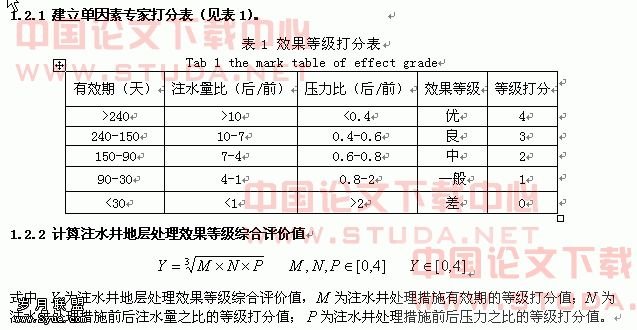
矿脉分布的回归模型建立与选择
关键词:散点图 回归模型 剩余标准差
论文摘要:本文主要研究的是矿脉分布的模型建立,通过对已知数据的分析,作出散点图,然后建立合适的回归模型,如:线性模型、二次模型、双曲线模型、对数模型等。运用MATLAB软件,通过对建立模型的剩余标准差比较,选择出最合适的回归模型为二次模型。通过对论文的研究,熟悉MATLAB软件的应用以及在模型建立中对模型选择的认识。
1 引言
本文通过研究矿脉的分布的研究,建立回归模型,包括线性模型、二次模型、双曲线模型、对数模型等模型。应用MATLAB软件对模型的比较与分析,选择出最合适的模型并对结果进行分析。
2 模型分析
2.1 问题的重述
一矿脉有13个相邻样本点,人为地设定一原点,现测得各样本点对原点的距离x,与该样本点处某种金属含量y 的一组数据如下(附录表2.1),画出散点图观测二者的关系,试建立合适的回归模型,如二次曲线、双曲线、对数曲线等。
2.2 问题的分析
2.2.1 模型假设
本问题中没有给出明确的模型选择,我们先画出其散点图,然后对其分析,建立模型。
从数理统计的观点看,这里涉及的都是随机变量,我们根据一个样本出的那些系数,只是它们的一个(点)估计,应该对它们作区间估计或假设检验,如果置信区间太大,甚至包含了零点,那么系数的估计值是没有多大意义的。另外也可以用方差分析方法对模型的误差进行分析,对拟合的优劣给出评价。
具体地说,回归分析在一组数据的基础上研究这样几个问题:
( i ) 建立因变量y与自变量 QUOTE ![]()
![]() … QUOTE
… QUOTE ![]()
![]() 之间的回归模型 (经验公式);
之间的回归模型 (经验公式);
(ii)对回归模型的可信度进行检验;
(iii)判断每个自变量对y的影响是否显著;
(iv)诊断回归模型是否适合这组数据;
(v )利用回归模型对y 进行预报或控制。
2.2.2 模型建立
Matlab 统计工具箱用命令regress 实现多元线性回归,用的方法是最小二乘法,用法是:b=regress(Y,X).
其中X ,Y是按照 QUOTE 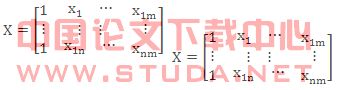 , QUOTE
, QUOTE 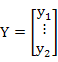 式排列的数据,b 为回归系数估计值为 QUOTE
式排列的数据,b 为回归系数估计值为 QUOTE ![]()
![]() 通过码头MATLAB建立回归模型。
通过码头MATLAB建立回归模型。
[b,bint, ,rint,stats]=regress(Y,X,alpha) 这里Y,X 同上,alpha 为显著性水平(缺省时设定为0.05 ),b,bint 为回归系数估计值 和它们的置信区间,,rint 为残差 (向量)及其置信区间,stats 是用于检验回归模型的统计量,有三个数值,第一个是 QUOTE ![]()
![]() ,第二个是 QUOTE
,第二个是 QUOTE ![]()
![]() ,第三个是与F对应的概率P,P QUOTE 拒绝
,第三个是与F对应的概率P,P QUOTE 拒绝![]()
![]() QUOTE
QUOTE ![]()
![]() ,回归模型成立.残差以及置信区间可以用rcoplot( ,rint)画图。
,回归模型成立.残差以及置信区间可以用rcoplot( ,rint)画图。
3 模型求解
3.1散点图模型的求解
输入程序及题目数据,绘出散点图:
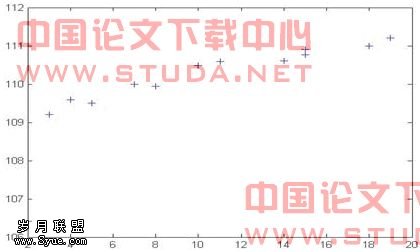
<图3.1>
从图像上看,如果第一个点数据剔除,线性关系比较明显,但并不能排除其他模型。下面就对几种模型都加以计算比较。(图3.1,程序见附录3.1)
3.1.1 线性模型
输入程序得到图(3.2),程序见附录3.2
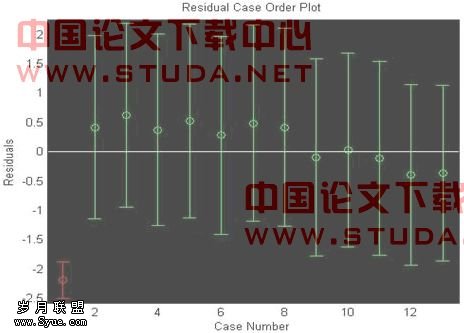
<图3.2>
结果输出:
b =108.2581 0.1742
Bint =107.2794 109.2367 0.0891 0.2593
stats =0.6484 20.2866 0.0009
线性相关系数较小,线性回归模型在alpha>0.0009成立第一个点为异常点(仅指线性模型下),予以剔除,再次输入程序得图(3.3),程序见附录3.3

