基于数据分组方法的数据仓库并行预计算和查询(二)
MPI建立了一套有效的、可移植的、灵活的标准,并已经成为国际上应用最为广泛的并行程序设计平台。MPI可以使用于几乎所有的并行环境(共享存储和分布式存储、MPP、Cluster)和多个操作系统(UNIX、WindowsNT、Linux)。
3.2 MPI的特点与实现
如上一小节所述,MPI是一个消息传递模式下并行程序设计的标准规范。在标准的程序设计语言的基础上,加入实现进程间通信的MPI消息传递函数以及其他并行计算环境设置函数,就构成了MPI并行程序设计所依赖的并行编程环境。对于MPI的定义,需要理解以下三个方面[Du01]:
(1) MPI是一个库而不是一门语言。MPI库可以被FORTRAN77/C/Fortran90/C++调用从语法上说它遵守所有对库函数/过程的调用规则和一般的函数/过程没有什么区别。
(2) MPI是一种标准或规范的代表,而不特指某一个对它的具体实现。迄今为止所有的并行计算机制造商都提供对MPI的支持,一个正确的MPI程序,可以不加修改地在所有并行机上运行。
(3) MPI是一种消息传递编程模式并成为这种编程模式的代表和事实上的标准。MPI虽然很庞大,但是它的最终目的是服务于进程间通信这一目标的。
由此可见,MPI是一个标准。就如同世界上其他标准一样,都会出现很多基于同一标准的不同产品,MPI也不例外。很多研究机构或者公司根据MPI的标准和自己的实际情况,编写出了不同的支持MPI程序的编程环境,而这些编程环境在MPI的世界里就被称为MPI实现。目前比较重要的MPI实现有以下两种:
● MPICH[MPI07]。MPICH是一种最重要的MPI实现,是目前使用最广泛的免费MPI系统,大部分集群系统上的并行环境是MPICH。它由美国Argonne国家实验室和MSU共同进行维护。支持几乎所有Linux/UNIX以及Windows9x,NT,2000和XP系统。而且每当MPI推出新的版本时,就会有相应的MPICH实现版本。
● LAM[LAM07]。由美国Ohio State University开发,主要用于异构的计算机计算系统。
3.3 MPI编程的基本概念
一个MPI并行程序由一组进程或线程所组成。这些进程或线程可以运行在相同的机器上,也可以运行在不同的机器上。在MPI中,一个独立参与通信的个体被定义为一个进程。每个进程所运行的代码并不需要是同样的,进程间的通信是通过调用MPI通信原语来完成。在典型情况下,每个进程都是在自己特有的地址空间中运行,尽管有时在SMP上的MPI程序并不如此。MPI程序中的每个进程都有一个序号,用于在进程组(由MPI程序中部分或全部进程所构成的一个集合)中标识该进程,这个序号被称为进程号,取值范围由0开始。
MPI程序中进程间通信是通过通信器(communicator)进行的,通信器提供了进程间通信的基本环境。MPI程序在启动时会自动创建两个通信器:MPI_COMM_WORLD和MPI_COMM_SELF。前者包含程序运行时的所有进程,后者则是由每个进程独自构成、仅包含自己的通信器。在MPI程序中,一个MPI进程由通信器和进程在该通信器中的进程号唯一标识,同一进程可以在不同通信器中有不同的进程号。进程可以通过调用MPI_Comm_rank函数来获得本进程在某指定通信器中的进程号。
3.3.1 MPI的点对点通信
通信器使得进程间可以通过消息或同步操作来完成通信。消息指在进程间进行的一次数据交换,在MPI中,消息一般包含以下一些内容:通信器、源进程、目的进程、消息标签和数据。MPI进程中使用得最频繁,最基本的一种通信模式就是一对进程相互之间进行通信,也就是一个进程发送消息,另一个进程接收消息,这种通信方式在MPI中被称作点对点通信(point to point communication)。MPI有两大类型的点对点通信函数,一种称为阻塞式(blocking),另一种则是非阻塞式(unblocking)。
