基于混合式P2P网络的语义Web服务发现机制
来源:岁月联盟
时间:2010-08-30
摘 要 本文针对目前Web服务中难以快速准确地实现服务自动发现的问题,提出了一种基于混合式P2P技术和语义网技术的Web服务发现机制。在处理用户查询时,提出了二次检索方法和二级搜索机制,从而增强了基于语义的搜索能力,提高了查全率与查准率,保证了系统的可扩展性和数据的一致性。
关键词 Web服务;语义Web;混合式P2P;Web服务发现;服务匹配
1 引言
传统的Web服务发布、查找和绑定是基于统一描述发布和发现机制UDDI(Universal Discovery,Description and Integration)、描述语言WSDL(Web Service Description Language)和简单对象访问协议SOAP(Simple Object Access Protocol)来进行。UDDI是微软、IBM和 Ariba提出的商业规范,采用集中式的注册中心,在注册数目增多以及更新较快时会导致系统的扩展性和一致性问题。WSDL则是对UDDI中注册的服务进行描述的语言,它描述了访问Web服务所需要的信息,包括操作的参数和返回结果等,但是它不能较好地描述服务的功能,即缺少语义性。 本文为解决可扩展性和一致性问题,将混合式P2P技术结合到Web服务[1][2],来处理元数据的交换,克服传统UDDI技术中服务元数据集中注册、集中存放对搜索广度带来的限制;为解决缺少语义性的问题,引入语义网技术[3],借助于本体和描述逻辑等逻辑推理系统的使用,加强服务描述信息的机器可理解性,支持用户需求和服务能力之间的逻辑推理匹配。本文在分析各种服务发现机制的特点,借鉴相关研究的基础上,设计了在混合式P2P网络上的二次检索方法和二级搜索机制。2 基于语义的Web服务发现二次检索方法
Web服务发现与文档检索相比较,存在两个差别:①Web服务与用户需求必须精确匹配,该Web服务才能被用户成功调用,所以Web服务发现对查准率的要求远远大于文档检索。②在文档检索中可以用关键字概括全文信息,这种常用的关键字匹配方法达不到查准率要求,而Web服务必需要有精确的服务能力描述和接口描述。 目前广泛采用的基于语义的匹配推理机制支持复杂的语义描述,匹配精确度高,但最大的缺点是匹配推理过程耗时巨大,在某种情况下推理过程不可判定。在Web服务发现系统中,服务的匹配比较是系统性能的瓶颈,粗糙的匹配比较会导致系统查准率过低,而精确的匹配比较又会导致匹配耗时过长。因此针对以上问题分析基于关键字的匹配和基于语义的匹配推理两种查询机制的优点,给出了用于Web服务发现的二次检索方法,该方法在不降低查准率的前提下,可以大大减少匹配耗时。2.1 基于关键字的第一次检索
为解决匹配操作耗时巨大的问题,不可能在庞大的网络系统中处处采用基于语义的匹配比较方法,考虑到基于关键字匹配的时间消耗远远小于基于语义的推理匹配的时间消耗。故提出了将匹配操作分两次完成,第一次的匹配使用类似于文档检索中常用到的关键字匹配技术,进行第一次粗糙的匹配。匹配过程如下:当服务请求者定位到符合服务属性的对等体组后,由该对等体组中的超级对等点调用搜索程序组织进行基于关键字的匹配,将用户的关键字与服务关键字进行相似度的,保留相似度大于某一阈值的所有服务,过滤掉毫不相关的服务,将查找到的服务保存到查询服务子集中,作为第二次基于语义推理匹配的候选服务子集。经过第一次的粗糙匹配,已经过滤掉大部分无关服务,大大缩短了查询服务的时间,同时也缩小了下一次的精确匹配的查找范围。而且服务关键字的匹配方式也不会漏掉相关服务,保证了服务查找的查准率。 这里定义服务关键字为KWSi,用户请求服务的关键字为KR,每一个备选服务为WSi,所有的服务集为WS,匹配成功的子集,即作为第二次逻辑匹配的候选子集为Candidates。 第一次的检索算法如下: Candidates=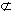 ; //候选子集开始为空 while ( WSi∈WS) if (similarity( KWSi,KR )>threshold) //如果相似度大于规定的阈值 Candidates.Add( WSi); return Candidates;
