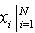 ,用近似值
,用近似值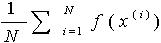 作为
作为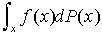 的解。大数定理证明:
的解。大数定理证明: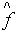 收敛于
收敛于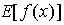 ,并且满足条件
,并且满足条件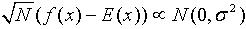 。这里,
。这里,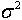 是
是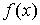 的方差。不同于确定性的数字计算,蒙特卡洛近似的一个重要特点就是估计的精度独立于状态空间的维数。而且,积分估计的方差与采样点的个数成反比。显然,蒙特卡洛近似方法的关键点有两个:首先如何由一个样本空间中抽取N个采样点,用来表征后验概率密度。其次就是计算
的方差。不同于确定性的数字计算,蒙特卡洛近似的一个重要特点就是估计的精度独立于状态空间的维数。而且,积分估计的方差与采样点的个数成反比。显然,蒙特卡洛近似方法的关键点有两个:首先如何由一个样本空间中抽取N个采样点,用来表征后验概率密度。其次就是计算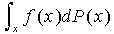 。 重要性抽样(Important Sampling)解决了如何借助于已知分布来对实现有效采样的问题,由Marshall 1965年提出。当数据空间十分巨大时,重要性抽样只对其中“重要”区域进行采样,节省了计算量。对于高维采样空间模型,如统计物、贝叶斯统计量,这一点尤为重要。重要性抽样的中心思想是选择一个覆盖真实分布p(x)的建议分布q(x)[8]。这样,
。 重要性抽样(Important Sampling)解决了如何借助于已知分布来对实现有效采样的问题,由Marshall 1965年提出。当数据空间十分巨大时,重要性抽样只对其中“重要”区域进行采样,节省了计算量。对于高维采样空间模型,如统计物、贝叶斯统计量,这一点尤为重要。重要性抽样的中心思想是选择一个覆盖真实分布p(x)的建议分布q(x)[8]。这样,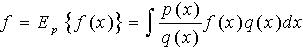 (9)对q(x)作蒙特卡洛抽样,假设粒子数目为N,有
(9)对q(x)作蒙特卡洛抽样,假设粒子数目为N,有
 (10)其中,
(10)其中, 称为重要性权重,再作归一处理,
称为重要性权重,再作归一处理, (11)是归一化权重。为了减小估计的方差,选择的建议性分布q(x)与p(x)尽可能匹配。通常,建议分布q(x)需要一个长的拖尾,这样可以解决区间之外的干扰。确切的说,匹配的q(x)必须与p(x)f(x)成正比[9]。当q(x)与p(x)不匹配时,w(x(i))是不均匀分布的,在整个递归迭代的过程中,存在大量的权值极小的样本,而这些样本对估计的贡献很小。事实上,权值较大的少数样本决定蒙特卡洛采样的估计精度。大量时间损耗在这些“无关紧要”的粒子计算上,即所谓的粒子退化现象(Degeneracy Problem)。目前,标准的粒子滤波器选择先验概率(Prior)作为建议分布。 对于粒子退化现象,采样—重要性重采样方法给出了很好的解决途径。其基本思想就是通过在两次重要性采样之间增加重采样步骤,消除权值较小的样本,并对权值较大的样本复制,降低了计算的复杂度。在o(N)时间复杂度范围内可以已排序的均匀分布序列作重采样处理。 对
(11)是归一化权重。为了减小估计的方差,选择的建议性分布q(x)与p(x)尽可能匹配。通常,建议分布q(x)需要一个长的拖尾,这样可以解决区间之外的干扰。确切的说,匹配的q(x)必须与p(x)f(x)成正比[9]。当q(x)与p(x)不匹配时,w(x(i))是不均匀分布的,在整个递归迭代的过程中,存在大量的权值极小的样本,而这些样本对估计的贡献很小。事实上,权值较大的少数样本决定蒙特卡洛采样的估计精度。大量时间损耗在这些“无关紧要”的粒子计算上,即所谓的粒子退化现象(Degeneracy Problem)。目前,标准的粒子滤波器选择先验概率(Prior)作为建议分布。 对于粒子退化现象,采样—重要性重采样方法给出了很好的解决途径。其基本思想就是通过在两次重要性采样之间增加重采样步骤,消除权值较小的样本,并对权值较大的样本复制,降低了计算的复杂度。在o(N)时间复杂度范围内可以已排序的均匀分布序列作重采样处理。 对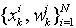 重采样(Resampling)处理,新的采样结果放在数组
重采样(Resampling)处理,新的采样结果放在数组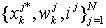 ,具体的算法用伪码语言写为如下的形式: 步骤1:令
,具体的算法用伪码语言写为如下的形式: 步骤1:令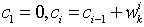 这里必须注意