● 阻塞式通信:阻塞式函数会等到通信操作实际完成,或者至少通信所涉及的数据已经被MPI环境处理好之后才会返回。如MPI_Send和MPI_Recv,分别是阻塞式的发送和接收函数。MPI_Send函数返回之后,表明消息已经发送完毕或者已经被MPI环境处理完毕,随后对于发送缓冲区的修改不会对已经发出的消息有所影响。而MPI_Recv函数返回后,表明消息已经接收完毕并且可以立即使用。
● 非阻塞式通信:非阻塞式函数在调用后会立即返回,而实际的消息传递工作由MPI环境在后台执行。非阻塞式函数的命名是在阻塞式函数名的MPI_前缀之后加上一个“I”,如MPI_Isend和MPI_Irecv则是MPI_Send和MPI_Recv的对应非阻塞式通信版本。在调用非阻塞式函数之后,进程可以调用MPI_Wait函数来等待通信操作的完成,或者可以进行其他的计算工作,而不必将CPU时间浪费在通信上,但这时不能对相关的数据缓冲区进行操作。因为当前操作可能会与正在后台进行的通信发生冲突,产生错误使得程序出问题。要检测通信操作是否实际完成,应该调用MPI_Test函数来查询通信操作的完成情况。
在MPI中,对于点对点通信,也存在着4种发送模式。这4种模式的对应函数名称不同,但参数表是一样的,它们之间的差异,存在于它们发送消息的方式和对接收方的状态要求的不同。这4种模式分别是:标准模式、缓冲模式、同步模式和就绪模式。
● 标准模式:当消息长度小于或等于MPI环境预留的数据缓冲区大小时,MPI环境会将消息复制到缓冲区,然后立即返回。否则会当部分或全部消息发送完成后才返回。标准模式下,发送操作的完成需要与接收方联络。
● 缓冲模式:MPI环境将消息复制到一个用户提供的缓冲区中,然后就立即返回,消息由MPI环境在后台执行。用户必须确保所提供的缓冲区能够容下将要发送的消息。缓冲模式下的发送操作不需要与接收方联络便可立即完成。
● 同步模式:同步模式是基于标准模式上,增加了一个要求。它要求确认接收方已经开始接收数据后函数调用才返回。
● 就绪模式:调用就绪模式发送时必须确保接收方已经正在等待接收该消息,不然就会产生错误。
3.3.2 MPI程序结构
下面是C/C++语言MPI程序的典型结构:
#include "mpi.h" ........ int main(int argc, char *argv[]) { int myrank, numprocs; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &numprocs); MPI_Comm_rank(MPI_COMM_WORLD, &myrank); ...... MPI_Finalize(); ...... return 0; } |
表3.1 MPI程序基本结构
C/C++语言的MPI程序必须包含MPI的头文件mpi.h,以获得MPI函数的原型说明和MPI的预定义数据类型和常量。在使用C++作为MPI程序编程语言的时候,在编译程序时可能会遇到以下的出错信息:
“SEEK_SET is #defined but must not be for the C++ binding of MPI”
这个问题是由于stdio.h和MPI C++接口同时都使用了SEEK_SET,SEEK_CUR,SEEK_END这些全局变量,这是MPI-2标准中的一个bug。要解决这个问题,一般会在#include “mpi.h”这句代码前加上以下三句:
#undef SEEK_SET
#undef SEEK_END