<图3.3>
结果输出:
b =109.0668 0.1159
bint =108.8264 109.3072 0.0958 0.1360
stats =0.9428 164.8060 0.0000
剔除第一个点后线性系数和p值都变得好了很多。没有异常点。
线性模型为: QUOTE ![]()
![]()
对该模型求剩余标准差:
rmse=sqrt(sum((y-b(1)-b(2)*x1).^2)/10)得:rmse =0.1635
3.1.2 二次曲线
考虑第一个点偏离太多,予以剔除后重新输入程序计算可得:
p =-0.0043 0.2102 108.6718
二次模型 QUOTE ![]()
![]()
对该模型求剩余标准差:
[Y,delta]=polyconf(p,x,S);
rmse=sqrt(sum((y-Y).^2)./10),得:
rmse =0.1231
程序见附录3.4
3.1.3 双曲线模型
双曲线模型类似于 QUOTE ![]()
![]() ,可以通过将x的倒数代换转化为线性模型来求。输入程序得到图(3.4),程序见附录3.5
,可以通过将x的倒数代换转化为线性模型来求。输入程序得到图(3.4),程序见附录3.5

<图3.4>
输出结果:b =111.4405 -9.0300
bint =111.1068 111.7743 -10.6711 -7.3889
stats =0.9302 146.6733 0.0000
有两个异常点,剔除后再次输入程序可得图(3.5),程序见附录3.6

<图3.5>
输出结果:b =111.5653 -10.9938
bint =111.2882 111.8424 -13.5873 -8.4002
stats =0.9309 107.7623 0.0000
双曲线模型 QUOTE ![]()
![]()
对该模型求剩余标准差:
rmse=sqrt(sum((y-b(1)-b(2)./x1).^2)/8)得:
rmse =0.1487
3.1.4 对数曲线
类似于双曲线模型,输入程序得图(3.6),程序见附录3.7

<图3.6>
输出结果:b =106.7113 1.5663
bint =105.6382 107.7844 1.0828 2.0499
stats =0.8221 50.8285 0.0000
剔除异常点,重新输入程序计算可得图(3.7),程序见附录3.8

