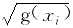论加权回归与建模
摘要:以加权回归估计方法为核心,对林业上常用模型的异方差性进行了研究,提出了能彻底消除异方差的最佳权函数。并对模型的评价指标进行了探讨,提出了评价通用性回归模型的3大指标,并分析了加权回归估计与这些评价指标之间的关系。最后对样本资料的收集进行了讨论,提出了收集建模样本应遵循的基本原则。
关键词:加权回归 建模 异方差 模型评价
林业数表模型是森林经营决策必不可少的计量、预测、评价依据,保证模型质量至关重要,而组织、模型拟合方法和模型评价是保证质量的3个重要环节。实践证明,林业数表模型所描述的问题普遍存在异方差性,在模型拟合中若不采取消除异方差影响的有效方法,必然导致模型有偏。为此,一般可采取加权最小二乘法拟合模型,但在权函数的选择上尚存在两个有待进一步解决的问题:一是权函数的形式因模型所描述的事物的性质不同而异,确定最佳权函数十分繁琐;二是到目前为止,尚未找出能完全消除异方差的权函数。本文旨在提出一种可以完全消除异方差影响的权函数通式,并给出正确评价模型的指标体系及组织建模样本的基本原则。
1 加权回归的概念
确定变量之间的回归关系,一般情况下是利用普通最小二乘法。假设随机变量y~,其中,E(y)=f(x)。也就是说,随机变量y与x满足下列模型:
y=f(x)+ε (1)
式中的ε有3个基本假定,即“独立、正态、等方差”,它们是采用普通最小二乘法建立回归模型的先决条件。3个条件中的“独立”与“正态”在一般情况下都是基本满足的,而“等方差”这一条件,则在很多情况下都难以满足。为解决误差项ε的异方差性问题,应设法校正原有的模型,使校正后的模型其误差项具有常数方差,而模型的校正取决于方差σ2εi与自变量xi之间的关系。假设εi的方差与xi的函数g(xi)呈比例关系,即:
σ2εi=g(xi)σ2 (2)
这里σ2是一个有限常数。于是用![]() 去除原有模型,可使新模型的误差项具有常数方差。用这种方法估计模型中相应的参数,叫做加权最小二乘法(俞大刚,1987)。
去除原有模型,可使新模型的误差项具有常数方差。用这种方法估计模型中相应的参数,叫做加权最小二乘法(俞大刚,1987)。
2 权函数的选择
2.1 异方差性的基本概念
根据回归估计理论,当建立的回归模型的误差项存在异方差时,必须采用加权最小二乘法来消除异方差对参数估计的影响。在林业上所涉及的许多数学模型,如材积模型、生物量模型、生长率模型、削度模型等,其误差项的方差都不为常数,而是随解释变量的变化而变化(骆期邦等,1992;曾伟生等,1992;曾伟生,1996)。一般而言,模型预估值随解释变量的增大而增大时,其误差项的方差也随解释变量的增大而增大,如材积模型和生物量模型;模型预估值随解释变量的增大而减小时,其误差项方差也随解释变量的增大而减小,如生长率模型。在残差图上反映出来,二者都为喇叭型。另外,预估变量的变化范围愈大,异方差性一般也愈明显。因此,采用适当形式缩小预估变量的变动幅度,可在一定程度上消除异方差性。如将材积转化为形数来建模,可将预估变量的取值大致控制在0.35~0.65的范围,使预估值的最大相差倍数从数千倍缩小至2倍以内,从而基本上消除了异方差性。将生长量转化为生长率再建模,也在很大程度上缩小了预估值的变动幅度,可明显削弱其异方差性。
2.2 权函数选择的研究现状
上面提到的一些常用模型,由于存在异方差,因此必须选用适当的权函数来进行加权回归估计。关于这一点,近几年已经逐步有了认识。如对材积模型V=aDbHc的估计,一般认为选用权函数W=1/(D4H2)可有效地消除异方差的影响(骆期邦等,1992);对生长率模型PV=aDbAc的估计,取权函数W=1/(D2A)效果较佳(曾伟生等,1992)。而且,还认识到了最合适的权函数是针对某一个模型而不是某一类模型(曾伟生,1992)。但是,针对一个具体的回归模型,如何确定其最合适权函数的问题仍然没有得到圆满解决。
