多重共线性的程序选优法
[摘 要] 文章介绍了多重共线性及其影响,使用逐步回归法解决多重共线性的缺点以及程序选优法的设计思想。通过使用举例说明程序选优法在解决多重共线性时具有快速、最优和准确的优点。
[关键词] 多重共线 逐步回归 Eviews 程序选优
一、多重共线性及其影响
1.什么是多重共线性
对于多元线性回归模型
Yi=β0+β1X1i+β2X2i+…+βkXki+ui ,i=1,2,…,n
其古典假设之一就是解释变量X1,X2,…,Xk是相互独立的。如果某两个或多个解释变量之间出现了相关性,则称存在多重共线性。
如果存在
c1X1i+c2X2i+…+ckXki=0, i=1,2,…,n
其中ci不全为0,既某一个解释变量可以用其他解释变量的线性组合表示,则称解释变量间存在完全共线性。
如果存在
c1X1i+c2X2i+…+ckXki+vi=0 , i=1,2,…,n
其中ci不全为0,vi为随机干扰项,则称解释变量间存在近似共线性。
2.完全多重共线性下参数估计量不存在
完全多重共线性时,在Eviews软件下用普通最小二乘法估计,屏幕出现提示“Near singular matrix”。此时参数无法确定,参数的方差无穷大。
在近似多重共线性下会有如下影响。
3.普通最小二乘法参数估计量的方差变大,容易删掉重要的解释变量
在多重共线性下,参数估计量的方差随着多重共线性的“严重程度”,呈“膨胀性”增大。进行统计检验时,由于方差的变大,可能使t统计量小于临界值,误导作出参数为零的推断,这样容易删掉重要的解释变量,造成模型设定误差。
4.参数估计量的含义不合理
如果模型中两个解释变量具有线性相关性,如X1和X2,那么它们中的一个变量可以由另一个变量表征。这时,X1和X2前的参数并不反映各自与被解释变量之间的结构关系,而是反映它们对被解释变量的共同影响,所以各自的参数已经失去了应有的经济含义,于是经常表现出似乎反常的现象,例如估计结果本来应该是正的,而结果是负的。
二、逐步回归法的缺点
克服近似多重共线性的常用方法有排除引起共线性的变量、差分法、减小参数估计量的方差等三类方法。其中排除引起共线性的变量是最为有效的克服多重共线性的方法,而逐步回归法就是这种方法,因此逐步回归法得到了最为广泛的应用。
逐步回归法的基本步骤是首先把被解释变量对每一个解释变量分别进行回归,从而得到所有的基本回归方程式,并对每一个基本回归方程进行统计检验,分析其估计结果,从中选择最合适的基本回归方程,然后再逐一增加其它的解释变量,重新再作回归,根据可决系数、修正的可决系数、回归系数的t值逐步把显著性的解释变量选人回归方程中,同时把非显著性的解释变量从回归方程中剔除,最终建立一个满意的回归方程。但逐步回归法的使用也有一些不足。
1.步骤烦琐,容易出错
虽然Eviews软件在计量经济学上的广泛应用,使参数的估计变的十分方便,但通过反复的比较,逐步回归的方法,步骤还是比较烦琐,人工操作也容易出错。如对一个五元回归方程,第一大步,建立五元回归模型,进行检验多重共线性;第二大步,要进行五个一元回归方程的建立和比较;第三大步,在第二大步的基础上,要进行四个二元回归方程的建立和比较;第四大步,在第三大步的基础上,要进行三个三元回归方程的建立和比较;第五大步,在第四大步的基础上,要进行二个四元回归方程的建立和比较。通过以上十四次的建立和比较才能确定一个满意的回归方程。如果解释变量增加,则步骤更多。
2.结果有可能是局部最优
逐步回归法的应用可能遗漏最优方程,选出的回归方程有可能只是某一个较优的回归方程。如在上述第三大步中,进行四个二元回归方程的比较时,可能四个二元回归方程的t统计量都小于临界值,而在三元方程则会通过t检验,因此我们在二元回归方程的选择可能存在随意性,这样的选择最终可能遗漏最优方程。
三、程序选优法的设计思想
1.程序选优法符合“从一般到简单”的建模思想
逐步回归法是以“由简单到复杂”的建模思想为指导的,而程序选优法是以“从一般到简单”的思想为指导,即开始时建立一个一般的模型,将对被解释变量有影响的所有变量都作为解释变量,然后在建模的估计和检验中选择,最后得到一个比较简单的模型。这种建模方法在很大程度上消除了建模过程中的主观性。如开始时建立一个五元模型,程序选优法通过运行事先编好的程序,会自动建立一个五元回归方程,五个四元回归方程,十个三元回归方程,十个二元回归方程,共二十六个可能的方程,同时程序会自动选择出最优的方程。这种方法简单快速,保证了所选方程的最优。