#undef SEEK_CUR
MPI_Init函数用于初始化MPI系统环境。该函数应该在调用其他所有MPI函数之前(除了MPI_Initialized)调用,不然MPI环境还没建立,其他函数也无法运行。命令行参数argc和argv可以传递给MPI_Init,因为有时可以通过这些参数将运行进程的相关信息传递给MPI程序。一般来说,调用MPI_Init(0, 0)也是足够的了。
函数MPI_Comm_size和MPI_Comm_rank分别返回指定通信器中的进程数目和本进程的进程号。在这个例子中,使用的通信器是MPI_COMM_WORLD,它包含了所有进程。
MPI_Finalize函数是用来退出MPI系统环境的。调用它之后便不能再调用任何其他的MPI函数了。程序的主体运行部分一般是在MPI_Finalize之前。进程可以通过myrank变量判断自己是哪个进程来执行不同进程所应该做的工作。
3.3.3 MPI编程的主从模式
构成并行程序的进程中有一个主进程(通常是进程0)其余为从进程。主进程与从进程的分工是不同的。主进程的工作一般负责整个并行程序的控制,分配数据和任务给从进程,从进程负责数据的处理和计算工作,同时主进程也可以参与数据的处理和计算工作。
3.4 小结
MPI的一个最重要的特点就是免费和源代码开放,MPI可以被迅速接受和它为自己定下的高效率、方便移植和功能强大三个主要目标密不可分。它采用广为使用的语言FORTRAN和C/C++进行绑定也是它成功的一个重要因素,当然MPI的成功还因为它和吸收了前期大量消息传递系统的经验。一个成功的标准是需要大量的实践和艰苦的努力的,MPI就是这种实践和努力的结果。
第四章 商立方体
联机分析处理(OLAP)由于要计算复杂的聚集函数,有很多的查询要从磁盘读取大量的数据,而OLAP的交互特性要求系统能快速地响应查询。为了解决这对矛盾,Gray等人提出了数据立方体(Data Cube)[GCB+97]。数据立方体概括了可能提出的所有的查询类型,并且将查询结果预先计算出来保存到磁盘。在响应查询时,通过查询重写把用户的查询转换为对某一个实例化视图的查询,极大地提高了查询响应速度。
近年来,随着数据仓库应用的广泛,数据仓库的数据量也越来越大,使得数据立方体的数据量也相应地急剧增加。数据立方体存在一个明显的缺陷:由于需要计算多个聚集函数对于所有可聚合属性的集合,数据立方体需要大量的计算和巨大的磁盘存储空间,不能很好地适用于多维度的场合。因此,减少数据立方体所占用的空间成为了一个关键问题。对此,人们纷纷提出了多种数据立方体的数据压缩技术。其中一类是基于数据立方体单元间关系的压缩技术,它们利用这些关系,如上卷、下钻等,通过分析发现单元间能够去除掉的冗余信息。这样,在将这些冗余信息去除掉之后,数据立方体的存储空间得到压缩并且数据立方体元组之间的关系得以保留,这类技术是目前数据立方体压缩存储技术的主流,代表着未来数据立方体压缩存储技术的趋势。
Wang等人提出了精简立方体(Condensed Cube)的概念[WLFY02],它其中有一个关键概念叫“Base Single Tuple(BST)”。它将具有相同BST的数据立方体单元归为同一类,仅仅存储BST和对应的单元集,其他不符合这些条件的元组则按原来的方式存储。通过去除相同BST的数据立方体单元间的冗余信息,精简立方体能够有效地减少数据立方体的数据量。
Y. Sismanis等人提出了一种称为Dwarf的,基于语义压缩方法的立方体结构[SRD02]。它通过识别出立方体结构中具有相同前缀和后缀的语义信息,并去除这两种类型的冗余信息,可以十分显著地缩减数据立方体的存储空间。Dwarf在最好的情况下可以达到1/6000的压缩率。
