SPSS在铁路春运客流调查中的应用
关键词:铁路,春运,客流,SPSS,分析
每年春运客流的构成和流向等信息对铁路部门的运输组织具有重要意义。南昌站作为京九线上重要的客运站,每年春运都承担着较大的旅客发送任务,对车站的春运客流状况进行调查,有助于更好地进行春运组织。为了尽量客观真实地了解南昌站的春运客流状况,分析各相关因素的关系,在对南昌站2005年春运客流状况的问卷抽样调查的基础上,利用SPSS (Statistical Product and Service Solutions)软件提供的统计功能(主要是交叉列联、多选项、对应分析)对问卷数据进行了较深入的分析,希望能为改善铁路运输组织和提高服务质量提供依据。
1 抽样调查基本情况
1.1 调查时间和对象
抽样调查从2005年2月17日—3月5日,每天进行一次。每天上午、下午和晚上在每个候车室各发放10份问卷,即每天每个候车室30份问卷。调查对象为由南昌站乘火车前往其他地区的旅客。
1.2 抽样方法
本次抽样调查采用分层、等距抽样设计,即首先依照候车室分层,在候车室内按照候车区域再分层。分层完毕后,在调查期间每天某时由调查员进入候车室进行随机抽样。在每个候车区域随机选定一组候车旅客,每隔一固定数目等距抽取一名旅客,直到满足样本量为止。
1.3 调查项目
考虑到南昌站春运客流较为集中,旅客密集且流动性大,在问卷中采用封闭性答题形式,以方便被调查人快速、准确地完成调查。
(1)您乘车的目的:包括外出工作,探亲,,学生返校。
(2)您的出行方向:包括北京方向(内蒙/北京/东北/合肥等);上海方向(杭州/宁波/南京/温州/苏州等);福建方向(福州/厦门等);成都方向(重庆/成都/柳州/贵州/昆明等);广东方向(东莞/广州/深圳等):武汉方向(武汉/长沙/郑州等);其他方向。
(3)您春节出行优先考虑的因素:包括安全;票价;舒适;快捷;能走就行。
(4)您对列车席位种类的选择:包括普通硬座;普通硬卧;空调硬座;空调硬卧;软座;软卧;其他。
(5)选择临时加开列车时,您考虑的因素(可多选):包括有空调,票价便宜,到达或开车时间;乘车时间:有卧铺:乘车环境及服务。
(6)您更愿意接受以下哪种购票途径:包括直接到车站窗口购买,直接到铁路客票代售处购买:打电话提前预订:上互联网提前预订。
(7)您的年龄阶段为:12~17岁,18~23岁,24~30岁,31~40岁:41~50岁:51~60岁;60岁以上。
(8)您的平均月收入:包括1000元以下,1001—2000元,2001—4000元,4001—6000元,6000元以上。
(9)您认为南昌站在接待旅客方面的服务:包括很好,较好,一般,较差,极差。
1.4 问卷发放回收情况
本次调查共发放问卷2100份,收回有效问卷2039份,有效问卷率达97.10%。
2 SPSS中的统计分析
SPSS作为统计分析工具,理论严谨、内容丰富,具有数据管理、统计分析、趋势研究、制表绘图、文字处理等功能。其中的统计分析功能包括从基本描述统计、推断统计到聚类分析、因子分析等多元统计分析方法。本文主要利用其中的交叉列联分析、多选项分析、对应分析等功能对客流的相关信息进行统计分析,而基本描述统计功能就不再做介绍。
2.1 交叉列联分析
(1)独立性与一致性检验。一般独立性与一致性检验的检验统计量为Q,当然也可用其他的统计量检验,如似然比统计量(Likeli— hoodRatio)、样本数小于20时四格表的Fisher.s检验等。
(2)相关系数及相关分析。经过一致性或独立性的卡方检验后,在得到差异是否显著或是否独立的同时,已经分析出两个特征(变量)是否相关了。如差异显著或不独立,则说明两变量相关显著,反之则相关不显著。但为了量化其相关程度,还应给出相关系数根据两个特征(变量)的数据类型,相关系数有以下种类。
①Pearson积矩相关系数:适用于分区间的连续数据或计数数据之间,且总体呈正态或近似正态,样本数≥30。
②Spearman秩相关系数:适用于等级或有序数据之间,应用范围较广,样本数<30,总体不呈正态均可。
③列联相关系数:适用于名义数据之间,其定义基于卡方检验统计量Q。
(3)不同数据类型的有关统计量。根据两个特征(变量)的数据类型的不同,列联表分析还可给出某些关联系数及一些特别的统计量。
①名义数据之间:lambda系数、不确定系数。
②次序数据之间:Gamma水平、Somers’d水平、Kendalls系数。
③名义数据与区间数据之间:Eta系数。