一般情况下,如果不具有异方差性形式的信息,可通过对剩余值|ei|=g(xi)进行试验,以挑选出一种合适的拟合形式(俞大刚,1987)。另外,也有人提出直接寻找方差S2ei与自变量xi的关系式S2ei=g(xi),再以W=1/g(xi)为权函数进行加权回归,新模型的误差项方差S2ei就会近似为常数1。还进一步提出了较具通用性的抛物线形式的权函数,并取得了较好的效果(曾伟生,1996)。但是这样来确定权函数,一方面比较繁琐;另一方面也难保证抛物线形式能适合所有模型,尤其是含多个自变量的模型;再就是必须有比较大的建模样本才可能得到误差项方差与变量x之间的回归关系。诚然,在此基础上还可以作些改进,如:借鉴曾伟生文(曾伟生等,1997)中可变参数模型的设计,将狭义的抛物线形式y=a+bx+cx2扩展为广义的抛物线形式y=a+bxn+c(xn)2(n=0.5,1,2…)以更好地适应各个模型不同程度的异方差性;从自变量集中选出最主要的变量(如材积模型中的直径)来构造权函数等。即使这样,效果仍然不太理想。
2.3 最佳权函数的确定
前面已经提到,最佳权函数是针对某个模型而不是某类模型,即同类模型中不同的回归方程式应有不同的最佳权函数。基于这一认识,我们再来对一些经典模型及其合适权函数作进一步分析。
不难发现,认为以W=1/(D2H)2为权函数效果较好的材积模型V=aDbHc,其参数b、c的估计值分别接近于2和1;以W=1/(D2A)为权函数的生长率模型PV=aDbAc,其参数b、c的估计值分别接近于1和0.5。最近笔者还发现,形如W=a(D2H)b的生物量模型,取W=1/(D2H)2为权函数效果也很佳,此时b的估计值接近于1。如果定义W=1/g(x)2为权函数,因为上述模型中的参数估计值与权函数中的相应参数值接近,故模型两边同时除以g(x)时,右边都近似等于参数a;若权函数中的相应参数取模型的参数估计值,则模型两边同除g(x)时右边就会恒等于参数a了。更进一步,若取:
W=1/f(x)2 (3)
作为权函数,则模型两边同除以f(x)后得到的新模型,右边都等于1。可以证明,此时得到的新模型,其误差项的期望值为0,方差为常数。亦即,以模型本身构造的权函数就是要寻找的最佳权函数。这刚好应证了“不同模型有不同的最佳权函数”的观点。
该模型为:
y=f(x)+ε (4)
两边同时除以f(x)得新模型:
y′=y/f(x)=1+ε/f(x)=1+ε′ (5)
对新模型(5)采用普通最小二乘法进行估计(相当于原有模型(4)的加权回归估计),有:
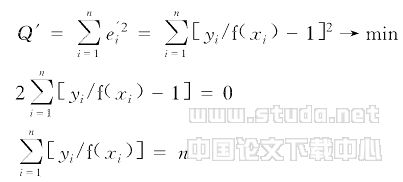 (6)
(6)
下面讨论新模型误差项ε′的性质。
期望值:
E(ε′)=E[ε/f(x)]=E[y/f(x)-1]
由(6)式知,E[y/f(x)]=1,故E(ε′)=0。
方差:
式中f(e′i)为频数(董德元等,1987)。可用建模样本对上述方差D(ε′) 作出如下无偏估计:
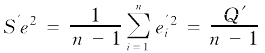
因此,新模型误差项的期望值为0,其方差为常数,即对所有xi来说,每个ε′i的方差都相同;满足等方差的条件。至此可以得出结论:以模型本身构造的权函数(3)式就是要寻找的最佳权函数。
3 模型评价与加权回归
3.1 回归模型评价指标
建立回归模型,从一般的意义上讲有以下3个目的(刘璋温等,1983):
分析——对观测数据进行分析,以便描述存在于解释变量与目标变量之间的结构关系;
预测——以已知解释变量的值来预测目标变量的未来值或期望值;
控制——为使目标变量的值保持在一个理想的水平上,而适当调整解释变量中可调整的变量值。
在上述3个目的中,预测是最根本的。因为结构分析可以考虑为在更一般的条件下预测目标变量的变化问题,而控制可以考虑为针对解释变量的不同水平来预测相应的目标变量的值,以便从中选择最佳变量的问题。事实上,林业上的所有通用性数表的编制都可以看成是用于预测的超总体回归模型的建立问题。如何评价这类模型的优劣,一直是林业数表领域所面临的一个课题。
关于回归模型评价的常用指标,包括残差平方和Q、剩余标准差S、复相关系数R、修正复相关系数R?、参数变动系数(稳定性)、残差分布(随机性)、参数的可解释性以及信息量准则AIC和CP准则等(骆期邦等,1992;刘璋温等,1983;钟义山,1992;盛承懋等译,1989)。除此之外,笔者认为对用于预测目的的回归模型,尚需考虑以下4大指标:
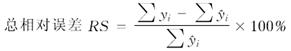 (7)
