一种基于模糊相似粗糙集的WEB搜索优化方法
来源:岁月联盟
时间:2010-08-30
1 引言Web作为信息制造、发布、加工与处理的主要平台,正以令人难以置信的速度在飞速着。如何在Web所提供的海量信息中发现有用的信息并加以有效利用,一直是人们努力研究的方向。搜索引擎(Search engine)是目前Web信息检索的主要工具。传统的搜索引擎大多是基于关键字匹配、目录分类等技术,但在查询速度与查准率、查全率等方面还具有较大的局限性。近几年的研究发现,分析Web网页间的超链接结构并充分利用,可以提高检索的质量。基于这种超链分析的思想,在1998年,Serger Brin和Lawrence Page提出了PageRank[1]算法。同年,J.Kleinberg提出了HITS[2]算法,还有其他一些研究者相继提出了一些改进算法,如SALSA、PHITS等,在实际应用中取得了良好的效果。为了进一步提高Web搜索的效率,我们提出了一种根据特定的需求,利用粗糙比较对Web信息的搜索路径进行优化的方法。首先对用户提交的反映用户需求的网页或关键字进行模糊分类,得到对信息空间的相似分类,再对识别出来的网页集团的超链接结构进行分析,用网页间作用力与文本信息的混和相似度,得到网页集团在用户需求信息上的相似类划分。通过对各自所得到的基于相似关系的模糊粗糙集之间相似程度的度量,找到与用户需求最接近的网页集团的排序表,从而达到对Web信息搜索的优化。本文首先回顾一些研究者在这一领域所做的一些相关工作;然后在核心部分详细论述了基于相似关系模糊粗糙集的Web搜索优化策略;最后是我们的结论。2 相关工作J.kleinberg等在文[3]中提出Web结构所呈现出来的自组织性,从而反映出Web上的一些信息分布知识。他们认为,尽管Web是一个分散的信息,但从全局来看,互不关联的创建过程由于作者共同的偏好而使得信息源之间产生了愈来愈紧密的联系,即通过超链接内容相同或相关而地聚合在一起,形成一个个网页集团[4](Web community)。网页集团是指Web上一些网页所组成的集合,组成集合的成员网页指向集合内其他成员网页的超链接数,远比其指向集合外非成员网页的超链接数多得多。从形式上看,集团内部链接密集,而集团间链接稀疏,甚至根本不链接。集团内部的高密度链接通常表明构成集团的成员网页具有一定的信息相关性。这一发现对于我们进行Web信息搜索的优化具有很高的价值。PageRank算法和HITS算法是两种影响相当广泛的链接分析算法。其中,PageRank算法的基本出发点是试图为整个Web上的所有网页赋予一个量化的表征权威度的值,即通过迭代特征为每个网页分配PageRank值。由于所有处理过程是离线进行,因此不会为在线的查询过程付出额外的代价,但它最大的问题是没有对主题进行区分,因此,可能在返回结果中出现与主题无关的一些网页排在前面的情况。HITS算法模型中,提出了权威性网页(authority)和中心网页(hub)的概念。其中,权威性网页是被大量的超链接所指向的、包含高质量的主题内容的信息源。Hub网页是指向和主题相关的权威网页的一些不知名网页,提供对高质量主题内容存取的信息源。它们之间具有互相增强的关系(mutually reinforcing relationship):一个“好的”Hub网页应该指向很多“好的”权威性网页,一个“好的”权威性网页应该被很多“好的”Hub网页所指向,这样就需要通过一个迭代过程来计算每个网页的Authority值和Hub值。Kleinberg所提出的具体计算方法如下:用传统的基于关键字匹配的搜索引擎对用户提交的查询进行搜索,得到满足条件的前n个网页组成的基集S,再通过加入S引用的网页和引用S的网页得到一个更大的集合T。对于集合T中的任何网页,用a(u)表示网页u的Authority值,用h(v)表示网页v的Hub
