�����IJ������
�����ؼ��ʣ����С�DAG���������������г����л���ģ�͡��ȼ۹�ϵ
��������ժҪ�� Ŀǰ�ڲ��м����о������кܴ�һ���ֹ����ǽ����г����л������ĸ�����Ŀ��Ҫ���ں����ļ����£����ȷ����г����д��ڵIJ����ԣ�һ���õķ������ǹ������Ӧ�IJ�������DAG��ͼ�����ķ����˴��г����д��ڵ�����������ϵ�����Դ�Ϊ���ݣ������һ�������еĴ��г������Ӧ�IJ�������DAG��ͼ���㷨��Ȼ���ٶ�ʣ�µĴ��г���ֶΣ�������л���ģ�ͣ���������ģ�������һ�ֲ��л����㷨PDMA�������ݳ���ε���س̶������һ�ֶ�PDMA���иĽ��IJ��л����㷨RPDMA��Ȼ����ͨ��һ�����Գ����ʵ�������ô˷�������������㣬���Դ��г��������µ�ʱ�临�ӶȺͽ��д˷��������µ�ʱ�临�ӶȽ��бȽϣ��ó��˷�������Խ��
����1.���������
�������м����ǽ�һ�����������̯������������ϲ�ͬʱ���еļ��㷽�������ڵ���CPU�������ٶ�����������ߣ����Լ������������ͼ�����CPU��������ʹ�á��ڼ���������Ѳ���ר�õĶദ������ƣ�̨ʽ�����ʼDZ���������Ҳ�ѹ㷺�ز�����˫�˻���CPU��˫��CPU���ⲿ��������һ��CPU�������ڲ�������������ģ����ǿ��Զ������м��㹤������ͬʱ������������ʱ��˴��������Եؽ���ͬ������������ͬ�ĺ��ġ������ױ����л��ļ��������Ϊ���ײ��С��ģ�������ֱ�۵������ֽ��Ϊ��������IJ��֣���ͬʱִ�м������⡣
����Ҫ��
������1������һ���Գ���Ĵ��д���д�ɵij���ʱ����ν����������ֳɶ�����ֲ��ֽ���������ͬʱ���С�
������2������������Ч��ģ�ͣ�������ģ�Ͷ��ֳɵĴ����㷨���д��������ܹ�ʹ��˫���IJ��д����IJ��ַֽ�������䵽����������ͬʱ���С����ڴﵽ�ȵ���CPU���������ٵ�Ŀ�ġ�
����2.ģ�͵ļ���
����1.����Ӳ�����������أ�����ÿ��ִ��ʱӲ�������ͻ�����������ȫһ�µġ�
����2.���㷨��ʱ�临�ӶȲ��������侫ȷ����,��ֻ�ǹ���������
����3.˫�˼����CPU������ʱ,��������.
����4.�����е��㷨���յõ���DAGͼ��������ԭ�еķ��������������.
����3.�������
�������ڵ���CPU�������ٶ�����������ߣ��������ڹ㷺������˫�˻���CPU,��ν�һ������Ĵ��г���ֽ�������֣�ʹ֮�ܹ�ͬʱ������˫�˻���CPU��˫��CUP�ڲ�������������Ŀ��Զ������й���������ϣ���ܹ���ַ���˫���ĵļ����������������Ǹ�������֮����ڵ����������Լ�����������ϵ�����ȷ����г����д��ڵIJ����ԣ��Ӷ�������ֱ�ӽ����г����л��ĸ��Ӷȣ�Ҳ�����Ч�ʡ�Ȼ�������ʣ�µĴ��г�����в��л��������Ӷ�ʹ����Ч�ʴﵽ�������״̬��
�������ڵ������ǣ�
��������������ҵ�һ���õķ���ȥ�����г����еĴ��ڵIJ����ԣ�
�������������һ�ֽ����г����л��ֵ�ģ�ͣ��ٻ������ģ�����һ�ֲ��л����㷨��
����4.��ģǰ����
����4.1����һ������Ĵ��г���, �������ȷ����г����д��ڵIJ����Թ������Ӧ�IJ�������DAGͼ. ����DAGͼ��ʱ��, ��Ҫ��һ��������Ƿ�������֮���������ϵ. �������ȶ�����֮����ڵ�һ��������ϵ��һ���Ľ���.
