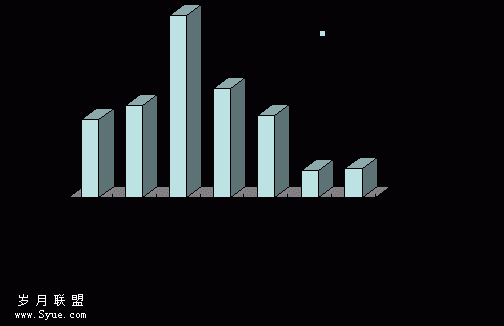LIDC中肺结节注释信息的提取及数据库的建立
【摘要】 目的: 对LIDC数据库的注释文件中有关肺结节的相关数据进行提取、整合、汇总,并导入到Access数据库表中。方法: 通过对LIDC数据库XML格式的注释文件的分析、解读,利用Visual Basic语言编程提取数据,并导入到Access数据库表中。结果: 数据提取和显示程序将LIDC中的68个病例的相关数据(如病例号、专家号、结节号、结节的各种CT征象、结节的X坐标和Y坐标等)加以提取和显示,并保存到数据库中。结论: 将LIDC数据库中包含的每个病例CT图像的XML格式注释文件导入到Access数据库中,较之纯文本格式的数据组织更加结构化,进而可以借助数据库强有力的数据管理和查询功能对CT图像上肺结节形态、位置、CT征象等进行查询和比较。
【关键词】 LIDC; XML文件; Access数据库; CT图像
1 引言
随着技术的不断、更新,现如今医生进行医学诊断的方法与模式已经发生了巨大的转变。与过去仅凭经验、惯例等不同的是,现今的医学诊断更多的倾向于科学的、数字化的精细诊断模式,其中最为突出的示例就是机辅助诊断及计算机辅助检测的飞速发展。
CT的计算机辅助肺癌诊断的研究证实,CAD技术可以为病变部位的探测提供有效的帮助,甚至可以在连续的CT检查中辅助确定病变部位是否稳定或是否发生了大小的改变。为了为各种图像处理或CAD技术的相互比较和测评提供一个数据库,美国国家癌症研究会(NCI)于2001年4月起陆续颁布了肺部图像数据库联盟(Lung Image Database Consortium,LIDC)。该影像数据库可以通过互联网访问和下载[1]。目前LIDC包括68个病例的约10000张全肺CT扫描图像(扫描层厚1.25mm~3mm,512×512像素),总容量超过6GB。每个病例对应一个文件夹,包括完整的肺部CT扫描图像(DICOM格式)100~300张,以及一个注释文件(XML格式)。在注释文件中给出了4名放射学专家对每张CT片中出现的结节的定义,包括结节的主要CT征象,如毛刺征(Spiculation)、分叶征(Lobulation)、钙化(Calcification)等以及结节的恶性度(Malignancy)。
由于LIDC数据库中病例的注释文件是采用XML格式编写的纯文本文件,所有注释内容均以标识符加以区分,不具备数据的查找、统计等功能。本研究将LIDC数据库所提供的原始XML注释文件信息加以提取,建立相应的Access数据库进行存储,方便其他研究人员的使用。
2 方法与实验
2.1 XML注释文件
2.1.1 XML文件 XML文档是由元素组成的,每个元素都包含一个“起始标记”(如
2.1.2 LIDC提供的XML格式数据示例 在每个病例的所有CT图像后面都有一个注释文件,其中给出了4名放射学专家对每张CT片中出现的结节的定义,包括结节的主要CT征象,如毛刺征(Spiculation)、分叶征(Lobulation)、钙化(Calcification)等以及结节的恶性度(Malignancy)。对于大结节(直径≥3mm的结节),给出了轮廓点的坐标,小结节(直径<3mm的结节)给出了中心点的坐标。所有信息的含义定义在一对标签中。一个典型的XML文件片段如图1所示。
2.2 存储LIDC中肺结节数据的数据库
从每个病例的原始注释文件中提取如表1所示的基本信息,并写入相应数据库表的字段中。表1 存储LIDC中肺结节数据的数据库表的结构注:如CT图像上某一结构为小结节(直径小于3mm)或非结节,则上述字段4~12的取值均为0。
2.3 提取LIDC中肺结节数据
Step 1 提取患者号,以
Step 2 提取专家号。注释中未给出放射学专家编号,但是通过对文件的大体框架的分析可以看出,每一对
Step 3 判别是否为结节、非结节或是另一名专家的诊断。同时搜索3个标识符
Step 3.1 如果搜索到
Step 3.1.1 如果指针搜寻的结果为
Step 3.1.2 如果指针搜寻的结果为
Step 3.1.3 如果指针搜索结果为,即说明该结节数据读取完毕,须将所有已读信息保存至实现定义的数组中,等所有数据读取完以后一起输出显示。
Step 3.2 如果筛选结果为
Step 3.3 如果筛选结果为,表明已读取完一个专家的所有数据,可以开始继续读下一个专家,直至整篇文档读取完毕。
3 结果
3.1 提取注释文件的程序
在如图2所示的程序窗口,“文件”菜单用于打开病例数据,在显示的对话框中选择病例文件。程序将自动提取文件中肺结节的信息,并将它们显示在一个文本框控件中。
“显示”菜单用于以报表形式显示保存到数据库中的数据,如图3所示。
3.2 建立的数据库
在LIDC数据库的68个病例中,4名放射学专家共标注大结节331个(累及CT层数1589张)、小结节920个(累及CT层数920张)、非结节病变2370个(累及CT层数2370张)。对每张CT上的大小结节及非结节病变,用一条记录保存其相应信息,所以整个数据库共68张表、4879条记录。此外还有保存大结节轮廓点坐标的文本文件1589个。
4 结论
LIDC数据库是在整合了多位放射学专家对多份病例的CT扫描图像的意见的基础上建立起来的,为肺部图像数据的收集制定了一个指导方针,为今后的研究打下坚实的基础。LIDC数据库的建立为早期肺癌诊断提供了强有力的辅助手段,灵活的应用LIDC数据库,可以更快更好地评价机辅助诊断和检测算法的性能。
本研究将LIDC数据库中包含的每个病例CT图像的XML格式注释文件导入到Access数据库中,较之纯文本格式的数据组织更加结构化,进而可以借助数据库强有力的数据管理和查询功能对CT图像上肺结节形态、位置、CT征象等进行查询和比较。