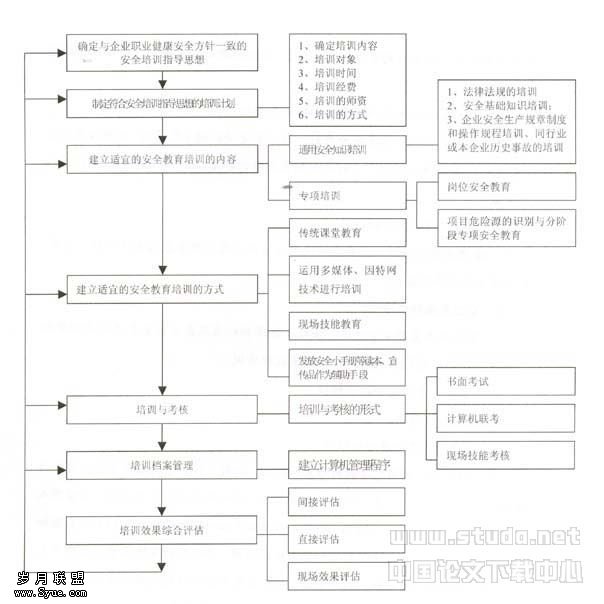
数据挖掘在高校资产管理中的应用
[摘 要] 进行高校资产数据挖掘与分析研究,能更好地为高校管理、高校决策提供科学依据。本文分析了高校资产管理的现状与特点,构建了高校资产数据仓库雪花模型,挖掘出高校资产管理指标之间的关联规则,并对该数据挖掘模型进行评价,在实际应用中取得了良好效果。
[关键词] 高校资产;数据仓库;数据挖掘;雪花模型;关联规则
1概述
高校资产信息管理系统中的数据客观记录了高校所有资产的历史情况和现状,同时也隐含着各种资产的特点,蕴藏着学校的发展规律和趋势。然而现阶段高校各部门一般采用不同的数据库,数据整合困难,无法实现不同系统跨平台信息的共享与交互,无法实现面向主题的数据分析,从而无法更多更好地利用数据资源。为了充分利用这些积累的记录信息,从中发现有用的知识,获得潜在的规律,为高校资产管理和决策提供科学参考,需要建立一个分析决策系统。而实现分析决策系统的主要技术就是数据仓库和数据挖掘。
数据挖掘是指从大量数据中提取或发现知识[1]。数据挖掘通过一些模型和智能方法,从大量数据中提取、识别用户真正感兴趣的、新颖的、潜在有用的模式,提供给用户作为决策的依据和参考。
数据仓库与数据挖掘技术已被广泛应用于商业领域,但用于高校资产管理领域的却很少。本文通过构建高校资产数据仓库模型,对资产管理指标的相关属性进行分析,通过数据挖掘得出了资产管理指标之间存在的一些强关联规则,各规则的信任度均达到70%以上。
2高校资产数据仓库逻辑模型
数据仓库多维数据集能对数据仓库中的所有数据提供统一的和集成的视图,可作为传统报表、联机分析处理和数据挖掘的基础。数据仓库的逻辑模型包括事实表和维度表,事实表描述挖掘主题包涵的多个角度,维度表则从不同角度描述挖掘主题的相关数据[2]。结合高校资产挖掘主题与资产信息数据的特点,高校资产数据仓库的逻辑模型采用了雪花模型结构,如图1所示。“资产数据事实表”与“部门表”、“资产编码表”、“资产分级表”、“时间表”4个主维度表关联,“部门表”、“资产编码表”和“资产分级表”还分别有“上级部门表”、“资产类别表”和“资产指标表”3个二级维度表,其中“资产类别表”还有三级维度表“资产大类表”。建立这种多级维度表不但可以降低数据仓库的数据冗余度,减少数据量,保证数据一致性,还有利于改变数据粒度,实现灵活粒度的数据挖掘。
数据挖掘如果建立在原始数据水平或较低的维层次上,则此时数据粒度小,挖掘速度慢,挖掘得到的规则繁杂,难以理解;如果数据从低维层次抽象到高维层次,对较高维层次数据进行挖掘,则此时数据粒度大,挖掘速度快,得到的规则泛化程度高,便于宏观理解。因此通常在高维层次上进行挖掘,必要时再进行较低维层次上的挖掘[3]。
3数据属性归约及取值
3.1数据属性归约
高校的资产数据按教育部规定分为16类,对这些资产进行管理非常繁杂,根据实际我们选取以下4个管理指标以利于资产数据挖掘:
(1)资产购建价值,用A表示。它是购买或建造资产的原值。理论上同类资产价值高的要比价值低的使用寿命长。
(2)资产剩余使用年限率,用B表示。每种资产都有一定的使用年限,使用中每年提取折旧,当到达规定的使用年限后该资产一般只剩下很少的残值,原则上也就报废了。资产剩余使用年限率反映了资产的剩余使用年限,是资产管理的一个重要指标。
