时间序列相空间重构及其应用研究
来源:岁月联盟
时间:2010-08-30





自从人们发现延迟时间
 对重构相空间的重要之后,便开始了探索确定延迟时间
对重构相空间的重要之后,便开始了探索确定延迟时间 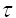 的方法,并取了显著的成效,相空间重构理论认为,要保证相空间重构的正确性,所选用的延迟时间
的方法,并取了显著的成效,相空间重构理论认为,要保证相空间重构的正确性,所选用的延迟时间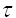 必须使重构相空间的各个分量保持相互独立,选择的延迟时间如果太大, 就混沌吸引子而言,由于蝴蝶效应的影响,时间序列的任意两个相邻延迟坐标点将毫不相关,不能反映整个系统的特性;而延迟时间选择过小的话,时间序列的任意两个相邻延迟坐标点又非常接近,不能相互独立,将会导致数据的冗余。.因此我们需要一种方法来选择恰当的
必须使重构相空间的各个分量保持相互独立,选择的延迟时间如果太大, 就混沌吸引子而言,由于蝴蝶效应的影响,时间序列的任意两个相邻延迟坐标点将毫不相关,不能反映整个系统的特性;而延迟时间选择过小的话,时间序列的任意两个相邻延迟坐标点又非常接近,不能相互独立,将会导致数据的冗余。.因此我们需要一种方法来选择恰当的 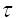 ,于是围绕这一条件便先后出现了用自相关函数和互信息来确定延迟时间
,于是围绕这一条件便先后出现了用自相关函数和互信息来确定延迟时间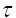 的方法[3]。自相关函数能够提供信号自身与它的时延之间由冗余到不相关比较这种的度量,一般取自相关函数值首次出现零点时的时延为所要确定的时间延迟。现描述如下:对于单变量时间序列x1, x2, x3,…, xn取延迟时间为
的方法[3]。自相关函数能够提供信号自身与它的时延之间由冗余到不相关比较这种的度量,一般取自相关函数值首次出现零点时的时延为所要确定的时间延迟。现描述如下:对于单变量时间序列x1, x2, x3,…, xn取延迟时间为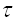 ,则其自相关函数为:
,则其自相关函数为: (9)其中,n为时间序列点数
(9)其中,n为时间序列点数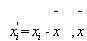 , 为时间序列的平均值.延迟时间
, 为时间序列的平均值.延迟时间 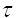 的选取原则是让时间序列内元素之间的相关性减弱,同时又要保证时间序列包含的原系统的信息不会丢失.研究表明,当关联函数C的值第一次为0(或近似为0)对应的延迟时间
的选取原则是让时间序列内元素之间的相关性减弱,同时又要保证时间序列包含的原系统的信息不会丢失.研究表明,当关联函数C的值第一次为0(或近似为0)对应的延迟时间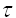 比较合适[4]. 4 关联维m的选取在关联维中,重构相空间维数的取值依赖于所分析和研究的关联维数,数据序列的关联维数不同,所选取的重构相空间维数亦不同。由单变量的时间序列重构相空间时,为了保证该相空间能包含原状态空间吸引子的特征, 关联维应该取得足够大.Takens在1980年证明了嵌入维数大小的嵌入定理:
比较合适[4]. 4 关联维m的选取在关联维中,重构相空间维数的取值依赖于所分析和研究的关联维数,数据序列的关联维数不同,所选取的重构相空间维数亦不同。由单变量的时间序列重构相空间时,为了保证该相空间能包含原状态空间吸引子的特征, 关联维应该取得足够大.Takens在1980年证明了嵌入维数大小的嵌入定理: (10)其中:m---重构相空间维数;D2---原状态空间吸引子所处空间的关联维数该定理表明,嵌入空间的维数至少是吸引子维数的两倍,这时重构的相空间和原系统的状态空间拓扑等价.但是由于在一般情况下缺乏原动力系统的先验知识,选择m则具有随意性系统特征量饱和法,是使重构相空间维数由小到大变化,计算每一个重构相空间的系统特征量,如果特征量达到饱和,则饱和时的重构相空间维数就是所求的维数.