这里必须注意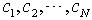 是随机变量的累计概率密度序列。 步骤2:初始假设
是随机变量的累计概率密度序列。 步骤2:初始假设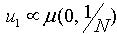 ,当
,当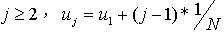 , 产生一组序列分布。对一个固定的j,分别用
, 产生一组序列分布。对一个固定的j,分别用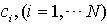 逐一比较,一旦
逐一比较,一旦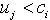 ,就可以得到一组新的样本集合
,就可以得到一组新的样本集合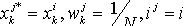 。如此循环直到
。如此循环直到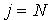 。需要说明的是,重采样方法在消除粒子退化问题的同时,也带来了其它两个问题:首先,降低了粒子运算并行执行的可能性;其次,由于权值较大的粒子多次被选择,粒子的多样性减少。这种情况尤其在小过程噪声条件下表现更为明显[11]。
。需要说明的是,重采样方法在消除粒子退化问题的同时,也带来了其它两个问题:首先,降低了粒子运算并行执行的可能性;其次,由于权值较大的粒子多次被选择,粒子的多样性减少。这种情况尤其在小过程噪声条件下表现更为明显[11]。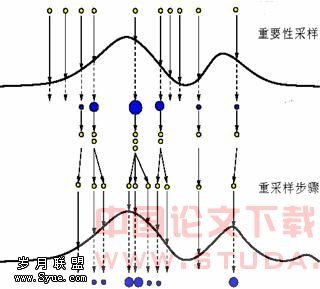 图2 SIR-PF重要性采样与重采样示意图
图2 SIR-PF重要性采样与重采样示意图4 GMSPPF滤波算法
如前所述,利用序列重要性采样和重采样的方法,粒子滤波可以有效的递归更新后验概率的分布。但是,由于对粒子未加假设,大量的粒子在处理非线性、非高斯问题时出现了计算的高复杂性问题。另外,由于少数权值较大的粒子反复被选择,粒子坍塌明显。[4]提出了在重要性采样步骤的建议分布的生成阶段“搬运”粒子到似然较高区域,可以缓解坍塌,同时提高估计的性能。但是不可避免的是对每一个粒子的后验概率处理,使得计算的复杂性进一步加剧。鉴于此种情况,这里介绍一种新颖的高斯混合采样粒子滤波器(Gaussian Mixture Sigma Point Particle Filter,GMSPPF)。GMSPPF算法利用有限高斯混合模型表征后验概率分布情况,可以通过基于重要性采样的加权的后验粒子,借助于加权的期望最大化算法(Weighted Expection Maximization)替换标准重采样步骤,降低粒子坍塌效应。4.1 基于高斯混合近似的采样卡尔曼滤波器
根据最优滤波理论,一个概率密度p(x)都可以写作高斯混合模型(Gaussian Mixture Model)。即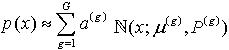 ,这里,G是高斯分量的个数,
,这里,G是高斯分量的个数,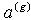 是高斯分量的权重,
是高斯分量的权重,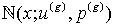 是以向量
是以向量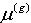 为均值,以p(g)为协方差矩阵的随机向量x的高斯分布。 考虑DSS状态转移方程和观测方程,假设先验概率
为均值,以p(g)为协方差矩阵的随机向量x的高斯分布。 考虑DSS状态转移方程和观测方程,假设先验概率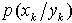 及噪声密度
及噪声密度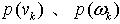 服从高斯混合模型(GMM)。这样,预测的先验概率密度
服从高斯混合模型(GMM)。这样,预测的先验概率密度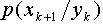 满足
满足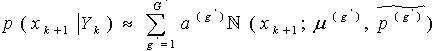 ,更新后
,更新后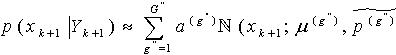 。这里,
。这里,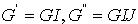 。在此基础之上,预测的先验概率
。在此基础之上,预测的先验概率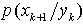 和后验概率
和后验概率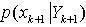 对应的均值和方差可以通过采样卡尔曼滤波器(Sigma Point KF)。
对应的均值和方差可以通过采样卡尔曼滤波器(Sigma Point KF)。4.2 基于观测更新的重要性采样(Important Sampling)
前已叙及重要性抽样是一种蒙特卡洛方法,即用一组带有权值的样本数据来表征随机变量的概率密度。利用DSS模型的一阶马尔柯夫本质和给定状态的观测值依赖性,可以推导递归的权值更新方程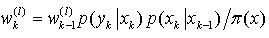 ,这里仅对于给定的粒子