2.完全多重共线性的处理
正如前面所说,出现完全多重共线性时,在Eviews软件下用普通最小二乘法估计,屏幕出现 “Near singular matrix”的提示。出现这种情况,如对一个六元模型,此时可以在命令窗口输入:
COR y x1 x2 x3 x4 x5 x6
屏幕出现相关系数矩阵,见表1
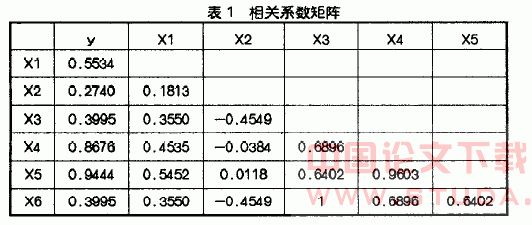
从上表可以看出x3和x6的相关系数是1,产生了完全多重共线性,此时在x3和x6之间必须选择去掉一个,使完全共线性变为近似共线性。事实上完全共线性并不多见,因此在一般情况下也不需要作上述处理。
3.选优标准及过程
Eviews软件是由美国Quantitative Micro Software公司提供的数据分析、回归及预测工具,是目前世界上最流行的计量经济学软件。另外,Eviews软件也提供了编程和运行程序的功能,这为程序选优法的实现提供了方便。
程序选优法的选优标准首先要求在所有可能的回归方程中被解释变量系数的p值都小于显著性水平0.05,即被解释变量在0.05的显著性水平下都通过t检验。其次,在满足上述条件下,比较回归方程的修正的可决系数,选出修正的可决系数最大的回归方程就是最优方程。
选优过程首先要在程序中输入被解释变量的总个数,如n=5,即共有五个被解释变量。运行程序后,程序会自动通过循环用equation 和ls命令建立回归方程,利用函数@RBAR2可自动获得回归方程的修正的可决系数,利用函数@NCOEF可自动获得被估参数的个数,利用函数@REGOBS可自动获得样本容量,利用函数@TSTATS可自动获得参数的t统计量,利用函数@TDIST可自动获得被解释变量系数的p值。这样程序运行后就可以建立所有可能的回归方程,并在满足t检验的方程中,通过比较回归方程的修正的可决系数,选出最优方程。
四、使用举例
根据理论和经验分析,影响粮食生产的主要因素有农业化肥施用量、粮食播种面积、成灾面积、农业机械总动力和农业劳动力,其中,成灾面积的符号为负,其余均应为正。表2列出了粮食生产的相关数据,试建立中国粮食生产函数。
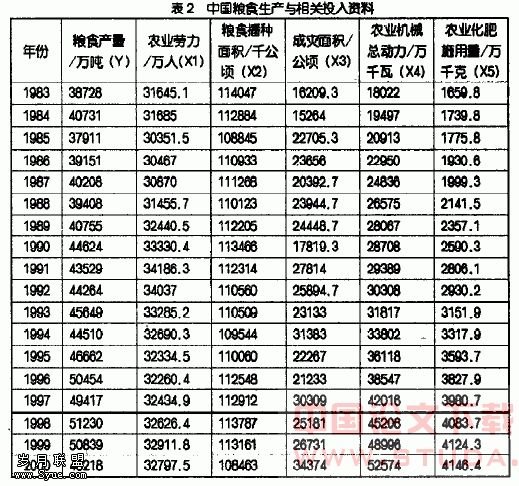
资料来源:《中国统计年鉴》(1995,2001)
使用时打开Eviews软件,创建新的工作文件,将表2中的数据输入序列对象。单击Eviews软件的“File”→“Open”→“Progrem...”,选择事先编好的程序文件,单击“打开”。在程序中将控制变量scalar n=设为scalar n=5,单击“Run”运行程序,在“Run program”对话框中,单击“OK”,1秒~2秒程序运行结束。此时在工作文件中自动产生了控制变量best,在best上右击选择“Open”,在状态栏显示scalar best=18,由于程序在工作文件中已自动建立了eq1、eq2、……、eq26共26个回归方程,此时best=18,即eq18是程序自动选择出的最优回归方程。当然,如果没有一个方程符合要求的情况下,此时best=0。双击eq18,可以看出中国粮食生产的回归分析表达式为:
Y=-11978.18 +0.41X2-0.19X3+5.26X5
SE: (0.1220) (0.0545)(0.2686)
t:(3.35)(-3.57) (19.57)
R2=0.9796F=224.01DW=1.53
由上面使用事例可以看出,程序选优法在使用排除引起共线性变量的方法克服多重共线性时具有快速、最优和准确的优点。事实上,根据“从一般到简单”的建模思想,不管是否有多重共线性,程序选优法都可以作为一种普遍的选优建模方法。
:
[1]李子奈 潘文卿:计量学[M].北京:高等出版社,2005
[2]王文博:计量经济学[M].西安:西安大学育出版社,2006
[3]高铁梅:计量经济分析方法与建模Eviews应用及实例[M].北京:清华大学育出版社,2006