(3)资产每年使用率,用C表示。不同的资产每年的使用率各不相同,有的长年使用,如房屋和家具等;有的一年才使用几次,如某些实验仪器设备。同样的资产使用次数多的肯定比使用次数少的容易坏。
(4)资产质量评估值,用D表示。每年由相关人员对每种资产进行一次评估,评估该资产当时的性能和好坏程度。
3.2 资产管理指标数据的取值
对资产管理的4个指标值采用统一的分级,分为“一级”、“二级”、“三级”、“四级”、“五级”5个等级,分别用1、2、3、4、5表示,对指标数据的取值采取分类转换。
(1)同一类资产的购建价值会因品牌种类、购建时间、市场行情等因素的影响而不同,一线品牌中的高档资产购建价值肯定高,定为一级;一线品牌中的中档资产或二线品牌中的高档资产定为二级;二线品牌中的中档资产或非品牌中的高档资产定为三级;非品牌中的中档资产定为四级;淘汰产品、试用品或非正规单位生产的产品定为五级。
(2)会计上对资产的使用年限没有明确规定,资产折旧的年限通常是分大类按税务规定进行计算的:一般房屋为20年;生产设备为10年;工具、家具为5年;电子设备为3年;低值易耗品为1年。这个规定与实际使用年限相比是偏低的,因此将规定使用年限近似平均分成5个区间,其中第五区间包括规定使用年限到期后仍在使用的那段时间。每个区间数按年取整,如不为整则在购建初的第一区间多分配一点时间。资产剩余使用年限率=(税务规定使用年限-已使用年限)/税务规定使用年限。将数值型数据离散化后分区计算资产剩余使用年限率,结果各类资产剩余使用年限率基本近似,各区间取值(1,0.8],(0.8,0.6],(0.6,0.4],(0.4,0.2],(0.2,0],依次定为一级、二级、三级、四级、五级,如房屋从新建起使用(0,4]年为一级,(4,8] 年为二级,(8,12] 年为三级,(12,16] 年为四级,>16 年为五级。
(3)资产每年使用率由使用资产的负责人在每年年中依据使用记录对每种资产作出评价,平均分成五级,使用最少的为一级,它的使用寿命相应就长;使用最多的为五级,它的使用寿命相应就短。
(4)对资产质量进行评估的相关人员在每年年中时对每种资产的性能和好坏进行一次评估,评估的结果值也分成五级,最好的为一级,最差的为五级,五级意味着不能再使用。
根据以上分析,高校的每种资产可以描述如下:(资产编号,购建价值,剩余使用年限率,每年使用率,资产评估值)。例如:(415012,A1,B3,C1,D2)表示资产号为415012的资产,其购建价值一级, 剩余使用年限率三级,每年使用率一级,质量评估值二级。
实例:2008年某学院的实验室正在使用的计算机有126台,当年各项管理指标分级情况和计算机数量之间的关系如表1所示。
4数据挖掘
本文对高校资产进行关联规则挖掘,频繁数据项集的生成采用Apriori算法。
4.1 Apriori算法及其特点
关联规则挖掘是数据挖掘的一个主要研究方向,目的是发现海量数据中数据项集之间存在的潜在关系规则。先识别出频繁出现的属性值集,也称频繁项集,然后再利用这些频繁项集创建描述关联规则[4]。关联规则中有支持度和信任度两个重要的度量,为满足一定的要求,用户需要指定规则必须满足最小支持度(minsupport)和最小信任度(minconfidence)两个门限[5]。关联规则的挖掘分为两个步骤:①发现频繁项目集: 找出所有大于或等于用户指定最小支持度的最大频繁项目集,又称强项集;②生成关联规则: 根据用户指定的最小信任度利用频繁项目集生成关联规则,该规则是满足最小支持度和最小信任度的强关联规则。