������ʱ����Apriori�Ľ��㷨
��Դ����������
ʱ�䣺2010-08-30


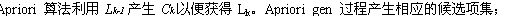 Ȼ������ Apriori����ɾ����Щ�Ӽ�Ϊ��Ƶ����ĺ�ѡ���һ���������к�ѡ����Ҫɨ�����ݿ⣬�������ݿ��е�ÿ����������subset �������������ָý���¼�����У��ѳ�Ϊ��ѡ������Ӽ����ɴ��ۼ�ÿ����ѡ���֧��Ƶ�ȡ�����������С֧��Ƶ�ȵĺ�ѡ������Ƶ��� L��Ȼ��,������������ѡ���Ŀ�������,�ر���Ƶ�����ܳ�����С֧�ֶȷdz�Сʱ������,����104��Ƶ��1-�ʱ,Apriori�㷨�ͻ��������107���ĺ�ѡ2-������Apriori�㷨��ƿ�������������һ�ֻ�����ʱ���ĸĽ��㷨��2 ������ʱ����Apriori�Ľ��㷨2.1 ����˼��������ʱ����Apriori�Ľ��㷨����������������ʵ��(1) ������֪��ģ���������ݿ�D������һ���I�ij���Ƶ�������ģС��|I|�������ء������ڵ�|I|��ɨ�����ݿ�Dʱ������ɾ����ģС��|I|�������¼��(2) k-��ѡ��в������κ�(k-1)-����һ������Ƶ��������k��ɨ��ʱ���Խ������������¼����ɾ�����Ӷ��������´���Ҫɨ��ļ�¼��������ʱ�������Ƶ�����ѡ�����Ȱ�(k-1)-��еĵ�һ������ӽ���ʱ���У�Ȼ������һ�ͬ����������ӽ���ʱ��������k-�����Ƶ���ȣ���Ƶ���ȴ�����СƵ���ȣ������ɸ�Ƶ������棬����ɾ��������ѭ����ֱ���������е�Ƶ���2.2 �Ľ��㷨���������룺�������ݿ�D����С֧�ֶ���ֵmin_sup�����D��Ƶ���L����˵���� Ck��k-��ѡ� Lk��k-Ƶ��� Dk����k��ɨ�������ݿ�L1 = {large 1-itemsets}; //D�е�1-�
Ȼ������ Apriori����ɾ����Щ�Ӽ�Ϊ��Ƶ����ĺ�ѡ���һ���������к�ѡ����Ҫɨ�����ݿ⣬�������ݿ��е�ÿ����������subset �������������ָý���¼�����У��ѳ�Ϊ��ѡ������Ӽ����ɴ��ۼ�ÿ����ѡ���֧��Ƶ�ȡ�����������С֧��Ƶ�ȵĺ�ѡ������Ƶ��� L��Ȼ��,������������ѡ���Ŀ�������,�ر���Ƶ�����ܳ�����С֧�ֶȷdz�Сʱ������,����104��Ƶ��1-�ʱ,Apriori�㷨�ͻ��������107���ĺ�ѡ2-������Apriori�㷨��ƿ�������������һ�ֻ�����ʱ���ĸĽ��㷨��2 ������ʱ����Apriori�Ľ��㷨2.1 ����˼��������ʱ����Apriori�Ľ��㷨����������������ʵ��(1) ������֪��ģ���������ݿ�D������һ���I�ij���Ƶ�������ģС��|I|�������ء������ڵ�|I|��ɨ�����ݿ�Dʱ������ɾ����ģС��|I|�������¼��(2) k-��ѡ��в������κ�(k-1)-����һ������Ƶ��������k��ɨ��ʱ���Խ������������¼����ɾ�����Ӷ��������´���Ҫɨ��ļ�¼��������ʱ�������Ƶ�����ѡ�����Ȱ�(k-1)-��еĵ�һ������ӽ���ʱ���У�Ȼ������һ�ͬ����������ӽ���ʱ��������k-�����Ƶ���ȣ���Ƶ���ȴ�����СƵ���ȣ������ɸ�Ƶ������棬����ɾ��������ѭ����ֱ���������е�Ƶ���2.2 �Ľ��㷨���������룺�������ݿ�D����С֧�ֶ���ֵmin_sup�����D��Ƶ���L����˵���� Ck��k-��ѡ� Lk��k-Ƶ��� Dk����k��ɨ�������ݿ�L1 = {large 1-itemsets}; //D�е�1-� 

 3 �Ľ�ǰ��ķ����Ƚ�Ϊ�����㷨�ıȽ�,ѡȡ[6]��Apriori�㷨ʹ�õ�AllElectronicsij�ֵ���������ݿ��е����ݽ����㷨ģ��,���1��ʾ��
3 �Ľ�ǰ��ķ����Ƚ�Ϊ�����㷨�ıȽ�,ѡȡ[6]��Apriori�㷨ʹ�õ�AllElectronicsij�ֵ���������ݿ��е����ݽ����㷨ģ��,���1��ʾ��| TID | ����б� |