(7)
![]() (8)
(8)
平均相对误差绝对值![]() (9)
(9)
预估精度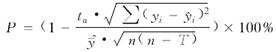 (10)
(10)
或,预估误差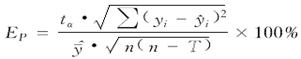 (11) 式中:yi为实测值;
(11) 式中:yi为实测值;![]() i为预估值;n为样本单元数;tα为置信水平α时的t分布值;T为回归模型参数个数;
i为预估值;n为样本单元数;tα为置信水平α时的t分布值;T为回归模型参数个数;![]() 为平均预估值,可由f(
为平均预估值,可由f(![]() )给出。另外,因为这类回归模型必须具有通用性质,需满足随自变量x从小到大时模型的上述指标应基本保持一致,所以还需分段对上述指标作出评价。
)给出。另外,因为这类回归模型必须具有通用性质,需满足随自变量x从小到大时模型的上述指标应基本保持一致,所以还需分段对上述指标作出评价。
应特别强调的一点是,因为相对误差公式一般表示为:
![]()
从而在林业应用上对(7)~(9)式过去几乎都是写成(预估值-实测值)/实测值,即习惯性地将实测值当成了真值。将实测值当真值正确与否,需视具体情况而定。如某一株D=20cm、H=15m的杉木,经实测其材积为0.24m3。如果用于立木材积的目测训练,正确的做法是将0.24m3作为该树的材积真值来检测每个人的目测水平;如果是用于立木材积表的编制,则0.24m3只是满足D=20cm、H=15m这一条件的某株杉木的材积实测值,在这种情况下不存在真值的概念,而只有实测值与预估值(或期望值)之分。误差在林业数表领域的应用基本上都是后一种情形,因此一般应采用前面给出的(7)~(9)式。
预估精度(10)式或预估误差(11)式是笔者提出的评价通用性模型的新指标,从后面的讨论将看到,它是反映模型预估效果的最重要的评价指标。它的成立需满足条件总体为正态分布这一前提条件。对于林业生产应用中的绝大多数情况,这一条件都是基本满足或近似满足的。
3.2 模型评价与加权回归
为了说明加权回归方法对建立通用性模型的重要性,现以一组实测数据为例,来对普通最小二乘法和加权最小二乘法得出的模型进行评价。
所用数据为杉木地上部分干物质生物量,采集自江西省德兴市的人工杉木林中。共计50株样木,来自6个样地,样地按幼、中、成3个龄组和中、好两个立地等级各分布1块。如果从建立立木生物量模型这一目的考虑,所用数据严格讲并不符合建模要求(后面将讨论到),但用作不同方法结果的对比是可以的。表1给出了常规生物量模型W=a(D2H)b两种回归估计方法的对比结果,表2列出了(7)~(10)式的评价指标值,其中包括将整个建模样本按胸径D的大小以株数平分为5段所算出的评价指标值。
从表1、表2可以明显看出,尽管加权回归(特指按前面的最佳权函数(3)式加权,下同)的残差平方和为普通回归的2.1倍,剩余标准差为1.4倍,但按(7)~(10)式所给指标进行分段检验的结果,加权回归模型明显优于普通回归模型。普通回归模型随自变量x从小到大各评价指标从劣到优,即主要只照顾绝对值大的样点,而对绝对值小的样点很少考虑。但是,加权回归模型却各段的检验结果基本一致,而且加权回归模型还有一个很好的特性,即总系统误差为0,这从(6)式可以推知。
表1 普通回归与加权回归估计的拟合结果
Tab.1 Fitting results of ordinary regression and weighting regression estimation
方法 | 参数估计值(变动系数%) | 统计指标 | ||||
a | b | Q | S | R | R* | |
普通回归 | 0.029074(22.72%) | 0.94180(2.68%) | 2455.23 | 7.1520 | 0.99144 | 0.99126 |
加权回归 | 0.069923(11.01%) | 0.83353(1.92%) | 5137.91 | 10.3460 | 0.98201 | 0.98163 |
表2 普通回归与加权回归估计的检测结果
Tab.2 Testresultsofordinaryregressionandweightingregressionestimation