; //候选子集开始为空 while ( WSi∈WS) if (similarity( KWSi,KR )>threshold) //如果相似度大于规定的阈值 Candidates.Add( WSi); return Candidates;2.2 基于语义描述的精确推理匹配
在第一阶段大大缩小候选服务子集的前提下,第二阶段重点利用服务描述中的语义信息,用逻辑推理系统对Web服务功能和用户目标描述进行精确的匹配。在匹配推理过程中,由超级对等点向UDDI注册中心发送请求,读取候选服务子集中的服务注册描述信息,与用户需求描述中的目标描述进行逻辑匹配比较,匹配成功者保存到最终的匹配服务子集中。当所有的候选服务子集全部匹配完成,由超级对等点将匹配服务子集中的服务描述信息以Soap消息的方式直接发送给服务请求者,以供其选择调用。 在此定义函数Matching()为语义逻辑匹配函数,Matched集为匹配成功服务集,DR为用户需求服务能力的描述信息,DWSi为备选服务能力的描述信息。 算法如下: Matched=;//匹配成功的服务集 while ( Candidates) if (Matching( DWSi,DR )) //进行基于语义的匹配推理 Matched.Add( WSi); return Matched;3 基于混合式P2P网络的二级搜索机制
P2P技术的快速为创建非集中式的(分布式)、动态的Web服务发现机制提供了一个较好的解决思路[4][5]。混合式P2P在纯P2P分布式模型[6]的基础上引入了超级节点(Super Node)的概念,综合了集中式P2P快速查找和纯P2P去中心化的优势。混合式模型将节点按能力不同(可用性、处理能力、存储能力、连接带宽、网络滞留时间等)区分为普通节点和超级节点两类。其中超级节点与其临近的若干普通节点之间构成一个自治的簇,簇内采用基于集中目录式的P2P模式,而整个P2P网络中各个不同的簇之间再通过纯P2P的模式将超级节点相连起来,甚至也可以在各个超级节点之间再次选取性能最优的节点,或者另外引入一个新的性能最优的节点作为索引节点来保存整个网络中可以利用的超级节点信息,并且负责维护整个网络的结构。 由于普通节点的搜索先在本地所属的簇内进行,只有查询结果不充分的时候,才通过超级节点之间进行有限的泛洪(Flooding)。这样就极为有效地消除纯P2P结构中使用泛洪算法带来的网络拥塞、搜索迟缓等不利影响。同时,由于每个簇中的搜索节点监控着所有普通节点的行为,这也能确保一些恶意的攻击行为能在网络局部得到控制,并且超级节点的存在也能在一定程度上提高整个网络的负载平衡。3.1 基于混合式P2P网络的语义Web服务发现模型
本文采用混合式P2P网络平台[7]设计了一个语义Web服务发现模型,如图1描述,一个簇包含了至少一个超级节点。每个簇中的普通节点都被其中一个超级节点维护和管理。超级节点是按照节点的能力(可用性、处理能力、存储能力)动态选定的。超级节点又被叫做簇管理者,它索引了簇内所有普通节点的Web服务描述并且负责与簇内普通节点和不同簇之间的通信。一个簇管理者也可以成为另外簇中的一员。 如果一个簇中所有的成员都是其它簇的管理者,那么这个簇就没有管理者,这样簇叫做超级簇。在图1中,实线圈内为一个超级簇。用户的请求总是由普通簇广播后被超级簇处理的,这样就极大地减少了处理用户请求时所涉及的节点。当一个新节点加入网络时,如果它具有的服务是簇中没有的,它就会创建一个新簇,成为簇的管理者并通知超级簇。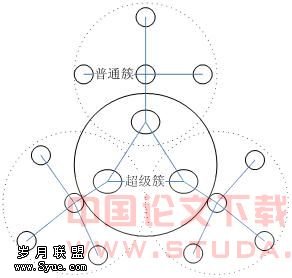 图1 基于混合式P2P的语义Web服务发现模型
