�����������Ӧת��
��Դ����������
ʱ�䣺2010-08-12
1���淶��Ӧ����ʽ���ֵĹ淶
�ƶ����淶���ֱ�����Ӧ�Դ�½���е���ʽ����Ϊ���ݣ��Ȿ���Ǻ������ʵġ����ǣ����ijЩ��ͼ�Ƶ���ʽ���֣����Żָ���20����50�����ǰ��״̬�ĸ��ֹ۵㣬ȴ�ֲ��ò���˵�ϼ��䡣
����ʽ�����Ѿ�ͨ���˰�����ͣ������������ڹ������֮�У���Ϊ��12�������ճ�����ϰ�ߵ�һ���֣�Ҫ�����Ƿ�������ϰ�ߣ��϶�������ġ�
����ʽ������ȫ�ܹ�ʤ����д������ĵ�ְ�𣬲�����ijЩ������Ϊ����������������ѧ˼��ĺͷ��ӡ�
�ǰ����������������ʽ������д��ӡˢ�ĸ����Ļ��ɹ����Ѿ���Ϊ�ڶ�ͼ��ݵ������ݲأ�һ���ϳ�������۽���������
������Լ��ʵ��������ܹ�����ʽ����һһ��Ӧ�Ļ�����ʽ���ּȲ����Ϊ�̳йŴ��Ļ��Ų����ϰ���Ҳ�����Ϊ�����Ļ��������ϰ����������Ϊ������Ϣ���������ϰ���
2���Ϻ���Ӧ�á�һһ��Ӧ��
����������һ���ΰ��ϵͳ���̣���Ҫ���ǵ�����ܶ࣬���Ϻ��ֵġ�һһ��Ӧ�����⣬��������֮һ����������û�аѡ�һһ��Ӧ����Ϊ����������Ŀ��֮һ�������һ�������ġ��ǶԳƷ����֡��͡��ǶԳ������֡���������֮һ�����Ӷ�����ǰ�ĺ�����Ϣ�����ͺ���ʹ�ô���������㡣�������������ֺͷ����֣�����һ����û������������ν����ĺ������ι淶�����������ǵ�����Ŀ�꣬Ȼ���ڵ�ǰ���ǻ����ò���������˻���ʹ����ʽ���ֵ�����£������Щ����Ӱ���Ӧת���ķǶԳƷ����ֺͷǶԳ������֣�������ͨ��ʽ��������ʽ���ֵĶ�Ӧ��ϵ��������ΪҪ�������顣
��һһ��Ӧ�������DZ�����ԡ�һ�����ơ�֮�����ʵ��Ҫ��
�������ʿ��Ϊ�����ֲ���ѧϰ����Ҫԭ�����뷱���ֲ���һһ��Ӧ������ܹ�һһ��Ӧ����Ϥ�˷����ֵĸ۰�̨ͬ�����ͺ�����ѧ������֡���ˣ�ֻ��һһ��Ӧ�������չ˵��۰�̨ͬ��������ϰ�ߣ����ܷ���ؽ��������ı����ת����ֻ���ܹ�������ת�����ű������ͨ���ѧϰ��ֻ�б������ͨ���ѧϰ�����ܼӿ���ͬ�еIJ��������ܼ��ٸ۰�̨ͬ��������ʽ���ֵIJ�����ֻ�������Ǿ߱��˸߶ȵ���ͬ�У����ڷ����ض�����ǿ�ȵؽ�������ʽ���֣�����ʵ�����������ϵġ���ͬ�ġ�����ʼ��Ϊ�ˡ���ͬ�ġ�����ϧ��������塱���������ڵ�����������в�ͨ�ġ��ӳ�Զ����ֻ���ڳ���˽⡢��ѧϰ�Ĺ����У��������������飬���ܴﵽ�Ծ���ͬ�ľ��硣�ȵ���ʽ����Ϊ���۰�̨ͬ���߶���ͬʱ��ʵ�����������ϵ���ͬ�ģ�Ҳ�Ͳ��ڻ����ˡ����á�����ƴ����������˵�����ܵ������������ӣ������DZ�̨��ͬ�������ˣ��ؼ������ڡ�����ƴ���������кܸߵĹ�����ͬ�ȡ����룬ֻҪ��ʽ���ֵĹ�����ͬ�ȴ����ߣ��������ʽ���֣�������ƴ���������Ľ��죬Ҳ��������ʽ���ֵ����졣
���Ķ����飬�̳��Ļ��Ų���Ҳ��ʹ���Dz��ò������ʽ���֡�
��ͳ���Ļ��伮��������ʽ����ӡˢ�ģ�Ҫ�̳��Ļ��Ų����ͱ�Ȼ��Թ��飬�ͱ���Ҫѧϰ��ʽ���֡�����Ȼ������ͨ������ڵ��£����Ͼ���һ������Ҫ��������������˿��ܻ���Ϊ�����ǿ��ѹŴ��伮��������ִ��ģ���ҾͲ�����ѧϰ��ʽ�����ˡ�Ȼ����Ҫ����ʵ����һ����ΰ��ͼ��������ô����١��ݱ��������ҹż���������滮���ŵ�һλ������Ա��������߽��ܹż�������ʱ˵��Ŀǰ�ڹż����ֻ��������棬���һ�û�������߳�̨����Ϊ��Щ����ļ����ϰ������ȣ�������û�й���ͳһ������Щ�ñ�������Щ����������δ����ȷ������Σ��������ת���ɼ����Ϊһ���о����⣬Ŀǰ��У��ί���뱱����ѧ�������ⷽ����о������ʹ����ת�����Ϲ����������ֹ���ίԱ���Ҫ����̽��֮�С��������ֿ��������⣬���硶�����ֵ䡷����Щ���ֲ����ڵ�������ʾ���ż����ӳ�����ԭ��Ͷ��ܴ�����Ҫ����ѣ�Ҫռ�г��������ǻ������ٷ���ת�������ֵ����⣬η���������Զ����ġ�
�����ܹ�ʵ�֣���������ִ��ĺ�Ȼ�ᶪʧ�����Ļ���Ϣ��Ʃ�������Ļ���Ϣ�ȡ�Ʃ������Ҫ��֤һ�������ǴӺ�ʱ��ʼ���ֺ�ʹ�õģ������ܵ��ǶԳƷ����֡��ǶԳ������ֵķ��ţ���������Ը�Գ��������ھ�������������˼��ͬ�ġ��Y���롰�ȡ������ᡱ�롰�����Y���롰�������֣�����ʽ���ֵ��ı��ж�����ˡ��ȡ����������������֣���ˣ�Ҫ����ҡ��Y�������ᡱ�����Y�����ֵ�������������û�п��ܡ���˵��һλ�ڹ��ڳ�����Щ�飬��������Щ���µ�ר��д��һƪ��Ϊ������Ů���ں���͵����еĶԱȡ��ĸ��ӣ������ǣ������У��ӡ�Ů�����ӡ�ĸ�����ֶຬ���塣�Ȿ���ɺ�ǣ�����ȴ���ˡ�������Ϊ������˵�����ӡ�ĸ�������塱��ʵ������ʽ���ֵġ��������±߲����Ǹ���ĸ�������Ǹ����㡱�����ּ�����������һ����д����ĸ������������������ֵġ��о����������˵����ͨ���ִ��ı����˽�Ŵ��Ļ����������Ե��˽�ǿ��Եģ���Ҫ��ϸ�о��Ļ������������ĹŴ��Ʊ����漣�ſ���ס��Ҫ����һ���Ŵ��Ļ�ͨ����ѧ����ʽ���֣������Dz�����ܵġ���Ҫ��ʹ�ִ����ܹ��ܷ����ѧ����ʽ���֣������Ϻ���һһ��Ӧ���ת�������������ѡ��
��֮����һһ��Ӧ���������Ǹ�Ч�����ʵ�ѧϰ���о��Ŵ��Ļ��Ų��ı�ȻҪ��ֻ��һһ��Ӧ���ִ��˲Ų��ᱻ���۸��ӵĶ�Ӧ��ϵ���������˳�������ʽ���ֵ��ż������ܷ����תд���ֹ��Ļ��Ų���
�ǡ�һһ��Ӧ����Ҳ�Ǻ�����Ϣ�������ı�ȻҪ��
������Ϣ������������ʹ�õĵ����ֿ⣬ҲҪ���������ֺ�����ϵ�ܹ�һһ��Ӧ���ת�������ڲ���һһ��Ӧ���ת�������ֿ�ı��ƴ�����˵�����ķ��ա�����˵������ת������ֻ�������˼�֮�䣬�������ڵ��Է��棬��ʵ���ǡ�����֮������
�����ڵ�ͨ�е��ַ�����Ҫ��������һ������6763���ֵġ���Ϣ�����ú��ֱ����ַ���������������GB 2312��80����һ������20902���ֵġ�����������չ�淶����GBK����ǰһ���ַ���ֻ����������֣���֮���Ļ���һ��ר�շ����ֵġ���Ϣ�����ú��ֱ����ַ���������������GB/T 12345��90����ԭ���Ϻ����ǽ�GB 2312��80�еļ�������Ӧ�ķ������滻���ɣ���Щ����ķ����־����뱻����ļ�����ͬ�ı��롣���ڷ������滻���ֵ�ԭ��GB/T 12345��90 ע����������ԭ���ϰ��ա������ܱ��������з���������ֵĶ�Ӧ��ϵ�����滻������GB 2312 �У����� 60 ������ּ���������� 103 ������Щ��������ָ��ݷ����ִ���ϵͳ����Ҫ������ 88��89 ��������ʵ��һ��������ȫȷ����Լ������֮һ���Ҳ�δ���������η���88��89 �������ǽ������η�����88��89 �������磺���ᡱ�롰�S�������ּ�ʱ�����ˡ��S���֣��ԡ��ᡱ��������� GB/T 12345 ��������ġ��S���֣���Ϊ���ᡱ�ķ��壬���� 23-65���������ᡱ������ 88-19��������·����������ν 103 ����������ĺ��֡���ֻ�Ǿ�6763�����ֵķ�Χ���Եģ���7000ͨ���ֵķ�Χ���ԣ�Ӧ����132���������ġ��ǶԳƷ������ܱ���������δ���������ϳ����Ĵ��������֡����磬���N���͡�ꅡ�����Ϊ�������������֣���ֹͣʹ�ã�GB/T 12345 ��δ��¼������ֻ�����������ijһ��������ģ��硰��Ǭ�����ᡢ��ⷡ�ô�ᡢ��춡����š���ߡ�����硱�ȣ�GB/T 12345 �Ĵ������ԵñȽϻ��ҡ�����GB/T 12345 ��������� 27-79����ⷡ����� 66-23���� GB 2312 ������ͬ�����ԡ����Ӧ������ԡ�ⷡ���Ӧ��ⷡ�����һ������ǣ�GB/T 12345 �����ᡱ���� 26-83����Ӧ GB 2312 �ġ������������� 65-65����Ӧ GB 2312 �ġ��ᡱ�������硱���� 53-87����Ӧ GB 2312 �ġ������������������� 65-71����Ӧ GB 2312 �ġ��硱����Ȼ����ǡ������Щ����Ĵ��ڣ����������Ϻ��ֲ���һһ��Ӧ������صģ����ǻ�ר����ˮƽ�������ƽ����һһ��Ӧ�����⣬һ�����ⶼ��ӭ�ж��⡣
�ڶ����ַ�����GBK����һ�������� GB 2312 ������ݣ�����֧�� ISO 10646.1 ���ʱ��ij������µı���ISO 10646 �ǹ��ʱ�����֯ ISO ������һ����������� Universal Multiple-Octet Coded Character Set����� UCS������½��Ϊ��ͨ�ö��λ�����ַ�������̨����Ϊ�����ö��λԪ������Ԫ���������� Unicode ��֯�� Unicode ������ȫ���ݡ�ISO 10646.1 �Ǹñ��ĵ�һ���֡���ϵ�ṹ�����������ƽ�桷���ҹ� 1993 ���� GB 13000.1 ���ұ�����ʽ�����Ͽɣ��� GB 13000.1 ��ͬ�� ISO 10646.1����ISO 10646 ��һ�����������ϸ������Ե�������ʽ�Լ����ӷ��ŵı�����ϵ�����еĺ��ֲ��ֳ�Ϊ��CJK ͳһ���֡���C ָ��J ָ�ձ���K ָ���ʣ��������е��й����֣�������Դ���й���½�� GB 12345�����ִ�����ͨ���ֱ����ȷ������ĺ��ֺͷ��ţ��Լ�Դ��̨��� CNS 11643 ���е� 1��2 ���棨������ͬ�� ����ַ������Ƴ�������Ӧ��ͨ�ú��ֵ���Ϣ���������⣬Ϊ�˽������Χ�ڵĺ�����Ϣ���������⣬ISO/IEC 