商立方体(Quotient Cube)的概念由Laks Lakshmanan等提出[LPH02],主要是为了解决立方体压缩过程中立方体单元间上卷和下钻逻辑关系的丢失问题。在商立方体中,所有的单元被划分为若干类,在同一类中的单元具有相同的聚集值。类的划分不仅仅是满足聚集值相同这个条件,同时也满足一些额外的条件。这些条件的限制,使得商立方体可以保留下数据立方体的语义结构。因此,每个类只需保存下某些能够代表本类中所有单元属性的单元,即可实现数据量的压缩。
4.1 商立方体的分类
商立方体的主要思想是分类,它采用了一种单元分类方法,称为“覆盖”分类法[LPH02]。该方法与聚集函数类型无关,也就是说,数据立方体上的任一单元,无论它的度量值的聚集函数是哪种操作,这个单元都会被商立方体算法划分到同一类中。
假设基表中的一条元组t,在数据立方体网格中,t能够通过某一存在的路径,上卷到单元c,则称c覆盖(cover)t。c的覆盖集(cover set)定义为:c所覆盖的所有基表中的元组。例如,在图2.1中,单元(*, B, M1)的覆盖集是{(GZ, B, M1), (SZ, B, M1)}。
对于单元c和单元d,当c和d的覆盖集是相等的时候,它们被称为覆盖相等。例如,图2.1中的(*, B, M1)和(*, *, M1),它们的覆盖集都是{(GZ, B, M1), (SZ, B, M1)},因此这两个单元是覆盖相等的。
商立方体的分类方法就是将覆盖相等的单元分为同一类。在同一类单元中,有个上界(upper bound)的概念。上界就是在该类中最小的元素,也就是说,上界是无法下钻到同类单元中其他任何一个单元的。使用覆盖相等方法产生的商立方体分类,每个类有且只有一个上界,且同类的单元具有相同的聚集值[LPZ03]。
表4.1所示是对于图2.1中的数据立方体进行商立方体分类和各类的上界。类别 | 类中单元 | 上界 |
1 | (*,*,*):60 | (*,*,*):60 |
2 | (GZ,*,*):35 | (GZ,*,*):35 |
3 | (*,*,M1):45, (*,B,*):45, (*,B,M1):45 | (*,B,M1):45 |
4 | (*,F,*):15, (*,*,M2):15, (GZ,F,*):15 (GZ,*,M2):15, (*,F,M2):15, (GZ,F,M2):15 | (GZ,F,M2);15 |
5 | (GZ,B,*):20, (GZ,*,M1):20, (GZ,B,M1):20 | (GZ,B,M1):20 |
6 | (SZ,*,*):25, (SZ,*,M1):25, (SZ,B,*):25, (SZ,B,M1):25 | (SZ,B,M1):25 |
表4.1 商立方体分类和上界集
4.2 商立方体的预算法
商立方体的预计算算法的主要目的就是将单元分类和找出这些类的上界。为了加快预计算的速度,本文中的预计算程序使用到了映射处理。也就是将在原始数据某一维上不相等的数值,根据它们出现的顺序,映射成正整数。例如表2.1中的第2维{B, F, B},通过映射,B将映射成1,F将映射成2,第3个B因为之前已经出现,所以不必重新映射。映射后,对于数值为“*”的维度,则把它看作是0。
在将基表完成映射并完全载入内存的时候,便开始进入商立方体预计算算法的主体部分,一个深度优先算法(DFS)。在DFS中,完成了以下一些工作:找出覆盖相等的单元、找出类的上界并跳转到这些上界、根据基表分区来进行立方体计算。
对于某单元c,DFS是按照以下步骤来找出c所在类的上界ubc的:根据上界的定义,可以知道ubc与c比较的话,在c中不是“*”的维度的值与ubc相应维度的值是相同的。对于c在基表上的覆盖集Bc,任意一个维度i,且c在i维上的值为“*”,假设一个固定值xi出现在所有Bc中的所有元组的第i维中,则ubc的第i维元素就是xi。如果不存在这样xi,则第i维上的元素就是“*”。DFS的大体流程如下表所示:
DFS (cl, bPos, ePos, d) (1) 计算cl的上界集ucl; (2) 如果存在j<d使得cl[j]=*而ucl[j]!=*,返回(已经存在ucl,不用再次计算); (3) 否则,计算元组cl的聚合值,写进内存变量; (4) 用临时元组tmpucl存储上界集ucl; (5) 对所有d<j<n使得ucl[j]=*进行以下操作:对从bPos到ePos元组在维度j上排序,对j维度上的每一个值x,让ucl[j]=x;Posb为j维度值为x的第一个元组,Pose为j维度值为x的最后一个元组,递归调用DFS(ucl,Posb,Pose,j);每次j值改变之后,ulc=tmpucl; (6) 返回; |
表4.2 DFS算法
预计算算法最终的输出结果所有类的上界和类的度量值,它们存放在(维度数+1)×2个文件中。假设原始数据的维度是d,则会产生d+1个存放上界的文件,另外d+1个文件则存放相应的度量值。具有同样多个“*”的上界被归为同一层,它们都存放在同一个文件中,且该文件只存放同一层的上界,它们相应的度量值也存在相应层次的度量值文件中。例如:全部都是“*”的单元是第0层,没有“*”的单元则是第d层,依此类推。
4.3 商立方体的查询算法
商立方体的查询其实就是查找出与查询语句划分在同一类中的上界。本文中所使用的商立方体查询算法是最直观的顺序查询。对于某条查询q,顺序查询是按照以下步骤进行的:
(1) 根据预计算产生的映射文件,对q进行映射。
(2) 扫描映射后的q,确定q所在的层次。
(3) 打开q所在层次的对应上界文件。
(4) 从目前打开文件的第一条上界开始扫描,判断该上界是否被q所覆盖。如覆盖,则记下该上界的位置,在相应的度量值文件中找到该上界的度量值,返回度量值。如不覆盖,则继续扫描下一条上界,判断是否被q覆盖。
(5) 假如在当前打开的层次文件中扫描不到被q所覆盖的上界,且当前层次已经是第d层,则返回查询不命中。如果当前层次还不是第d层,则打开当前层次的下一层次文件。然后跳转到(4)。
[LW05]对于商立方体的查询性能进行了分析。对于查询算法的第(5)步,假如在q所在层次文件扫描不到上界,便需要扫描下一个层次,当每个层次的数据量都很大的时候,这种查询不命中就会产生额外的开销,使得查询程序性能下降得很厉害,而对于数据立方体类似的顺序查询则不会造这种额外层次扫描的开销。
4.4 小结
目前基于数据立方体元组间关系的压缩技术分成了两类,一类是以原有立方体存储结构为基础,如精简立方体;另一类则是通过分析立方体元组间的逻辑关系,构造出新的立方体存储结构,如Dwarf和商立方体。
商立方体的主要思想是把数据立方体中覆盖相等的单元全部分成一类,使得只需保存这个类的上界便可保留数据立方体的信息,这样便达到了压缩数据立方体的目的。
第五章 并行化算法的设计
本章将描述本文提出的基于数据分组方法的并行预计算,以及在该预计算方法产生的商立方体数据上,并行地进行查询的方法,并对这种做法的正确性进行初步的分析。
5.1 基于数据分组的预计算
基于数据分组的预计算方法的主要思想是数据的分布性。并行预计算程序使用主从模式进行编程。主要的处理步骤如下所示:
(1) 基表由主进程读入,主进程一边读入基表元组,一边完成对各维数据的映射处理,映射关系文件存储在主进程所运行的机器上。
(2) 当主进程载入内存的数据元组条数到达一定数量时(由用户决定),主进程将这部分数据发送给相应的从进程,从进程在接收数据完毕之后,立即开始对所接收到数据进行商立方体预计算。主进程在将分配给某个从进程的数据发送完毕后,继续将基表中的数据载入内存,直到所有元组都被载入和所有的从进程都接收好数据以后,主进程开始对留在本地内存中,没有分派给任何从进程的元组数据进行预计算。