样本范围 | 普通回归 | 加权回归 | ||||||
RS | E | RMA | P | RS | E | RMA | P | |
全部 | 1.26 | 958.00 | 25.59 | 94.36 | 4.20 | 0.00 | 14.18 | 92.30 |
第1段 | 43.35 | 543.45 | 54.35 | 38.36 | -2.86 | -4.86 | 10.47 | 83.60 |
第2段 | 33.05 | 400.12 | 41.84 | 61.38 | 4.15 | 75.82 | 22.92 | 77.67 |
第3段 | 5.74 | 65.24 | 8.14 | 91.45 | -6.79 | -72.34 | 9.88 | 91.54 |
第4段 | -4.67 | -58.41 | 16.03 | 86.10 | -6.87 | -91.67 | 16.35 | 85.71 |
第5段 | 0.49 | 7.60 | 7.61 | 91.72 | 10.76 | 93.06 | 11.28 | 85.56 |
需要说明的一点是,由于模型本身的参数是未知的(假定模型结构为已知——模型结构设计也是建模的重要环节之一,本文不作讨论),因此,只有事先得到其普通回归估计值,才能进行加权回归估计。严格来讲,以模型本身为权函数进行的加权回归估计,应该是权函数所赋参数值与回归估计得出的参数完全相等;如果不相等,应再以新的回归模型为权函数重新进行拟合。一般地,要达到完全稳定需经数次的反复拟合,而且参数越多,所要拟合的次数也越多。如上述表1中的例子,就经过了7次加权回归才使参数完全稳定不变(指5位有效数)。但是,从消除异方差这一目的考虑,经过1~2次加权回归就基本上具有齐性方差了,模型的总系统误差已接近于0。
加权回归估计与普通回归估计的结果之所以产生如此大的差别,根本原因在于求解模型参数的准则不同。普通回归是使Q=Σ(y-![]() )2最小,即保证总相对误差为0(由于非线性回归估计中的非线性模型是用泰勒级数展开式近似表示的,故存在一定偏差,使估计出来的模型其总相对误差并不等于0,可参见表2),必然优先考虑y绝对值较大的点;而加权回归是使Q′=Σ(y/
)2最小,即保证总相对误差为0(由于非线性回归估计中的非线性模型是用泰勒级数展开式近似表示的,故存在一定偏差,使估计出来的模型其总相对误差并不等于0,可参见表2),必然优先考虑y绝对值较大的点;而加权回归是使Q′=Σ(y/![]() -1)2最小,即保证总系统误差为0,考虑的是相对值,每个样点都同等重要,故必然会照顾到所有的样点。总之,不论理论分析还是实际对比结果都表明,通用性回归模型的建立必须采用加权回归估计方法。
-1)2最小,即保证总系统误差为0,考虑的是相对值,每个样点都同等重要,故必然会照顾到所有的样点。总之,不论理论分析还是实际对比结果都表明,通用性回归模型的建立必须采用加权回归估计方法。
关于回归模型的评价,Q、S、R、R?及参数稳定性等指标主要用于比较确定不同的模型形式,最终回归模型的评价则必须重点考虑(7)~(10)式中的指标值,而且其分段检验结果尤为重要。
4 收集建模样本的基本原则
要建立一个好的通用性模型,对建模样本是有一定要求的。如林业上一些通用性数表的编制,对样本资料的要求在部颁技术规定(林业部,1990)中都作了具体规定。但是也不难发现,其中对建模样本的要求仍然不是很明确,还有必要再作进一步探讨。
4.1 样本单元数
作为建模样本,首先涉及样本单元数的问题。文(中华人民共和国林业部,1990)中提到了一条原则:“样本单元数应根据各项因子的变动范围和精度要求按数理统计原理确定”,但是对精度要求都是用“系统误差”这一指标来规定的,如“蓄积量计量数表的系统误差不超过±3%”。这里的系统误差是(7)式的总相对误差还是(8)式的总系统误差或其它什么含义,并未明确。根据数理统计原理,体现精度要求的误差概念应该是(11)式所表示的预估误差,这样才可据此确定样本单元数。