SPSS对这些列联分析都有充分的支持。
2.2 多选项分析
在实际问卷调查中,某些问题允许选择的答案是多个,也即有两个或两个以上的答案会被同时选中。针对这种多选项问题,利用普通的频数分析或交叉列联分析会比较烦琐,需要手工进行一些额外。为此,SPSS专门设计了一个子菜单Multiple Response方便这种变量的统计分析。
2.3 对应分析
对应分析(Correspondence Analysis)是由法国人Jean Paul- Benzerci于20世纪60年代创立,直到20世纪80年代才在国家兴起的一种多元相依(Interdependence)变量统计分析技术。它主要对名义变量或顺序变量多维频度表进行分析,探索同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。对应分析的4个优点是:名义变量划分的类别越多,这种分析的优势越明显;可以将名义变量或顺序变量转变为间距变量,揭示行变量类别间与列变量类别间的联系:将变量类别间的联系直观地表现在图形中。
对应分析的使用条件包括:变量是名义变量或顺序变量;行变量类别与列变量相互独立;行变量和列变量构成的交叉列表中不能有零值或负数。
3 SPSS在春运客流调查中的应用
3.1 春运客流调查的列联分析
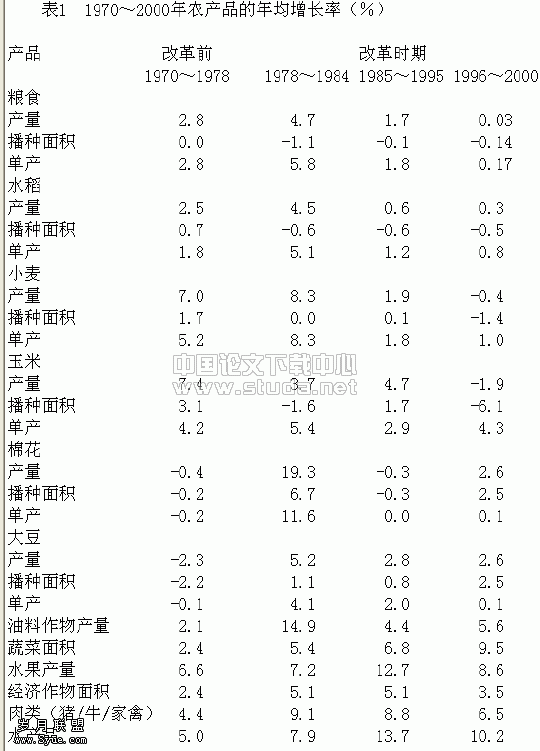
以购票途径倾向与乘车目的进行列联分析,利用SPSS的 Analyze->Descriptive Statistics—> Crosstab得出卡方检验结果如表1所示。

进行/检验,得到Q=61.501,双尾P值=0.000,因此拒绝原假设,认为乘车目的与购票途径具有显著相关性,即不同购票途径在不同客流上有显著差别,相关强度值的选择名义变量的相关系数。
3.2 春运客流调查的多选项分析
问卷中的出行考虑因素属于多选项问题,对它的分析采用多选项分析的二分法。即对安全、票价、舒适、快捷、能走就行等因素分别设置一个变量,然后把5个变量合为一个多选项变量集,再进行频数分析和交叉列联分析。调查中频数分析的结果如表2所示。
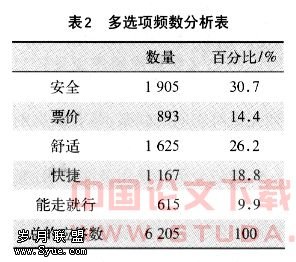
由输出结果可以看出,在对出行考虑的因素中有6 205个答案。其中安全是考虑最多的因素,达到30.7%,其次分别为舒适和快捷,而票价只以14.4%排在第四位,不加选择的有车就走排在在第五位。这反映了旅客对春运期间铁路服务质量的要求在提高,相当多旅客在春运期间乘坐火车不只是因为铁路票价便宜。
3.3 春运客流调查的对应分析
以乘车目的与旅客出行方向为例,由于乘车目的有4个选项,旅客出行方向有7个选项,较适合于对应分析的条件和优势。
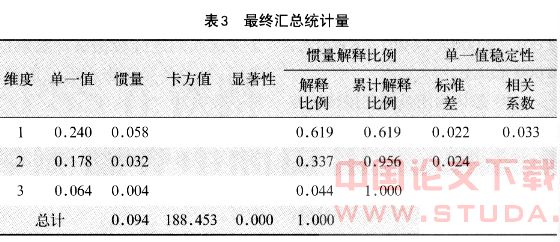
(1)最终汇总统计量。表3显示对应分析最终汇总统计量,包括维度、单一值、惯量、卡方值、户值、惯量解释比例,以及单一值稳定性等数据。卡方值188.453,户小于0.01,表明乘车目的与出行方向之间有显著的依赖关系。第一项是维度,其值是3。单一值是各维度对变量各个类别之间差异的解释量,代表每一维度。的行分值与列分值的相关系数。数据0.240就是第一维度的行分值与列分值的相关系数。惯量即相应维度单一值的平方,它表示每个维度对各个变量类别之间差异的解释量。解释比例即每一维度惯量在总特征值中的比例。在表3中,第一维度的解释比例为61.9%,说明第一维度能够解释所有变量类别差异的61.9%;第二维度的解释比例为33.7%,能够解释所有变量类别差异的33.7%;而第三维度的解释比例仅为4.4%。
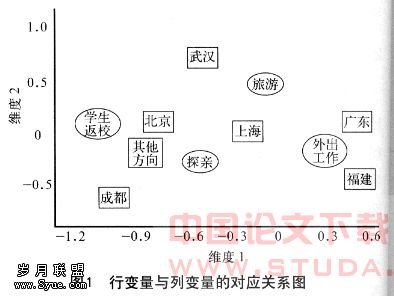
(2)行变量与列变量的对应关系图。对应分析还能用图型直观地反映行变量与列变量之间的关系,特别是当变量的类别较多时,图型既直观又具解释力,优势更加突出。本次分析的图型结果如图1所示。
从图1可看出,出行方向为北京、其他方向与学生返校;出行方向为广东、福建与外出工作联系紧密。而出行方向为成都与乘车目的的4个方面距离很远,说明联系不大。出行方向为上海与外出工作、探亲、等有一定距离,说明有一定联系。造成这个现象的原因主要是江西作为一个劳动力输出大省,每年外出务工人员较多,而且主要是以广东、福建等地区为主,学生流则反映出学生读书主要是以北京方向和其他方向(如西安方向)、上海方向为主,武汉离南昌较近,在短距离的旅游上表现出一定的优势。