,这里仅对于给定的粒子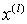 而言。在GMSPPF算法中,用GMM近似
而言。在GMSPPF算法中,用GMM近似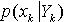 来。作为建议分布
来。作为建议分布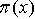 。由于
。由于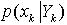 包含了最新的样本数据,使得粒子聚集在高似然区域,一定程度减少了粒子坍塌效应。另外,使用预测的先验概率
包含了最新的样本数据,使得粒子聚集在高似然区域,一定程度减少了粒子坍塌效应。另外,使用预测的先验概率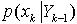 平滑权值更新方程中的
平滑权值更新方程中的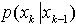 ,这是因为GMSPPF算法用GMM表示后验概率,本次后验同时又是下一个时间步的先验概率,GMM模型中高斯核对后验概率做了平滑处理。基于观测更新步骤的重要性采样方法中对粒子不作任何假设,对非线性、非高斯问题具有很强的鲁棒性。
,这是因为GMSPPF算法用GMM表示后验概率,本次后验同时又是下一个时间步的先验概率,GMM模型中高斯核对后验概率做了平滑处理。基于观测更新步骤的重要性采样方法中对粒子不作任何假设,对非线性、非高斯问题具有很强的鲁棒性。4.3 采用加权的EM算法做重采样和GMM还原
基于观测更新步骤的重要性采样输出是一组加权的粒子,在标准的粒子滤波器中,这些粒子必须作重采样处理丢弃小权值粒子,同时对权值较大的粒子做放大处理。通过这种处理,可以有效的防止粒子集合的方差增加太快。不幸的是,重采样步骤只对当观测似然微弱、大量粒子聚集极少数粒子副本情况有效。在GMSPPF算法中,采用加权的期望最大(Weighted Expection Maximization)直接得到GMM模型,实现对加权粒子的最大似然拟合,这就相当于对粒子的后验概率做了平滑,避免了粒子坍塌问题,同时,GMM模型中的高斯核的个数减少到G,防止其呈指数级增长,降低了算法复杂度。 为了比较算法的性能,系统状态估计的条件均值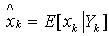 ,均方误差(Error Convariane)
,均方误差(Error Convariane)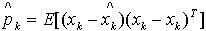 可以通过两个方法计算,即在加权的EM算法平滑之前,用下面公式
可以通过两个方法计算,即在加权的EM算法平滑之前,用下面公式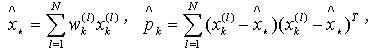
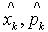 描述了系统的均值与均方误差性能。
描述了系统的均值与均方误差性能。5 算法性能分析与结论
这里,给定系统状态估计问题的算法评估模型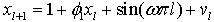 (12)
(12)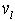 是
是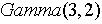 噪声,
噪声,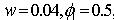 。另外,非平稳观测模型
。另外,非平稳观测模型 (13)
(13) ,其中,观测噪声
,其中,观测噪声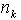 服从高斯分布
服从高斯分布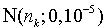 。如果给定含噪的系统状态观测值yk,采用两种不同的算法:标准的粒子滤波算法SIR-PF以及GMSPPF算法对系统的状态xk估计。每次实验共做150次,每次的观察样本重新产生,SIR-PF算法中粒子的个数是250个。GMSPPF算法中采用两种方案:第一种方案用5个高斯核拟合状态后验概率。状态噪声vk,观测噪声nk各用一个高斯核拟合。第二种方案则用3个高斯核拟合Gamma(3,2)分布的拖尾状态噪声,这里拟合方法采用EM算法。图3、图4描述了系统的隐状态和观测值及SIR-PF,GMSPPF算法系统状态的估计值。
。如果给定含噪的系统状态观测值yk,采用两种不同的算法:标准的粒子滤波算法SIR-PF以及GMSPPF算法对系统的状态xk估计。每次实验共做150次,每次的观察样本重新产生,SIR-PF算法中粒子的个数是250个。GMSPPF算法中采用两种方案:第一种方案用5个高斯核拟合状态后验概率。状态噪声vk,观测噪声nk各用一个高斯核拟合。第二种方案则用3个高斯核拟合Gamma(3,2)分布的拖尾状态噪声,这里拟合方法采用EM算法。图3、图4描述了系统的隐状态和观测值及SIR-PF,GMSPPF算法系统状态的估计值。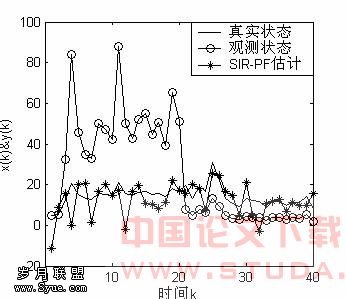 图3 SIR-PF粒子滤波器状态估计