作为通用性模型,预估精度是针对每一个预估值而言,因此必须落实到与每一个自变量xi所对应的预估值![]() i。对于林业上的常用模型,xi为连续变量,因此应该在其取值范围内确定m个能反映因变量yi的变化的点,再分别根据与这m个xi所对应的yi的变动系数及精度要求,确定各点的子样本单元数,m个子样本单元数之和即为整个建模样本的单元数。只有当各点的变动系数相同,其对应的子样本单元数才要求相等。
i。对于林业上的常用模型,xi为连续变量,因此应该在其取值范围内确定m个能反映因变量yi的变化的点,再分别根据与这m个xi所对应的yi的变动系数及精度要求,确定各点的子样本单元数,m个子样本单元数之和即为整个建模样本的单元数。只有当各点的变动系数相同,其对应的子样本单元数才要求相等。
上面只是考虑一个自变量的情况。如果有多个自变量,则情况要复杂一些,但原则相同。以二元立木材积表的编制为例,首先需定出m个直径值,再针对每个直径值定出k个树高值,最后按一定要求收集m×k个子样本,合起来形成整个建模样本。假定每个子样本有相同的变动系数(如10%),按±5%的预估误差要求(置信水平95%),则各需16个样本单元(取t0.05=2,实际操作时应随n作调整)。按最低限度取m=5、k=3,则共需240个样本单元。如果要求预估误差为±3%,且其它条件不变,则共需667个样本单元。一般情况下,材积变动系数会随D、H的增大而增大,因此,如果建模样本中对应较大D、H组合的点所取子样本单元数较少,则必然会造成大径级立木的材积估计值达不到预定的精度要求。
4.2 样本构成
样本构成指样本单元数随自变量的分布情况。仍以二元立木材积模型为例,样本构成涉及上述m、k的确定及每一个子样本中具体建模样木的选取。
关于径级数m和每个径级中的树高级数k,文(中华人民共和国林业部,1990)中建议分别在10~15左右和不少于3个。因为m、k的大小直接影响收集样本的工作量,提供一个最低限度指标是必要的。对于材积模型,因为其曲线变化趋势比较单一,故取m=5~8、k=3~5即可。如果是变化趋势比较复杂的模型(如“S”型生长曲线),可适当增加至m=7~10。在确定m、k之后,具体选取哪些径级和树高级时,应掌握如下原则:最小、中等和最大者必选,然后再在其间适当增选;目标变量变化规律未知时考虑等距均匀分布,变化规律已知时宜典型选取,其中变曲点处必选。由于树高级的确定是在已定径级基础上进行的,故应考虑影响树高变动的各种因素。
具体针对某一径级和树高级组合的子样本,其样木的选取必须考虑影响材积变动的各种因素,在根据各种影响因素划分的类型中去典型选样。因为异方差性的存在,笔者认为各子样本样木的D、H应尽可能地一致,以正确地估计其平均数的方差和变动系数。尽管整个样本看起来呈现离散性,但不会影响建模效果。相反,因为各子样本的收集都达到了建模要求,只要模型选取得当,其预估精度是肯定可以达到预定要求的。
样本资料的收集是建模的首要环节,其质量好坏直接影响建模效果。通过模拟数据的对比检验结果可以发现,一套理想的建模样本数据,不管是采用普通回归还是加权回归估计方法,其结果几乎是一致的。也即由一套好的样本资料所建立的模型,其总相对误差和总系统误差都应该接近于0。因此可以说,2种估计方法得出的回归模型的差异大小,在一定程度上反映了建模样本的质量好坏。
4.3 检验样本与精度检验
建立通用性回归模型时,一般要求在收集建模样本的同时,还另收一套检验样本。如文(中华人民共和国林业部,1990)中提到收集编表资料的另一条原则:“要同时收集编表和检验两套样本,用编表样本编表,用检验样本检验所编数表的精度。”检验样本的收集原则和方法类似于建模样本,此处只着重讨论检验方法及这一检验的必要程度。
利用检验样本进行所谓“适用精度”检验,必须分别径级进行。正确的方法应是先按(7)式算出总相对误差E′,然后判断它是否超过公式:
![]() (12)
(12)
的结果。式中,CV为检验径级的预估材积的变动系数,n′为该径级检验样本单元数,t′α为置信水平α时的t分布值(自由度为n′-T,T为模型参数个数)。如果不超过,则认为模型是可以接受的。
由(11)式知,(12)式中的变动系数CV可表示为:
![]() (13)
(13)
式中Ep为检验径级的材积预估误差,n为该径级的建模样本单元数,tα为置信水平α时的t分布值(自由度为n-T)。将(13)式代入(12)式,可得到接受模型的条件为:
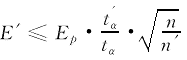 (14)