����1.����֮�������������ϵ
������ν��������, Ҳ���������еĶ��ִ�й���ͬʱ������ͬ������, ������֪ʶ�����������������ص���ʽ������:

�������������г��������У�������Ҳ��Ϊ�������������ʵ��������֮�����ͨ���̣���������������������������û�а취��������������в��л�ı����������ִ��˳��ġ����������������Ҳ����������ػ��ͻ������ʵ���ϲ�û���κ���ʵ���������Ĺ�ϵ��ֻ����Ҫʹ��һ���洢��Դ�Ĺ����У����ڱ��������ʹ�ö���ɵģ���ʵ����Ҳ����Դ������ͨ���ظ�������Դ����ʹ����������Դ������Խ����Щ����������Ӱ�첢���ԵĿ�����
����4.2�㷨ʱ�临�Ӷȶ���
�������壺���һ������Ĺ�ģ��n������һ�����ijһ�㷨����Ҫ��ʱ��ΪT(n)������n��ijһ���� T(n)��Ϊ��һ�㷨�ġ�ʱ�临���ԡ���
��������Temp=I��
����i=j;
����j=temp;
��������������������Ƶ�Ⱦ�Ϊ1���ó���ε�ִ��ʱ����һ���������ģn�صij������㷨��ʱ�临�Ӷ�Ϊ�����ף�����T(n)=O(1)������㷨��ִ��ʱ�䲻���������ģn�����Ӷ���������ʹ�㷨������ǧ����䣬��ִ��ʱ��Ҳ������һ���ϴ�ij����������㷨��ʱ�临�Ӷ���O(1)���㷨��ʱ�临�Ӷȷ�ӳ�˳���ִ��ʱ���������ģ�������������������ںܴ�̶����ܺܺ÷�ӳ���㷨���������
������ʵ��Ӧ���У�����һ�㶼��ʹ�ý���ʱ�临�Ӷȴ���ʵ��ʱ�临�Ӷ��������㷨Ч�ʷ�����
����5.ģ�͵Ľ��������
�������ȹ���DAGͼ�����г����д��ڵIJ�����.Ȼ���ʣ��Ĵ��г������������л���ģ��,�������ģ�������һ�ֲ��л����㷨PDMA����Ľ��˵IJ��л����㷨RPDMA.���,ͨ������˷�����ʱ�临�ӶȺʹ��������µ�ʱ�临�Ӷ�,���бȽ�,�ó��˴˷����Ŀ�����.