<图3.7>
输入结果:b =107.9762 1.0496
bint =107.6403 108.3121 0.9037 1.1956
stats =0.9625 256.7014 0.0000
对数模型 QUOTE ![]()
![]()
对该模型求剩余标准差:rmse=sqrt(sum((y-b(1)-b(2)*log(x1)).^2)/10)得:rmse =0.1324
3.2 结果比较
通过对几个模型的比较可得,二次模型的剩余标准差最小。不过几个模型的差别很小。如表(3.1)
线性模型 | 二次模型 | 双曲线模型 | 对数模型 |
0.1635 | 0.1213 | 0.1487 | 0.1324 |
<表3.1>
4结果分析
第一个点的讨论。纵观四个模型,第一个点都属于异常点,需要剔除。但什么样的点必须剔除?对于这个问题,不合理的点固然要剔除,但同时点数的减少又将使得样本的容量变小,信度降低,这就需要使用者的判断。向本题中的第一个数据,很明显不符合任何模型,严重干扰回归分析,可以判断为是异常点,予以剔除。
第二个是模型的选择。本题目的特点在于,因为对矿物分布和地质知识的缺乏,不能从理论上加以分析,只能从数据本身出发,加以分析。这就隐藏了很多问题。
5 中的公式
QUOTE 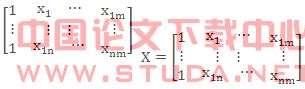 , QUOTE
, QUOTE
(2.1)
QUOTE ![]()
![]() (2.2)
(2.2)
QUOTE ![]()
![]() (2.3)
(2.3)
6 结论
通过对几个模型的比较可得,二次模型的剩余标准差最小。不过几个模型的差别很小。固采用二次模型为最合适模型
附录
表2.1
X | 2 | 3 | 4 | 5 | 7 | 8 | 10 |
Y | 106.42 | 109.20 | 109.58 | 109.50 | 110.00 | 109.93 | 110.49 |
x | 11 | 14 | 15 | 16 | 18 | 19 | |
Y | 110.59 | 110.60 | 110.90 | 110.76 | 111.00 | 111.20 |
程序3.1
x1=[2 3 4 5 7 8 10 11 14 15 15 18 19]';
y=[106.42 109.20 109.58 109.50 110.00 109.93 110.49 110.59 110.60 110.90 110.76 111.00 111.20]';
plot(x1,y,'+')
程序3.2
alpha=0.05;
x1=[2 3 4 5 7 8 10 11 14 15 15 18 19]';
y=[106.42 109.20 109.58 109.50 110.00 109.93 110.49 110.59 110.60 110.90 110.76 111.00 111.20]';
x=[ones(13,1),x1];
[b,bint,r,rint,stats]=regress(y,x,alpha);
b,bint,stats,rcoplot(r,rint)
程序3.3
alpha=0.05;
x1=[3 4 5 7 8 10 11 14 15 15 18 19]';
y=[109.20 109.58 109.50 110.00 109.93 110.49 110.59 110.60 110.90 110.76 111.00 111.20]';
x=[ones(12,1),x1];
[b,bint,r,rint,stats]=regress(y,x,alpha);
b,bint,stats,rcoplot(r,rint)
程序3.4
x=[3 4 5 7 8 10 11 14 15 15 18 19];
y=[109.20 109.58 109.50 110.00 109.93 110.49 110.59 110.60 110.90 110.76 111.00 111.20];
[p,S]=polyfit(x,y,2);p
程序3.5
alpha=0.05;
x1=[2 3 4 5 7 8 10 11 14 15 15 18 19]';
y=[106.42 109.20 109.58 109.50 110.00 109.93 110.49 110.59 110.60 110.90 110.76 111.00 111.20]';
x=[ones(13,1),1./x1];
[b,bint,r,rint,stats]=regress(y,x,alpha);
b,bint,stats,rcoplot(r,rint)
程序3.6
alpha=0.04;
x1=[5 7 8 10 11 14 15 15 18 19]';
y=[109.50 110.00 109.93 110.49 110.59 110.60 110.90 110.76 111.00 111.20]';
x=[ones(10,1),1./x1];
[b,bint,r,rint,stats]=regress(y,x,alpha);
b,bint,stats,rcoplot(r,rint)
程序3.7
alpha=0.05;
x1=[2 3 4 5 7 8 10 11 14 15 15 18 19]';
y=[106.42 109.20 109.58 109.50 110.00 109.93 110.49 110.59 110.60 110.90 110.76 111.00 111.20]';
x=[ones(13,1),log(x1)];
[b,bint,r,rint,stats]=regress(y,x,alpha);
b,bint,stats,rcoplot(r,rint)
程序3.8
alpha=0.05;
x1=[3 4 5 7 8 10 11 14 15 15 18 19]';
y=[109.20 109.58 109.50 110.00 109.93 110.49 110.59 110.60 110.90 110.76 111.00 111.20]';
x=[ones(12,1),log(x1)];
[b,bint,r,rint,stats]=regress(y,x,alpha);
b,bint,stats,rcoplot(r,rint)