| T100 | I1,I2,I5 |
| T200 | I2,I4 |
| T300 | I2,I3 |
| T400 | I1,I2,I4 |
| T500 | I1,I3 |
| T600 | I2,I3 |
| T700 | I1,I3 |
| T800 | I1,I2,I3,I5 |
| T900 | I1,I2,I3 |
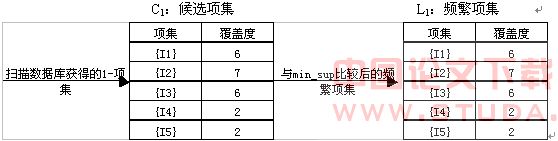 (2) ����L1��L1��������ѡ2-�C2����C2ȷ��Ƶ��2-�����ͼ2��ʾ��
(2) ����L1��L1��������ѡ2-�C2����C2ȷ��Ƶ��2-�����ͼ2��ʾ�� 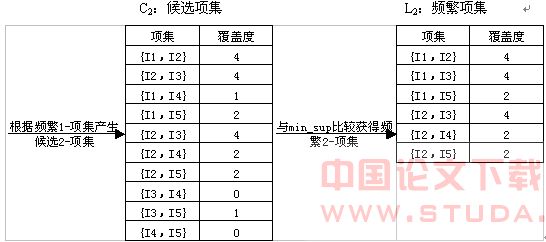
(3) ����L2��L2�������Ӳ�������ú�ѡ3-�C3��Ϊ{(I1,I2,I3),(I1,I2,I5),(I1,I3,I5),(I2,I3,I5),(I2,I4,I5)}������Apriori��һ��Ƶ����������Ӽ�Ҳ��Ƶ���ġ������ʣ�����ȷ�����ĸ����������Ƶ���ģ���˿���ɾ�����ǣ��Ӷ�������ɨ������������ͼ3��ʾ��
 ͼ3(4) ����L3��L3�������Ӳ����õ�C4������Apriori���ʿ�֪C4=�����㷨���˽������ɴ˿ɼ���Apriori�㷨ÿ��ɨ�趼Ҫ����ɨ���������ݿ�D�����Ľ�����㷨��ʱ�Ľ�������Ҫ����ɾ�����Ӷ��������´�ɨ�����ݿ�ļ�¼����Apriori�㷨�������Ӳ���ʱ�����������������ʹ����ʱ����ֻ�轫���һ����ͬ����������ӣ��Ӷ���ʡ�˴����Ĵ洢�ռ䡣�㷨�ȽϽ�����±���ʾ��
ͼ3(4) ����L3��L3�������Ӳ����õ�C4������Apriori���ʿ�֪C4=�����㷨���˽������ɴ˿ɼ���Apriori�㷨ÿ��ɨ�趼Ҫ����ɨ���������ݿ�D�����Ľ�����㷨��ʱ�Ľ�������Ҫ����ɾ�����Ӷ��������´�ɨ�����ݿ�ļ�¼����Apriori�㷨�������Ӳ���ʱ�����������������ʹ����ʱ����ֻ�轫���һ����ͬ����������ӣ��Ӷ���ʡ�˴����Ĵ洢�ռ䡣�㷨�ȽϽ�����±���ʾ��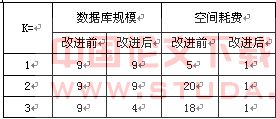 ��2˵������2�����ݿ��ģ��ָ���ݿ��еļ�¼�����ռ�ķ���ָ���ɵĺ�ѡ���ռ�Ŀռ䡣�ӱ�2���Կ�������ɨ���ģ�ϣ�Aprioriÿ����Ҫ�����е��������ݿ����ɨ�裬��������ʱ���ĸĽ��㷨�ڵڶ�������ɨ��������ж�Ԫ�� T200��T300��T500��T600��T700��ɾ���������ε�ɨ��������4���ڿռ�ķ��ϣ���һ�ζ� 5 ����������ж�ÿһ������ռһλ�ռ䣬��Ҫ�Ŀռ�ķ�Ϊ 5���ڶ��ν��� JOIN ����ʱ����Ҫ��C14+C13+C12+C11����2=10��2=20 ����Ԫ�ռ䣬�����ν��� JOIN ���㣬��Ҫ��C13+C12+C11����3=18����Ԫ�ռ䡣��ʱ��ѹ���㷨�����������̬����Ƶ�����������ռ��Ϊ 1�� 4.������ �����ڶ�Apriori�ھ��㷨�������о������ϣ�����˻�����ʱ���ĸĽ��㷨��ͨ�������Ƚϣ��ڼ���ɨ�����ݿ��м�¼�����ͽ������Ӳ�������ռ�ķ��ϣ�ȡ���˽Ϻõ�Ч������ Apriori��ȣ�������ʱ���ĸĽ��㷨�����ݹ�ģ���ռ�ķ��Ͼ�ռ�����ƣ������ݹ�ģ�������������ƽ��������ԡ� ���ף�1 R Agrawal,R Wrikant. Fast Algorithms for Mining Association Rules in Large Databases. Proc,20th int��l Conf.Very large databases.1994��478~4992 Margarent H.Dunham. Data Mining Introductory and Advanced Topics. Southern Mehodist University.20033 Brin S, Motwani R. Dynamic Itemset Counting and Implication Rules for Market Basket Data. In: Proc. Of the 1997 ACM_SIGMOD Int��1 Conf, On the Management of Data. New York: ACM Press, 1997 4 �½�ƽ,������,��־��.