(3) 每个进程都独立地进行预计算工作,它们预计算所产生的商立方体上界分层地存储在进程运行机器的本地磁盘中。
(4) 所有进程都完成预计算后,并行程序退出。
主进程数据分发示意图如图5.1所示。
SHAPE /* MERGEFORMAT
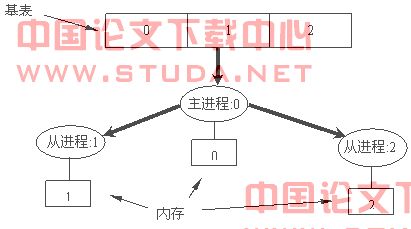
图5.1 数据分发示意图
5.2 在立方体分布式存储情况下的并行查询
上一小节所描述的预计算算法,在完成预计算之后,将会把商立方体数据分布式地存储在各台机器的本地磁盘中。对于这种情况,应该要并行地对各个独立存储的立方体进行查询,并且最终各个查询结果要经过汇总处理后才能得到与串行查询程序一样的查询结果。本文提出的在立方体分布式存储情况下的并行查询也是基于MPI,以主从模式为实现方式,基本步骤如下:
(1) 主进程读入多条查询语句,并根据主进程本地存储的映射关系文件对查询语句进行映射,映射后的查询语句都存放在主进程的内存中。
(2) 主进程将所有的查询语句广播给各个从进程后,主进程开始进行查询。从进程在接受完查询语句后,也开始对本地的立方体数据进行查询。
(3) 每条查询语句都会返回一个结果,各个进程将这些查询结果存放在一个大小为查询语句条数的数组中。在所有查询都完成查询后,主进程开始接收来自各从进程的查询结果,从进程则开始向主进程发回它们的查询结果。
(4) 主进程在接收完各从进程的查询结果后,将所有查询结果整合在一起,便得到最终的查询结果。
5.3 正确性分析
本节将用来说明在5.1和5.2节中所提出的基于数据分组的并行预计算和查询方法的正确性。主要说明在立方体数据分布式存储情况下,并行查询程序得到的结果,与在立方体数据集中式存储情况下的串行查询程序所得到的结果是相等价的。
对于查询语句q,它的查询结果R(q)是决定于q的覆盖集Cov(q)的。假设基表为B,有m条元组,q在B上的覆盖集为Cov(q)。
随机地将B中的元组分为2部分,分别为B′和B′′。由于是以元组为单位划分,同一条元组不可能同时出现在两部分中,q在B′、B′′上的覆盖集分别为Cov′(q)、Cov′′(q)。可知:
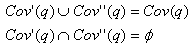
设a机的输入基表是B′,b机的输入是B′′。在预计算完成后,分别生成立方体QC(B′)和QC(B′′)。在并行查询中,分别使用q对QC(B′)和QC(B′′)进行查询。假设查询命中的上界分别是u′和u′′。根据本文4.3节中提到的查询算法的原理,可知:
在QC(B′)中,u′与q被划分到同一类中,且u′是该类的上界,则u′和q是覆盖相等的,有:
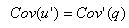
同理:在QC(B′′)中,
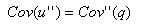
则有:
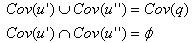
串行查询结果R(q)决定于Cov(q)所包含的元组信息。在并行查询中,程序可以分别得到Cov(u′)和Cov(u′′)的信息,而Cov(u′)与Cov(u′′)包含了Cov(q)中包含的所有的元组信息,因此,并行查询是可以得到与串行查询相等价的查询结果的。
5.4 小结
本章概括性地描述了基于数据分组的并行预计算和并行查询方法的实现过程,并对于这种方法的正确性进行了初步的分析。在接下来的章节中,将会详细地描述基于这种方法的并行程序的实现和使用实验数据来更进一步地表明该方法的正确性和有效性。