一般情况下,确定性系统一般都会收敛到低维的相空间,关联维数将不再随嵌入维数的增加而发生明显的改变,因此可以取关联维数作为系统特征量,逐渐增大嵌入维数,观察关联维数是否达到饱和. 在实际的分形分析中,关联维数是所要求取的对象,并不知道其具体数值,因此,需首先估计出所求关联维的取值范围,从而得出重构相空间维数m的粗略估计值。在m粗略估计值的范围内对m取不同的值,然后分别求取系统的关联维数,当关联维数达到饱和时的m取值,即为重构相空间的实际维数。 5 应用展望对于平稳的时间序列来讲,利用传统的AR、MA、ARMA等模型通常可获得较好的预报结果.而对混沌时间序列而言,即使模型对数据匹配的很好,有时也无法做出准确的预测,未来趋势会在性质上与原有时间序列趋势发生根本不同的变化.因此,对混沌时间序列的预测研究我们需另找出路. 时间序列的量往往伴随有大量的噪声,神经比其它方法更能容忍噪声。任何一个时间序列都可以看成是一个由非线性机制确定的输入输出系统,神经网络可以较好地揭示非线性时间序列在时延状态空间中的相关性,从而达到预测目的。具体说来,可以这样处理: (1)神经网络用于单变量时间序列预测设一个单变量时间序列x1, x2, x3,…, xn对它进行预测的前提是认为其未来值与其前面的m个值之间有着某种函数关系,可描述如下:xn +k=F(xn, xn-1,…, xn-m+1)利用神经网络来拟合这种函数关系F(·),并用它来推导未来的值.进行时间序列预测的神经网络结构可以分为两种,一种是单步预测网络,一种是多步网络预测.单步预测网络输出个数为1个,一次可计算一步的预测值.多步预测网络的输出个数不止一个而是多个(K个),每一次可计算出K步的预测值.在预测过程中,可将得到的预测值作为下一步预测的输入来计算出进一步的预测值,进行迭代的多步预测.(2)神经网络用于多变量时间序列预测对多变量时间序列(x11, x21,…, xp1), (x12, x22,…, xp2),…,它有p个时间变量.如同量时间序列一样,认为时间序列的未来值与面的m个值之间有某种函数关系:(x1n+k, x2n+k,…, xpn+k)= F((x1n, x2n,…, xpn), (x1n-1, x2n-1,…, xpn-1),…, (x1n-m+1, x2n-m+1,…, xpn-m+1))利用神经网络拟合函数F(·),并用它进行预测.进行多变量时间序列预测的神经网络结构。同样分为两种,单步预测网络和多步预测网络.单步预测网络输出的个数是一个多变量时间序列的变量个数为p,一次计算得到所有变量一步的预测值.多步预测网络的输出个数为K×P个,一次计算可得到所有P个变量的K步预测结果.这两种网络模型同样也可以进行迭代多步预测计算.利用传统的预测方法进行多变量时间序列的建模与预测非常复杂.而利用神经网络进行多变量时间序列的预测方法如同单变量时间序列预测一样简单,这是传统的预测方法无法比拟的.[5]神经网络所具有的非线性变换和高度的并行处理能力为一类呈高度非线性动态关系的时间序列预测提供了一条十分有效的途径,利用神经网络进行非线性预测,是神经网络在统计预测领域新的应用,这一方法的优越性将逐步为人们所认识,而成为统计预测的重要工具。神经网络方法作为分析预测时间序列变量的工具,有重要的意义和应用前景,当然也有许多问题有待深入探讨和研究。:[1] 杨绍清, 贾传荧. 两种实用的相空间重构方法 . 物 理 学 报 , 第51卷第11期2002年11月 :2452-2456[2] 党建武 ,黄建国 . 基于G.P算法的关联维计算中参数取值的研究. 计算机应用研究 ,2004,1:48-51[3]Fraser A M,Swinney H L.Independent coordinates from mutual information[J].Phys Rev A,1986,33:1134~1140.[4]李玉霞, 吴百海, 邢志鹏.单变量时间序列相空间重构及应用研究 . 组合机床与自动化加工技术 2004,2:51-55[5] 刘 豹 ,胡代平. 神经网络在预测中的一些应用研究 . 系 统 工 程 学报 ,1999,12:338-343