图3 SIR-PF粒子滤波器状态估计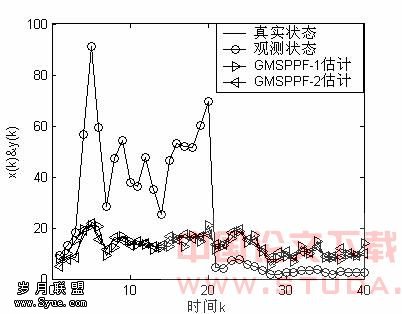 图4 GMSPPF粒子滤波器状态估计 采用4.3部分的均方误差和均值计算公式对不同算法对系统状态估计性能作了比对。图3、图4曲线表明,在系统的观测噪声nk均方误差很小,而过程噪声服从具有长的拖尾 分布时,采用转移概率
图4 GMSPPF粒子滤波器状态估计 采用4.3部分的均方误差和均值计算公式对不同算法对系统状态估计性能作了比对。图3、图4曲线表明,在系统的观测噪声nk均方误差很小,而过程噪声服从具有长的拖尾 分布时,采用转移概率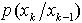 作为建议分布的标准粒子滤波器性能很差。这是因为观测方程中峰值似然函数和系统状态急剧的跳跃变化产生的结果。尽管可以通过采样卡尔曼(Sigma-Point)滤波器将粒子向似然峰值区域搬动解决这一问题,但是也使得计算量加大。GMSPPF算法两种不同方案都具有比SIR-PF更好的系统状态估计性能,均方误差比后者数量级降低了1/103-1/104。与1个高斯核拟合过程噪声的GMSPPF算法比较,3个高斯核拟合算法性能更好,但时间复杂度同样有所提高。 由于GMSPPF算法在大幅度降低了算法的计算复杂度同时,可以获得精确的系统估计性能。所以说,GMSPPF算法为粒子滤波理论实时应用,如目标定位(单目标与多目标)、时变信道估计、图像增强、机器故障诊断以及语音信号处理等提供了一个新的方案。[1] Y.C.Ho and R.C.K.Lee,”A Bayesian approach to problems in stochastic estimation and control”IEEE Trans.Automat.contr. vol .AC-9.pp.333-339[2]A.Doucet,N.Freitas,N.Gordon. Sequential Monte Carlo Methods in Practice [M].Springer[3]B.D.O. Anderson and J.B.Moore .Optimal filtering . [M]Prentice Hall Englowcod Cliffo,NJ. 1979[4]N.J.Gordon,D.J.Salmond,A.F.M.Smith,Novel approach to nonlinear/non-Gaussian Bayesian state estimation,IEE proceedings vol140,No2,April 1993[5]MULLER,“Monte Carlo integration in general dynamic Models“ Contemp .Math.1991,115,pp,145-163[6]Fredric Gustafsson,Niclas Bergman,”Particle filters for Position,Navigation and Tracking “,Final version for IEEE Transactions on Signal Processing Special issue on Monte Carlo methods for statistical signal[7]ARNAUD DOUCET,SIMON GODSILL,”On sequential Monte Carlo sampling method for Bayesian filtering “statistics and Computing(2000),10,197-208,recived July 1998 and accepted August 1999[8] Jayesh H.Kotecha and Petar M.Djurric,”Gaussian Particle Filtering ”In Proc. Workshop Statistical Signal Process.Singapore,Aug.2001[9]J.S.Liu&R.Chen.”Sequential Monte Carlo Methods for Dynamical Systems”.Journal of the Amerian StatisticalAssociation,1998,Volume 93.pp.1032-1044[10] ZHE CHEN,”Bayesian filtering:From Kalman filter to particle filters,And Beyond” Manuscript In 2003,April[11] Jayesh H.Kotecha and Petar M.Djurric,”Gaussian Sum Particle Filtering ” IEEE Transactions On signal Processing,2003,Vol.51.No.10.October[12]M.Sanjeev Arulampalam,Simon Maskell,Neil Gordon,and Tim Clapp,”A Tutorial on Particle Filteolinear/Non- Gaussian Bayesian Tracking”,IEEE transaction on signal processing,Vol,50,No 2February 2002