10646���պ�ͳһ���뺺��Unified Ideographs Extension B���������֣�Ҳ�Ѿ����壬����IRG�Ͻ�ISO�����ʱ�����֯��WG2��SC2��2001��8��1�ճʱ�ISO���鴦������ISO/IEC 10646-2��2001�������档��ǰ��ISO/IEC 10646-1��2000����2000��10��5�ճ��湫����������ISO/IEC 10646�����뺺�֣���������������Σ��ѳ����������������Ϊ�������ġ����⣬���ܺܺõ�����������غ���ʹ�õ���Ҫ��������ָ�о����棬������Ӧ�ö��ԣ�Ŀǰ��½����BIG-5 ����Ϊ������û�н���GBK �淶�ļ���
������ڣ��ֿ���Ȼ���ˣ�����һһ��Ӧ�����Ⲣδ�����������û��һ��ͳһ�Ĺ淶�ֱ�����ʹCJK�д�������Ż������Է����ϵIJ��淶�֡�����GBK �淶��Ҳ�з�ӳ�����磬�д�����Ӧ�����Ƽĺ��ֲ�û��������Ӧ�ļ��֣����硰�M�������x�������r�����֣���û����֮��Ӧ�ġ��������ԡ����õ���д��ʱ��������������֣�ֻ���������֡�Ȼ���ֹ����֣�������ʱ������Ч�����ѣ����Ҳ��������˹��������Ͻ����������ɸ����ֵ���Ϣ�����ͽ��������˲��㡣���������ǣ����ڼ��ֺͷ����ֲ���һһ��Ӧ���ڼ����ı��ͷ������ı��ת����ʱ����ʵ����ȫ�Զ�������ʱ���ò����Զ��֣�����жϴ��������Ӱ���˺�����Ϣ������Ч�ʡ��������Ȼ�ųơ��������ܡ���ʵ������ֻ�ʺ����й���Ķ�������Ժ�����ķ����ϵ���κ������������������ƾ�����Ʃ��Microsoft Office2000����������Ȼ�����ܻ��ķ�����ת�����ܣ��ܸ���������������Ӧ������ѡ����ת������Ԥ���趨�Ĵ������Ϊǰ��ģ����趨֮��Ĵ��������Ϊ�������ʵ�����й����һһ��Ӧ�������뷱��ת����ص����⣬��������練�ơ�
��֮��ֻ�����ƽ����һһ��Ӧ���⣬�����ĺ����ֿ����ʵ��û���ϰ����ת��������������ר���Ǵӷ���ת���ķ����н��ѳ������Ӷ������ڳ�����ʱ��ȥ�����Ǹ�Ӧ���������顣���ʵ����һһ��Ӧ���Ϳ���������Щ���������ޡ��������ޡ��ķǶ�Ӧ�֣��Ӷ�ʹ�����ֿ�������������ʣ����ֵ���Ϣ��������Ϣ����Ҳ����ø�Ϊ���㡣
3�ǶԳƷ����ֵ�����������ƽ��
��ͨ��ʽ��������ʽ���ֵĶ�Ӧ��ϵ����Ҫ�����������Ҫ������ŷǶԳƷ��������⣻�ƷǶԳ����������⡣
�������½�ˣ���ʹ�÷�����ʱ���ֳ�����Ц������ѡ�д�ְ塱�����ɡ�����雡����ѡ��ʺ����ɡ����ᡱ�ȣ��������ڷ����ֲ���һһ��Ӧ�ϡ����維���������ԣ��е��˲������е��ַ���ת�����ǵ�һ��Ӧ��ϵ������������档���ڵ�һ�������ŵ�̨���ݳ���������д���䡰�����ɵġ��ɡ��������ɵġ�����֪���Ȿ�����������֣�������һ��һ��Ҫ�Ե����Ļ������Ū�ɳ�����Ц���Դˣ����������������ĵ�����о��������ˡ��ǶԳƷ����ֶ��ձ������������Ľ���ͨѶ������ۣ���53�ڣ��������һ�����ǶԳƷ����ֵĵ������������������Ľ���ͨѶ������ۣ���65�ڣ�������Ҫ�������£�
�š��ǶԳƷ������ܱ���
�������ǵĵ���ͳ�ƣ���7000ͨ���ַ����ڣ����зǶԳƷ�����117�顣�����Ͽ��Է�Ϊ��
��һ�������Ӧ��������ģ���һ�������Ӧһ�����壬��������÷�������ͬ�ģ���һ�����������ֻ��ͷ�ġ����庺�ּ��±���
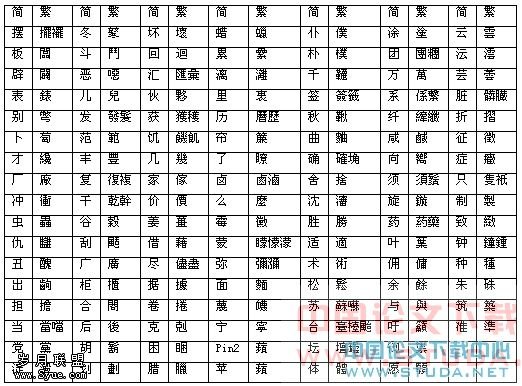
���У�����13�鲻����ȷ�ء���ת������104�鲻����ȷ�ء���ת������
ׇ�����ţ��������������� Ǭ���ɡ�Ǭ���x���ϡ��� ⷣ��ⷣ�
�壨�衢�壩 �w���ˡ��w�� �t���ˡ��t���N��ô���ᣩ �O��ƻ��Pin2��
�N���ࡢ�ţ� ߡ���ۡ�ߡ�� �磨�����磩��117�鷱�����У�ͬ��������ռ�˾��������Ʃ�磬��ֻ�С��ġ�ֻ���͡�һ�b���ġ��b�������^�ġ��롰���ġ���������������ġ��ᡱ�롰�ʺġ������ɸꡱ�ġ��ɡ��롰�Ŏ֡��ġ��֡��ȵȡ��Ϲ�ʱ�������٣���û���ֵ䣬д��ʱ�Ҳ���ȷ�����֣��ö�����ͬ���������棬���������ͷʹ�ġ�ͬ���ٽ衱���ֵķ����DZ仯�ģ���ͬ�ֵķ��������Ų�ͬ�ı仯��������ǰ������ͬ���֣��������Ϳ������ܴ�ʹ�����Կ�����ԭ�����ĸ��ֵĴ���Ʒ�����ǽ�����Ϲŵ���ѧ��Ʒ�����������кܴ���ϰ����ܶ���֣��ڲ�ͬ�����¡���ͬ�Ķ����е���˼��ͬ����Ϊ�����������ֵĴ���Ʒ�������������ˣ������ֵ䣬�ֵĶ�������˼�����ع̶������������Խ��Խ���ˡ������Ƕ����֣����ǵĶ���������Ҳ������ȶ��ġ�������ˣ�һ�ֶ������������Ǻ�������Ū�IJ��֣��������ֵ��˶�����������������������ͬ������������������ַ��ϵĴ����ˣ���̫�װ��������������������ǽ�������������֡��� ���ּ�ʱ���Ѻܶ���˼������ɶ������������Ƶļ����֣���һ���ʻ����ٵ��������棬ʵ����������Ϊ�����조���֡�����ˣ���Ȩ�������������£��ָ�ijЩ�ֵı�����ò���Ǻ��б�Ҫ�ġ�
�������IJ���ͷ���
���鰴���¾��岽��ͷ�������������
�ٷϳ����ܶ�Ӧת���ķ����ϵ�������ܹ���Ӧת���ķ����ϵ��
�ڷϳ������ϵ��������岢��ķ��壬ԭ���ָ�Ϊ�����֣�
�۷����ָֻ�Ϊ�����ֺ������Ƽļ������м�
�ܷϳ������ϵ�����ҵ��µĶ�Ӧ����ģ������齨�����ϵ��
�ݷϳ������ϵ��������岢�棬���Ҳ����µĶ�Ӧ����ģ��ѷ�����Ϊ������ȡ����
��Ԥ�ڽ����
�ٿ��Ա���ԭ�з����ϵ���У����ڡ��[���������������㡪�R���@���������������M�������v��±���u���֡�����ǩ�������ա��K��̳�������š��F���ˡ��w���롪횡�ҩ��ˎ���ࡪ�v���ӡ��R����19�顣
����Ҫ�����齨�����ϵ���У��������ˡ��Y���e���ѡ���������������4�顣
�۽�������ϵ����Ҫԭ���ָ�Ϊ�����ֵķ������У����ա��Y���l���}���֡��Y���ᡢ���������ס��M�������K�������ԡ��w���t���������������N�������W��Ǭ�������Ρ��c���١��m���g���T���S���~��Ġ��ߡ���硢�B����38�֡�
�ܽ�������ϵ���Լ�����ƫ�����Ƽķ������У����o��雡��l���u��ׇ���i�����������W�������r�������F�������I���O���`���y���D���ա��U�������a���y���P��曡��N���@��犡���29�֡�
�ݱ���Ϊ������ȡ����ʹ���ʸ���У��������N���S���n���x���h�������h���f�������S���͡��x���V���E�������ġ�ޒ���|�������n�����������q���`���V���㡢�a���F���_���_���w���f������ș�����c���R���d���n���녡������|���Y���}���b���u���N���p���ʡ���51�֡�
4���������ֵ�����Ӧ�����õ�
�����������Ĺ�ϵ�Ͽ����������������ࣺ�ž��������֣��ư��������֣��ǽ�����������֡��������������˲�ȡ��ͬ�ķ�������������
�ž��������ֵĸ�����֮���ǡ���ͬ��ͬ���Ĺ�ϵ������ʹ���ĸ�������ʾͬ�������壬��ͬ���Ķ�������ˣ���ʹ�����Ϻ�����ϵ��ѡ���˲�ͬ���������Σ�Ҳ����Ӱ�����Ķ�Ӧת��������ͳһ�淶�ĽǶ�˵����Ȼ���Dz���ͬһ��ȡ��Ϊ��ã���Ϊ����������ν��һһ��Ӧ���������ˡ�
�ƽ��������������Ȼ���������ң��������㣬���Ͼ����в��ص㣬���ֻҪ���������÷ֻ��������ֶ��գ�Ҳ��������ν��һһ��Ӧ�������⡣��Ȼ��������������ֺ�����ϵ�У�ֻҪ��һ��û�Խ�����������ֲ��÷ֻ���������Ҳ���Ϊ��Ӧת�����ϰ�֮һ��Ҳ��Ҫ���Թ�ע�����磺
��b��ng��b��ng��p��ng��p��ng���ob��ng��p��ng
����ֻ�ڶ�b��ngʱͬ�壬����������������ྶͥ������˲��÷ֻ������ö��߲��沢�á��������һ���������ȡ�����o����ʹ���ʸ��۰�̨�ֶ��߶������Ļ�����Ȼ��ɶ�Ӧת�������ѡ�
�Ƕ��ڰ��������֣���������÷ֻ�����������ÿ���ֶ��ֵ�һ�������壬������ͷ�����������������������������һ���ģ�Ҳ��������ν��һһ��Ӧ�������⣻������������ֶ�����ȡ�ᷨ��ѡ������ͬ���������Σ�Ҳ��������ν��һһ��Ӧ�������⡣��Ȼ������������ֺ�����ϵ���������ָ������˲�ͬ��ȡ�ᷨ�������������˲�ͬѡ�ͱض����¶�Ӧת�������ѡ����磬��ǘ�����������ϱ����������е������֣��������ʽ�����б�ȡ����������ʽ�����б��������ͱ�ȻӰ���ת�������硰�š����ڶ����������϶������������е������֣���ʽ������ȡ���ˡ��š�������ʽ�����б������������Ծ�������ת���IJ��㡣
��֮�����������֣��������ȡ�ᷨ���ͽ�����������֣�������÷ֻ�������һ�㲻�ṹ�ɶ�Ӧת���Ĺ�ϵ����Ҫ�ص��ע����Ҫ�ǣ�
��ֻ��һ����ȡ�˷ֻ��������Ľ�����������֣�
�Ƹ����ֱ�ѡȡ�˲�ͬ���������εİ��������֡�
������������������Ӧ�ڸ������Э�̵Ļ������������������ǣ�������ֵ�����
Ϊ���о������������ֵķ��㣬�����ԡ�����ͨ���ֱ�����GBK�ַ�����Ϊ�������ݣ������ˡ�Ӱ��ת���ķǶԳ������ֵ�����������հ���������300���飬���а����˱���һ��������գ�����û�еõ�����ͨ�����Ⱦ�����ijЩ�������֡��������ԣ�
5�¾��������Ӧת��
�������۵ķ��塢���塢���塢����ȣ�ʵ���϶����ں��ֵ����η��룬��ͨ����ν�¾����Σ��������ں��ֵ����巶�롣
���¾���������������巶�룬��������������������
�κ�������ϵ�ж�������ͬһ���ֵIJ�ͬ�������⣬�����ֽ�Ϊ���⡣������������壺��������壬���桢�ݡ���������д����ӡˢ��ȣ������������������ϵҲ�У����ǵĴ��ڶ�����������ϵ�����������ϵı仯���ÿ�����ǿ�ı����Ӿ���Ч���������α��壬��һ�����������з��塢���壬���塢���������ȶ��ֱ���д�����������ʵΪ����������������������ϵ�к����棬�����ǹ淶������Ҫ����
�������Ͽ�������ͬ�����壨��ͬ�������壩�ĸ��庺��֮�䣬�������бʻ�����Ĺ���������һ�����ֵIJ�ͬ�������֮�䣬�������бʻ��������ϵ�Բ��죬��һ�㲻������Ϸ�ʽ������ԭ������IJ�ͬ��������ͬ�����Σ���ͬ���������Σ��ĸ����庺��֮�䣬����û��ʲô�����������ԣ�һ�����ֵIJ�ͬ����֮�䣬Ҳ����������Ϸ�ʽ������ԭ������ľ���졣
��Ϊһ�����ֵ�����д���������κ;����Σ����IJ�����Ҫ�漰�ʻ��ı��κͱ������漰��������Ϸ�ʽ������ԭ��������˹�����һ�ֶ��塱�ķ��룬�硰�塪�������𡪡����������������������ա��桪���w��ֵ�����������������εĵ��������䴴����ּ����Ҫ������ӡˢ�壨���壩����ø��������д�����һ�£�������˵���������εı�����������壬�������α��塣
�����֡������ֵ���������෴������������˵��һ���ֵ�����������д��֮�䣬����������Ϸ�ʽ������ԭ������IJ�ͬ�������ǡ�һ�ֶ��Ρ��ķ�ӳ���硰�塪���o�����������������o���롪���Y�����ͷ�������˵��һ���ֵķ���������д�����е�ͬ����������Ĺ�ϵһ�����硰�š����u���ˡ��������桪�������䡪��菡�����^���ᡪ���I���ȣ��е�����ƫ���ѱ�ɲ�������ʾ�������ļǺţ�������ԭ��Ҳ����Ŀȫ�ǣ��硰�������l�ơ���ؔ���������B��˵�����f���������y���������o���ȣ�������Ҳ�����ڡ�һ�ֶ��Ρ��ķ��롣
���˿���Ҫ˵�����������������俬�Ĺ����У��в����ָı�������ԭ����Ӧ��ν����أ��Dz�������֮��Ҳ��������Ϸ�ʽ������ԭ������IJ����أ�������Ϊ������ʵ�����α���������仯ͬ���غϵ�һ������������ֻ��ӳ�˺������ζ��ѡ����磬���ҡ�������������������ֱ�������֣�������������������ɻ����ֱ�������֣���Ϊƫ�Եġ��¡��⡢�ۡ������������ͬ��Ϊ���¡�����ͬ��ͷ�ġ�������ء��ࡢ̩��ͬ��Ϊ��ͬ����ͷ�ȣ���Щ�������嶼ֻ������������ε�����ԭ����һ�¡��������Ҳ��������ʽ�����У����硰����ũ���顢���������ȣ������ɲ��飨�����飩�������ɵ���ʽ�֣����ֻ��������д������û�о�����д����
��֮���¾������������֡��������б��ʲ�ͬ������������塣ͬһ�����ֵIJ�ͬ����֮�䣬ͨ����Ҫ��һ������ת������һ�����壬������������ϵĶ�Ӧת�������ͬһ�����ֵ�ͬһ����������������ϵ�д�������Σ�����Ȼ��Ӱ�������Ķ�Ӧת���������Ķ�Ӧת��Ҫ����һ�����巶���ڣ�һ���������ֻ��һ�����Σ��������������Ķ�Ӧת����������ת����˵�����һ��������һ������ֻ��һ�����εĻ���Ҳ�Ͳ�������ν���μ�Ķ�Ӧת���ˣ�������ʵ�����кܶ����Ǵ��ڶ������εģ��緱�塢���塢���塢����ȣ����������ֺ�����ϵ�������������в�ͬ���϶���������μ�Ķ�Ӧת������Ҳ�Ͳ��ɱ����ˡ��ɴ˿ɼ�������ת��������ת�������ڲ�ͬ���棬����������ء�ֻ�а�����ת�������������ˣ����ܽ��������ת�������⡣
�ƽ������ι᳹����ʽ�����У�ֵ����ȶ
�������Ǹ���д��һ�µ�ӡˢ�壬ԭֻ������ʽ���֣�����������ʽ���֡���GBK�淶�涨���� CJK ������ͬ������ܿ���ڣ������е� GBK ���뺺��ʵʩ�����������Ρ������ڲ���������ǰ���£��������������Σ���GB�����������ڳ��� CJK ������ͬ����ġ�����ͬ������δ��ȷ�涨�ĺ��֣��� GBK ��λ���ݰ��ž����Ρ���������ԭ��GBK��������ֶ�ͬʱ�������¾��������Ρ����硰�����ķ��壬��ͬʱ�����������Ρ��b���;����Ρ��a����������Щ��������ֻ������������Σ��硰Ϊ��α���ķ��壬ֻ�����˾����Ρ������^������δ���������Ρ��顢�Ρ��������������ξͲ�����ʽ���ֵ�ר���ˡ�ijЩרΪ�Ķ����������ֵ䡢�ʵ䣬����Dz�����װ��GBK�������Ű�ģ�Ҳ�ѷ�����ͷ�ij���������д�����������ǣ��������������ޱ�Ҫ�أ���ʽ����ֻ�����Ķ���������ʹ�����ǵ����Ǵ�ʱ�ű�ʹ�õĺ��֣��������ϵĺ���Щ�����۰�̨�ȵ�ʹ�õ���ʽ�������壬������ֻ�о�����һ�����壬�����Ѿ�ϰ���ˣ������ֶ��һ�����������壬�Ƿ�����������ѧϰ��ʹ����ʽ�����أ���ȷ��ֵ�������о��ġ��������ij��ԣ�Ҳ����Ϊ�����������ε�Ӱ��Ƿ�Χ������û�з����Ӧ��ϵ�ĺ�����˵��ͳͳ��GB����������ʽ���ֽ������Ҫ������ȫӦ�õģ����������ų�����ʽ����֮��ķ�������˵��Ҳͨͨ��һ����GB�������ƺ������ڽ�����ʽ���ֵ��������ˡ����ǣ���ʽ���ֵ����廹���������������Dz����е㻭�������ζ���أ�
������Ϊ����Ϊ���İ취�ǣ���ʽ���ֵ�����Ӧ�����λ���GB��������ʽ���ֵ�����Ӧ�����λ��������ǵ�������Ҫ��ͬһ�����桱Ӧʹ��ͬһ�����塣����ʽ�����в��ӽ��������壬����ʽ�����в��ӽ��������壬����Υ����ͳһ��ԭ����ijЩ�ִ��������ϣ���ʱ����ӡ���¾����������Ĵ���硰�D�����Y������ӡ��ȣ�ʵ�����˿�Ц���á�
��һƪ�������ı��ͷ���
��һƪ��̸�Ž���ƫ�帴�ʵIJ�ͬ�ص