����5.1�������г����еĴ��ڵIJ�����
������η����г����д��ڵIJ����ԣ�һ���õķ������ǹ������Ӧ�IJ�������(DAG)ͼ�����ķ����˴��г����д��ڵ�������ϵ�����Դ�Ϊ���ݣ������һ�������еĴ��г�����ߴ��н�����������Ӧ�IJ�����������������(DAG)ͼ���㷨��
�����㷨������
�����Ը���������![]() ��
��![]() (x)�������²�����������DAGͼ��
(x)�������²�����������DAGͼ��
��������1 ���![]() û�ж��壬����һ�����Ϊ
û�ж��壬����һ�����Ϊ![]() ��Ҷ�ڵ㣬������
��Ҷ�ڵ㣬������![]() Ϊ���Ҷ�ڵ㡣
Ϊ���Ҷ�ڵ㡣
�������![]() ����ת����2.1
����ת����2.1
���������![]() ���û�ж���,����һ�����Ϊ
���û�ж���,����һ�����Ϊ![]() ��Ҷ�ӽڵ㣬ͬʱ����
��Ҷ�ӽڵ㣬ͬʱ����![]() Ϊ����ڵ㣬ת����2.2
Ϊ����ڵ㣬ת����2.2
��������2
��������2.1 ���![]() ʵ���Ϊ������Ҷ�ӽڵ�,��ת����2.3,����ת����3.2��
ʵ���Ϊ������Ҷ�ӽڵ�,��ת����2.3,����ת����3.2��
�������裲.2 ���![]() ���DZ��г����Ľڵ�,��ת����2.4,����ת����3.2��
���DZ��г����Ľڵ�,��ת����2.4,����ת����3.2��
��������2.3 ��![]() ִ��T,�õ��µij������ݼ�P.���NODE(
ִ��T,�õ��µij������ݼ�P.���NODE(![]() )�Ǵ�����ǰDAGͼ�¹�ѡ�����Ľڵ�,��ɾ���������NODE(p)û�ж���,����һ����p����ǵ�Ҷ�ڵ����n��������NODE(p)ָ������ת����4��
)�Ǵ�����ǰDAGͼ�¹�ѡ�����Ľڵ�,��ɾ���������NODE(p)û�ж���,����һ����p����ǵ�Ҷ�ڵ����n��������NODE(p)ָ������ת����4��
��������2.4 ��{![]() }ִ��T,�õ��µij���p�����NODE��
}ִ��T,�õ��µij���p�����NODE��![]() ����
����![]() =1,2,
=1,2,![]() n���Ǵ���DAGͼ�¹�������Ľڵ�,��ɾ���������NODE��p��û�ж���,����һ����p����ǵ�Ҷ�ڵ����n��������NODE(p)ָ������ת����4��
n���Ǵ���DAGͼ�¹�������Ľڵ�,��ɾ���������NODE��p��û�ж���,����һ����p����ǵ�Ҷ�ڵ����n��������NODE(p)ָ������ת����4��
��������3
��������3.1 ���DAGͼ�Ƿ�����һ���ڵ㣬��Ψһ��ǰ��ΪNODE��![]() ��������Ϊ�ԣ����û�У�����ýڵ����n��ת����4��
��������Ϊ�ԣ����û�У�����ýڵ����n��ת����4��
��������3.�������DAGͼ�Ƿ�����һ���ڵ㣬��ǰ�̷ֱ�ΪNODE��![]() ����NODE��
����NODE��![]() �� NODE��
�� NODE��![]() ��������Ϊ�ԣ����û�У�����ýڵ����n��ת����4��
��������Ϊ�ԣ����û�У�����ýڵ����n��ת����4��
�������裴�����NODE(x)û�ж���,���x���ӵ��ڵ�n�ϣ�����NODE(x)=n;�����Ȱ�n��NODE(x)=n��ת��������һ������ֱ���������е��������ﴦ����������ת���裵��
�������裵����ͼ��û�б������Ľڵ�ɾ���������������DAGͼ��
����5.2�����г���Ľ�һ�����л���:
����1���л���ģ��

��������![]() ��Ҳ����˵
��Ҳ����˵![]() ��N��Ԫ�أ�����
��N��Ԫ�أ�����![]() �е�ÿһ��P���Ӽ�
�е�ÿһ��P���Ӽ�![]() ����
����![]() �еij����ȫ������һ̨�����������У�����
�еij����ȫ������һ̨�����������У�����![]() �Ķ���֪��ÿ��̨��������ִ�еij���ζ�����������ԣ������ڳ������еĹ����У�����Ҫ�κε���Ϣ���ݺ���ȴ���һֱ�������������ϵij����ִ����ϣ�����a��֤�˳����е��κ�һ������β��ᱻִ�ж���һ�Σ�����b��֤�˳�����ÿһ������ζ����Ա�ִ�У�
�Ķ���֪��ÿ��̨��������ִ�еij���ζ�����������ԣ������ڳ������еĹ����У�����Ҫ�κε���Ϣ���ݺ���ȴ���һֱ�������������ϵij����ִ����ϣ�����a��֤�˳����е��κ�һ������β��ᱻִ�ж���һ�Σ�����b��֤�˳�����ÿһ������ζ����Ա�ִ�У�
����2���л����㷨PDMA����س̶�
�����������������IJ��л���ģ�ͣ�����д�������ģ�͵��㷨PDMA��PDMA��������һ�����г���G������Dz��л���ģ��![]() ���ȸ����㷨����ʹ�õķ��ŵĶ��壬PΪ����μ�������ÿ��Ԫ��
���ȸ����㷨����ʹ�õķ��ŵĶ��壬PΪ����μ�������ÿ��Ԫ��![]() Ϊ���е�һ�д��룻RΪP�ϵĹ�ϵ
Ϊ���е�һ�д��룻RΪP�ϵĹ�ϵ![]() ��ֵ���㷨�������£�
��ֵ���㷨�������£�
����a����G����P��{L1��L2������L}��
����b������R={(A��B)| A��B��P��A![]() B}��
B}��
����c����![]()
����d��ȡR��һ����Ԫ��r=(A��B)����R��=R-{r}����A![]() ����B
����B![]() ������
������![]() ��=
��=![]() U{A��B}(
U{A��B}(![]() )��������
)��������![]() ��=
��= ![]() U{{A��B}}��
U{{A��B}}��
����ʵ���ϣ�������Ĵ��г�������㷨PDMA�����������IJ��л���ģ��![]() �Ļ�Ϊ1��Ҳ����˵����������г����ܱ����ֳɶ��������صij���Σ�
�Ļ�Ϊ1��Ҳ����˵����������г����ܱ����ֳɶ��������صij���Σ�
��������3 ����ε���س̶�![]() ����B
����B![]() AΪ�棬��V(B
AΪ�棬��V(B![]() AΪ1������Ϊ0��
AΪ1������Ϊ0��
����3���ڽ�����س̶ȵIJ��л����㷨RPDMA
����ʵ���ϣ����г����и�������֮�����������ԣ�Ҳ����˵�����г���G��ͨ���㷨PDMA�����IJ��л���ģ![]() ��
��![]() ��������٣������Ժ�����صػ��ֵ�����������ϲ���ִ�еĴ��г�����ٻ��֮�����һ��������ԣ���Ȼ��������ʹ�ø����ֻ�֮�����س̶Ƚ��ͣ���ô�������еļ��ٱȾͻ���ߣ���ˣ����зֻ�������ת��Ϊ����ν�һ�����ϻ���Ϊ�����ֻ���ʹ����Щ�ֻ��֮�����������١������ڴˣ������һ��������س̶ȵIJ��л����㷨RPDMA��RPDMA����Ҫ˼·�ǰѻ��ֺ�ij����֮�����س̶�ת����Ϊ�����ڵ�֮���ͨ�ţ���ͨ���Dz��д�����ƿ��RPDMA��Ŀ���Ǿ����������ڵ�֮���ͨ������RPDMA���㷨PDMA�����Ļ�Ϊ1�IJ��л���ģ��
��������٣������Ժ�����صػ��ֵ�����������ϲ���ִ�еĴ��г�����ٻ��֮�����һ��������ԣ���Ȼ��������ʹ�ø����ֻ�֮�����س̶Ƚ��ͣ���ô�������еļ��ٱȾͻ���ߣ���ˣ����зֻ�������ת��Ϊ����ν�һ�����ϻ���Ϊ�����ֻ���ʹ����Щ�ֻ��֮�����������١������ڴˣ������һ��������س̶ȵIJ��л����㷨RPDMA��RPDMA����Ҫ˼·�ǰѻ��ֺ�ij����֮�����س̶�ת����Ϊ�����ڵ�֮���ͨ�ţ���ͨ���Dz��д�����ƿ��RPDMA��Ŀ���Ǿ����������ڵ�֮���ͨ������RPDMA���㷨PDMA�����Ļ�Ϊ1�IJ��л���ģ��![]() ����һ���Ļ��֣������ݳ���εĺ��Լ������֮������������һ����ȨͼTEMP��ͼ�Ľڵ��dz���Σ�ͼ�������AB��Ȩ�dz����A��B֮�����س̶ȣ�RPDMA�����ҵ�TEMP��Ȩ��С�ı�mv��Ȼ����ÿһ���ߵ�Ȩ����ȥmv��Ȩ��Ҳ������ؽڵ�֮���ͨ��������mv�������������ͼ�Ƿ���ͨͼ����������г�����Ի���Ϊ�������������ϵĴ���һ������Ե��ӳ��������ͼ����ͨͼ����ô�ٰ��������ķ������л��֣�ֱ����������ͼΪ����ͨͼ��RPDMA������Ϊ���г���G�����Ϊ���л���ģ��
����һ���Ļ��֣������ݳ���εĺ��Լ������֮������������һ����ȨͼTEMP��ͼ�Ľڵ��dz���Σ�ͼ�������AB��Ȩ�dz����A��B֮�����س̶ȣ�RPDMA�����ҵ�TEMP��Ȩ��С�ı�mv��Ȼ����ÿһ���ߵ�Ȩ����ȥmv��Ȩ��Ҳ������ؽڵ�֮���ͨ��������mv�������������ͼ�Ƿ���ͨͼ����������г�����Ի���Ϊ�������������ϵĴ���һ������Ե��ӳ��������ͼ����ͨͼ����ô�ٰ��������ķ������л��֣�ֱ����������ͼΪ����ͨͼ��RPDMA������Ϊ���г���G�����Ϊ���л���ģ��![]() ���ȸ����㷨�ķ��Ŷ��壺TEMP,TEMPO��RP��һ�����ϣ�������ÿ��Ԫ����һ����Ԫ��(A��B��v)��A��B��G�ij���Σ�v��A��B����س̶ȣ��㷨�������£�
���ȸ����㷨�ķ��Ŷ��壺TEMP,TEMPO��RP��һ�����ϣ�������ÿ��Ԫ����һ����Ԫ��(A��B��v)��A��B��G�ij���Σ�v��A��B����س̶ȣ��㷨�������£�
����a�������㷨PDMA�������л���ģ��![]() ��
��![]() ���������
���������
����b������TEMP={(A��B��v)|A��B��P��v=![]() }����TEMPO��=TEMP��
}����TEMPO��=TEMP��
����c��ȡmv![]() TEMP��ʹ��
TEMP��ʹ��![]() s��TEMP��s��mv��s mv,s.v>mv.v
s��TEMP��s��mv��s mv,s.v>mv.v
����d����RP��=![]() ��
��
����e��ȡr![]() TEMP����TEMP��TEMP-{r}����r��v��=r��v-mv,��RP��=RP
TEMP����TEMP��TEMP-{r}����r��v��=r��v-mv,��RP��=RP![]() {r}
{r}
����f����TEMP![]() ����תe��
����תe��
����g����![]() ��=
��=![]() ��
��
����h��ȡrp��RP��rp={A��B��v}����RP��=RP-{rp}����A![]() ����B��
����B��![]() ������
������![]() ��=
��=![]() U{A��B}(
U{A��B}( ![]() ��
��![]() )��������
)��������![]() ��=
��= ![]() U{{A��B}}��i����RP
U{{A��B}}��i����RP![]() ����תh��
����תh��
����i����![]() =1������TEMP��={(A��B��v)|(A��B��v+mv.v)
=1������TEMP��={(A��B��v)|(A��B��v+mv.v) ![]() TEMPO}������TEMPO��=TEMP��תc�����������
TEMPO}������TEMPO��=TEMP��תc�����������
����/
����5.3�ڴˣ����Ǹ�����һ�����г����ʵ��:
������![]() ����
����
��L![]() :
: ![]() =5,
=5, ![]() =10,
=10, ![]() =20��������������������
=20��������������������
��![]() ��temp0=
��temp0=![]() +
+![]() +
+ ![]() +10;
+10;
��![]()
![]() ��
��
��![]() �� x=temp0*temp1;
�� x=temp0*temp1;
��![]() �� If x>5 THEN;
�� If x>5 THEN;
��![]() �� x=x*x
�� x=x*x
����ELSE
��![]() �� x=x-1; ������
�� x=x-1; ������
��������������㷨�õ�ͼ����
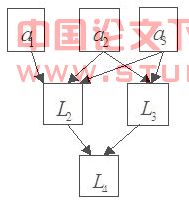 ��
��
ͼ1 ���㷨������϶γ����DAGͼ��

��ͼ2 ɾȥû�б�������Ľ���õ�ͼ��,������������������������������������
![]() :
: ![]() =����,
=����, ![]() =������
=������
![]() :
: ![]() ;
;
![]()
![]() ���������������������������������������������������������������������� ��������������������������������������������������������������������������������������������
���������������������������������������������������������������������� ��������������������������������������������������������������������������������������������
![]() x=temp0*temp1;
x=temp0*temp1;
![]() for(x=x;x<=S;x++)
for(x=x;x<=S;x++)
![]() y=2*x;
y=2*x;
��������������㷨�õ�ͼ3
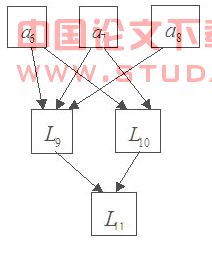
ͼ3 ���㷨������϶γ����DAGͼ
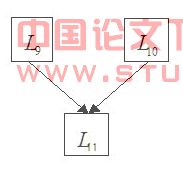
ͼ4ɾȥû�б�������Ľ���õ�ͼ4
����6. ģ�͵ļ���
����ͨ�����ϵĹ��̣����ǿ���ͨ���Ƚ��䴮�г������ºͲ��л����ִ������ʱ�临�Ӷȡ�
����n������Ĵ��г�����������ڹ���DAGͼʱ������Ӧ�ĸ�����ʱ�临�Ӷȶ���O(n);���ں����IJ��л����㷨RPDMA��,�����(L4-L7��L11-L14)��ʱ�临�Ӷ�����:L4.L5.L6.L7.L11.L13ʱ�临�Ӷ���O(1);L12��ʱ�临�Ӷ���O(s);L14��ʱ�临�Ӷ���![]() ����ˣ��������л������㷨�µ�ʱ�临�Ӷ���
����ˣ��������л������㷨�µ�ʱ�临�Ӷ���![]() ��
��
����Ȼ�����ڶԸó���ֱ�ӽ��д��д���ʱ����ʱ�临�Ӷ���![]() ��
��
������ˣ�����Ľ���������ǵķ����������⣬���˲��л��㷨�±ȴ����¹����ĸ��졣
[1]�� ��. ���зֲ�ʽ�������. �人������������ѧ�����磬1997��
[2]�� ��. ��ɢ��ѧ����. �人������������ѧ�����磬1994��
[3]������ ����Ƽ ��. ����������ѧѧ�� ��2000��
[4]������۳�£�л���ȣ�˳�������ת��ϵͳHZPARA���������˼�롣��������Ӧ�ã�1993��3����55~57��
[5]�����������У�Ҷ�࣬�������������Ӧ�á�2007���43����1�ڡ�
[6] Almeida V A F,Vasconcelos I M,Arable J N C,et al..Using random task graphs to investigate the potential of heterogeneity in parallel in parallel systems[c]//proc super2 computing 1992.
[7] Hwang Yuan-shin,Saltz J H.Identifying parallelism in programs with cyclic graphs[J].Journal of Parallel and Distriduted computing,2003.
[8] Zhao jian-jun Dependence analysis of Java bytecode[C]//24th Internatianal Computer and Applicatians Computer Software and Applicatians Conference,2000-10.
[9]z����ݥ. �칹���㻷����ѭ������������ȡ������[J].���������,2006,26��3��.
[10]�»���. ������. ����������Ա���ԭ��[M]����������������,2000.