作为建议分布的标准粒子滤波器性能很差。这是因为观测方程中峰值似然函数和系统状态急剧的跳跃变化产生的结果。尽管可以通过采样卡尔曼(Sigma-Point)滤波器将粒子向似然峰值区域搬动解决这一问题,但是也使得计算量加大。GMSPPF算法两种不同方案都具有比SIR-PF更好的系统状态估计性能,均方误差比后者数量级降低了1/103-1/104。与1个高斯核拟合过程噪声的GMSPPF算法比较,3个高斯核拟合算法性能更好,但时间复杂度同样有所提高。 由于GMSPPF算法在大幅度降低了算法的计算复杂度同时,可以获得精确的系统估计性能。所以说,GMSPPF算法为粒子滤波理论实时应用,如目标定位(单目标与多目标)、时变信道估计、图像增强、机器故障诊断以及语音信号处理等提供了一个新的方案。[1] Y.C.Ho and R.C.K.Lee,”A Bayesian approach to problems in stochastic estimation and control”IEEE Trans.Automat.contr. vol .AC-9.pp.333-339[2]A.Doucet,N.Freitas,N.Gordon. Sequential Monte Carlo Methods in Practice [M].Springer[3]B.D.O. Anderson and J.B.Moore .Optimal filtering . [M]Prentice Hall Englowcod Cliffo,NJ. 1979[4]N.J.Gordon,D.J.Salmond,A.F.M.Smith,Novel approach to nonlinear/non-Gaussian Bayesian state estimation,IEE proceedings vol140,No2,April 1993[5]MULLER,“Monte Carlo integration in general dynamic Models“ Contemp .Math.1991,115,pp,145-163[6]Fredric Gustafsson,Niclas Bergman,”Particle filters for Position,Navigation and Tracking “,Final version for IEEE Transactions on Signal Processing Special issue on Monte Carlo methods for statistical signal[7]ARNAUD DOUCET,SIMON GODSILL,”On sequential Monte Carlo sampling method for Bayesian filtering “statistics and Computing(2000),10,197-208,recived July 1998 and accepted August 1999[8] Jayesh H.Kotecha and Petar M.Djurric,”Gaussian Particle Filtering ”In Proc. Workshop Statistical Signal Process.Singapore,Aug.2001[9]J.S.Liu&R.Chen.”Sequential Monte Carlo Methods for Dynamical Systems”.Journal of the Amerian StatisticalAssociation,1998,Volume 93.pp.1032-1044[10] ZHE CHEN,”Bayesian filtering:From Kalman filter to particle filters,And Beyond” Manuscript In 2003,April[11] Jayesh H.Kotecha and Petar M.Djurric,”Gaussian Sum Particle Filtering ” IEEE Transactions On signal Processing,2003,Vol.51.No.10.October[12]M.Sanjeev Arulampalam,Simon Maskell,Neil Gordon,and Tim Clapp,”A Tutorial on Particle Filteolinear/Non- Gaussian Bayesian Tracking”,IEEE transaction on signal processing,Vol,50,No 2February 2002
上一篇:统计数据质量控制问题研究
下一篇:中国性别平等与妇女发展评估报告