һ��Apriori�ĸĽ��㷨.�人��ѧѧ��(��Ϣ��),2003,2.5 ���۷ɣ����.�����ھ���֪ʶ����.�������ߵȳ����磬2003.6 �����.�����ھ�����뼼��.����:��е������,20017 Savasere A,Ong B, Mitbander B. An efficient algorithm for mining association rules in large databases[A]. In Proc 1995, Int Conf Very Large Databases(VLDB��95)[C].19958 Bayardo R J, Agrawal R. Mining the Most Interesting Rules[c]. Processing of the 5th International Conference on knowledge Discovery and Data Mining. San Diego: ACMPress, 1999:145-154
��2˵������2�����ݿ��ģ��ָ���ݿ��еļ�¼�����ռ�ķ���ָ���ɵĺ�ѡ���ռ�Ŀռ䡣�ӱ�2���Կ�������ɨ���ģ�ϣ�Aprioriÿ����Ҫ�����е��������ݿ����ɨ�裬��������ʱ���ĸĽ��㷨�ڵڶ�������ɨ��������ж�Ԫ�� T200��T300��T500��T600��T700��ɾ���������ε�ɨ��������4���ڿռ�ķ��ϣ���һ�ζ� 5 ����������ж�ÿһ������ռһλ�ռ䣬��Ҫ�Ŀռ�ķ�Ϊ 5���ڶ��ν��� JOIN ����ʱ����Ҫ��C14+C13+C12+C11����2=10��2=20 ����Ԫ�ռ䣬�����ν��� JOIN ���㣬��Ҫ��C13+C12+C11����3=18����Ԫ�ռ䡣��ʱ��ѹ���㷨�����������̬����Ƶ�����������ռ��Ϊ 1�� 4.������ �����ڶ�Apriori�ھ��㷨�������о������ϣ�����˻�����ʱ���ĸĽ��㷨��ͨ�������Ƚϣ��ڼ���ɨ�����ݿ��м�¼�����ͽ������Ӳ�������ռ�ķ��ϣ�ȡ���˽Ϻõ�Ч������ Apriori��ȣ�������ʱ���ĸĽ��㷨�����ݹ�ģ���ռ�ķ��Ͼ�ռ�����ƣ������ݹ�ģ�������������ƽ��������ԡ� ���ף�1 R Agrawal,R Wrikant. Fast Algorithms for Mining Association Rules in Large Databases. Proc,20th int��l Conf.Very large databases.1994��478~4992 Margarent H.Dunham. Data Mining Introductory and Advanced Topics. Southern Mehodist University.20033 Brin S, Motwani R. Dynamic Itemset Counting and Implication Rules for Market Basket Data. In: Proc. Of the 1997 ACM_SIGMOD Int��1 Conf, On the Management of Data. New York: ACM Press, 1997 4 �½�ƽ,������,��־��.һ��Apriori�ĸĽ��㷨.�人��ѧѧ��(��Ϣ��),2003,2.5 ���۷ɣ����.�����ھ���֪ʶ����.�������ߵȳ����磬2003.6 �����.�����ھ�����뼼��.����:��е������,20017 Savasere A,Ong B, Mitbander B. An efficient algorithm for mining association rules in large databases[A]. In Proc 1995, Int Conf Very Large Databases(VLDB��95)[C].19958 Bayardo R J, Agrawal R. Mining the Most Interesting Rules[c]. Processing of the 5th International Conference on knowledge Discovery and Data Mining. San Diego: ACMPress, 1999:145-154