图1 基于混合式P2P的语义Web服务发现模型3.2 第一级搜索定位到可能含有目标服务的超级节点
当某个peer的查询代理接受用户的查询请求后,将用户提供的信息在自身所属的簇内进行广播,启用二次检索方法,如果该簇内恰好能找到与请求成功匹配的服务集,则停止搜索。如果没有找到成功匹配的服务集,则广播消息必然会发给超级簇中的一个节点,该超级节点会将服务的查询请求信息在超级簇内再次进行广播。从而根据二次检索策略,找出与请求成功匹配的服务集所属的超级节点。3.3 第二级搜索定位到含有目标服务的普通节点
当超级节点收到P2P网络转发的查询请求时,除完成上述转发任务外,还要将原始的查询消息进行解析,在簇内以广播形式进行转发。簇内各节点收到查询消息后启动二次检索方法,将解析后的结果与自身服务描述消息库中的服务进行匹配操作,如果存在成功的Matched则将结果反馈给最初的peer。4 性能评价和实验结果
为了验证本文所提出的基于混合式P2P网络的二级搜索机制和二次检索方法的可行性和有效性,设计并实现了一个基于混合式P2P网络的用于Web服务发现的检索系统。选取了Internet上的服务实例,如机票预订作为样本,通过两种情况下的服务检索:即组(簇)内检索和跨越对等体组(簇)的服务检索。实验从以下三个方面来进行对比: (1)查找耗时:理论上查找服务所耗费的时间有以下几方面构成。对于只需在簇内就可完成的查找,二次检索所耗费时间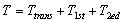 ;对于需要跨越簇的查找,二次检索所耗费时间
;对于需要跨越簇的查找,二次检索所耗费时间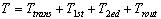 。其中,
。其中,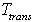 为各节点间平均消息传递的时间;
为各节点间平均消息传递的时间;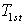 为第一次关键字检索的耗时;
为第一次关键字检索的耗时;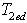 为第二次基于语义的逻辑匹配推理耗时;
为第二次基于语义的逻辑匹配推理耗时;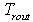 为各组间SOAP消息传递耗时。 (2)查准率:我们利用信息检索中常常用到的查准率作为标准。查准率
为各组间SOAP消息传递耗时。 (2)查准率:我们利用信息检索中常常用到的查准率作为标准。查准率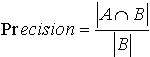 。其中,A代表的是标准结果集,B代表返回的结果集。 (3)可靠性:指它能够及时可靠地提供服务的能力及概率,P=S/A。S为能够成功提供服务的次数,A为提供服务的总次数。 分别对照基于关键字的检索和基于语义的检索,得出实验结果如表1所示。表1 实验结果对照表
。其中,A代表的是标准结果集,B代表返回的结果集。 (3)可靠性:指它能够及时可靠地提供服务的能力及概率,P=S/A。S为能够成功提供服务的次数,A为提供服务的总次数。 分别对照基于关键字的检索和基于语义的检索,得出实验结果如表1所示。表1 实验结果对照表| 第一级搜索(簇内查找) | 第二级搜索(跨簇查找) | |||||
| 基于关键字的检索 | 基于语义的检索 | 二次检索 | 基于关键字的检索 | 基于语义的检索 | 二次检索 | |
| 耗时 | 3s | 9s | 5.5s | 5s | 19s | 14s |
| 查准率 | 11% | 85% | 81% | 8% | 78% | 80% |
| 可靠性 | 0.85 | 0.64 | 0.81 | 0.83 | 0.52 | 0.76 |