(10)其中:m---重构相空间维数;D2---原状态空间吸引子所处空间的关联维数该定理表明,嵌入空间的维数至少是吸引子维数的两倍,这时重构的相空间和原系统的状态空间拓扑等价.但是由于在一般情况下缺乏原动力系统的先验知识,选择m则具有随意性系统特征量饱和法,是使重构相空间维数由小到大变化,计算每一个重构相空间的系统特征量,如果特征量达到饱和,则饱和时的重构相空间维数就是所求的维数.一般情况下,确定性系统一般都会收敛到低维的相空间,关联维数将不再随嵌入维数的增加而发生明显的改变,因此可以取关联维数作为系统特征量,逐渐增大嵌入维数,观察关联维数是否达到饱和. 在实际的分形分析中,关联维数是所要求取的对象,并不知道其具体数值,因此,需首先估计出所求关联维的取值范围,从而得出重构相空间维数m的粗略估计值。在m粗略估计值的范围内对m取不同的值,然后分别求取系统的关联维数,当关联维数达到饱和时的m取值,即为重构相空间的实际维数。 5 应用展望对于平稳的时间序列来讲,利用传统的AR、MA、ARMA等模型通常可获得较好的预报结果.而对混沌时间序列而言,即使模型对数据匹配的很好,有时也无法做出准确的预测,未来趋势会在性质上与原有时间序列趋势发生根本不同的变化.因此,对混沌时间序列的预测研究我们需另找出路. 时间序列的量往往伴随有大量的噪声,神经比其它方法更能容忍噪声。任何一个时间序列都可以看成是一个由非线性机制确定的输入输出系统,神经网络可以较好地揭示非线性时间序列在时延状态空间中的相关性,从而达到预测目的。具体说来,可以这样处理: (1)神经网络用于单变量时间序列预测设一个单变量时间序列x1, x2, x3,…, xn对它进行预测的前提是认为其未来值与其前面的m个值之间有着某种函数关系,可描述如下:xn +k=F(xn, xn-1,…, xn-m+1)利用神经网络来拟合这种函数关系F(·),并用它来推导未来的值.进行时间序列预测的神经网络结构可以分为两种,一种是单步预测网络,一种是多步网络预测.单步预测网络输出个数为1个,一次可计算一步的预测值.多步预测网络的输出个数不止一个而是多个(K个),每一次可计算出K步的预测值.在预测过程中,可将得到的预测值作为下一步预测的输入来计算出进一步的预测值,进行迭代的多步预测.(2)神经网络用于多变量时间序列预测对多变量时间序列(x11, x21,…, xp1), (x12, x22,…, xp2),…,它有p个时间变量.如同量时间序列一样,认为时间序列的未来值与面的m个值之间有某种函数关系:(x1n+k, x2n+k,…, xpn+k)= F((x1n, x2n,…, xpn), (x1n-1, x2n-1,…, xpn-1),…, (x1n-m+1, x2n-m+1,…, xpn-m+1))利用神经网络拟合函数F(·),并用它进行预测.进行多变量时间序列预测的神经网络结构。同样分为两种,单步预测网络和多步预测网络.单步预测网络输出的个数是一个多变量时间序列的变量个数为p,一次计算得到所有变量一步的预测值.多步预测网络的输出个数为K×P个,一次计算可得到所有P个变量的K步预测结果.这两种网络模型同样也可以进行迭代多步预测计算.利用传统的预测方法进行多变量时间序列的建模与预测非常复杂.而利用神经网络进行多变量时间序列的预测方法如同单变量时间序列预测一样简单,这是传统的预测方法无法比拟的.[5]神经网络所具有的非线性变换和高度的并行处理能力为一类呈高度非线性动态关系的时间序列预测提供了一条十分有效的途径,利用神经网络进行非线性预测,是神经网络在统计预测领域新的应用,这一方法的优越性将逐步为人们所认识,而成为统计预测的重要工具。神经网络方法作为分析预测时间序列变量的工具,有重要的意义和应用前景,当然也有许多问题有待深入探讨和研究。:[1] 杨绍清, 贾传荧. 两种实用的相空间重构方法 . 物 理 学 报 , 第51卷第11期2002年11月 :2452-2456[2] 党建武 ,黄建国 . 基于G.P算法的关联维计算中参数取值的研究. 计算机应用研究 ,2004,1:48-51[3]Fraser A M,Swinney H L.Independent coordinates from mutual information[J].Phys Rev A,1986,33:1134~1140.[4]李玉霞, 吴百海, 邢志鹏.单变量时间序列相空间重构及应用研究 . 组合机床与自动化加工技术 2004,2:51-55[5] 刘 豹 ,胡代平. 神经网络在预测中的一些应用研究 . 系 统 工 程 学报 ,1999,12:338-343