(14)
如果n′=n,则只要检验样本的总相对误差不大于建模样本的预估误差就行了。另外,(14)式还反映出了一条信息,即各径级检验样本单元数必须满足n′>T。
从上述检验方法可看出,整个检验行为并不能提出一个反映所建回归模型预估精度的指标值,而只是作出一个可否接受模型的判定。可以推断,只要建模样本的收集符合要求,就基本上能以(1-α)的概率作为接受模型的判定,也即作出否决模型的判定只是一个小概率事件。万一真是出现此种情况,也只能按要求去完善样本资料重新建模。因此,与其花费一部分工作量去收集检验样本,还不如在收集建模样本时多花点功夫以确保其质量。真正体现回归模型预测精度的,还是预估误差这一指标。
5 结论
样本资料收集、回归估计方法和模型评价是建立回归模型的3个重要环节。
建模样本单元数必须根据预定精度要求和目标变量的变动系数及变化规律综合确定。样本的构成关系到样本的质量,而样本的质量好坏将直接影响所建回归模型的精度。
加权回归估计方法是建立通用性回归模型所应采取的方法。任何回归模型的最佳权函数就是模型本身。以模型本身为权函数所进行的加权回归估计,一方面将所有建模样本单元同等对待,从而保证了模型的总系统误差为0;另一方面彻底消除了模型中可能存在的异方差性。
对回归模型的评价,除了残差平方和、剩余标准差、复相关系数、修正复相关系数、参数变动系数、残差分布图以及信息量准则AIC和Cp准则等等指标以外,还需考虑另外4大重要指标,即总相对误差、总系统误差、平均相对误差绝对值和预估精度(或预估误差)。
董德元,杨节,苏敏文等.试验研究的数理统计方法.北京:计量出版社,1987
刘璋温,吴国富.选择回归模型的几个准则.数学的实践与认识,1983,(1):61~69
骆期邦,宁辉,贺东北等.二元立木材积动态模型研究.林业研究,1992,5(3):263~270
盛承懋,李慧芬,钱君燕编译.应用回归分析.上海:上海科技文献出版社,1989
俞大刚.线性回归模型分析.北京:中国统计出版社,1987
曾伟生,骆期邦.二元材积生长率标准动态模型研究.中南林业调查规划,1992,11(3)1~6
曾伟生.关于加权最小二乘法中权函数的选择问题.中南林业调查规划,1996,15(1)54~55
曾伟生,廖志云.削度方程的研究.林业科学,1997,33(2):127~132
钟义山.回归模型优劣评价的几个问题.中南林业调查规划,1992,11(4):10~14
中华人民共和国林业部.林业专业调查主要技术规定.北京:中国林业出版社,1990
RESEARCH ON WEIGHTING REGRESSION AND MODELLING
Abstract: Taking weighting regression estimation method as the core, the heteroscedasticity of the general models used in forestry was discussed, and an optimal weight function was presented that could completely eliminate the unequal variance. Secondly, the model assessment was studied, and four important indices for commonly-used regression model assessment were presented, and the relationship between the four indices and weighting regression estimation was analysed. Finally, the collection of modelling sample was discussed, and the basic princinple for collecting sample data was presented.
Key words: Weighting regression, Modelling, Heteroscedasticity, Model assessment