 HITS算法是与特定查询主题相关的方式,因此在速度上有一定的优势,但也可能由于没有考虑链接的权重而造成主题漂移(topic drift)现象,但经过改进的加权(weighting)和修剪过滤(outlier filtering)等算法在一定程度上可以克服HITS算法的主题漂移问题。本文中所提出的Web搜索优化策略是在Web语义结构和网页集团的拓扑结构之间建立起一种映射,也就是在网页集团的拓扑结构中加入了用户的信息需求,从而提高搜索的速度和质量。在计算集团内网页间相似度与衡量网页重要性的工作中,我们引用了HITS算法中Authority和Hub的计算方法。另外,对于如何在Web中自动识别网页集团,已经有一些研究者提出了许多算法,如Gray和Steve[5]提出的基于Maximum Flow原理的识别网页集团的算法。因此我们的工作是假设在已经识别了一些网页集团结构的基础之上进行的。3 Web搜索优化策略3.1 Web信息空间划分对Web信息空间的划分,我们采用了模糊分类的方法。所谓分类就是采用某种方法把一些特征上类似的对象归并在一起,把一个对象的集合分为若干个子集,每个子集的元素具有类似的特征,而不同子集的元素尽量相异。在实际分类问题处理中,往往会发现精确地确定某个对象属于哪个分类是困难的,而只能近似给出它属于这个类的可能性有多大,在什么程度上相对地属于某一类,这就是我们所说的模糊分类的概念。这里采用文[6]中所提出的 “基于关键词的文本的模糊分类方法”。下面给出具体的实现。 3.1.1 通过文本模糊分类方法构建表征信息空间分类的模糊矩阵设D1,D2,…Dn是n个文本,每个文本Di由m个关键词d1,d2,…,dm来描述。这样文本Di可用一个m维向量表示:Di=(fi1,fi2,…,fim)其中
HITS算法是与特定查询主题相关的方式,因此在速度上有一定的优势,但也可能由于没有考虑链接的权重而造成主题漂移(topic drift)现象,但经过改进的加权(weighting)和修剪过滤(outlier filtering)等算法在一定程度上可以克服HITS算法的主题漂移问题。本文中所提出的Web搜索优化策略是在Web语义结构和网页集团的拓扑结构之间建立起一种映射,也就是在网页集团的拓扑结构中加入了用户的信息需求,从而提高搜索的速度和质量。在计算集团内网页间相似度与衡量网页重要性的工作中,我们引用了HITS算法中Authority和Hub的计算方法。另外,对于如何在Web中自动识别网页集团,已经有一些研究者提出了许多算法,如Gray和Steve[5]提出的基于Maximum Flow原理的识别网页集团的算法。因此我们的工作是假设在已经识别了一些网页集团结构的基础之上进行的。3 Web搜索优化策略3.1 Web信息空间划分对Web信息空间的划分,我们采用了模糊分类的方法。所谓分类就是采用某种方法把一些特征上类似的对象归并在一起,把一个对象的集合分为若干个子集,每个子集的元素具有类似的特征,而不同子集的元素尽量相异。在实际分类问题处理中,往往会发现精确地确定某个对象属于哪个分类是困难的,而只能近似给出它属于这个类的可能性有多大,在什么程度上相对地属于某一类,这就是我们所说的模糊分类的概念。这里采用文[6]中所提出的 “基于关键词的文本的模糊分类方法”。下面给出具体的实现。 3.1.1 通过文本模糊分类方法构建表征信息空间分类的模糊矩阵设D1,D2,…Dn是n个文本,每个文本Di由m个关键词d1,d2,…,dm来描述。这样文本Di可用一个m维向量表示:Di=(fi1,fi2,…,fim)其中
 通过以上的操作,我们得到了对论域D={D1,D2,…,Dn}的分类。应该注意到,在此得到的分类并不是严格的等价关系,因为某一文本往往并不属于一个类。 3.1.2 通过反映用户需求的网页来构建描述用户需求的模糊粗糙集为了解用户的需求,我们采用让用户提交一些反映他需求的网页的方式,再利用上面的文本模糊分类方法,得到反映其需求信息的模糊集,这个模糊集表示为:A=(μ1/C1, μ2/C2,…, μk/Ck)下面我们进一步考虑将所得到的反映需求信息的模糊集表示成模糊粗糙集的形式。粗糙集[7]理论是从一个新的角度把知识和划分联系在一起,为处理不完整和不确定的信息提供了一种新的数学工具。粗糙集理论以不可分辨关系(等价关系)为基础,把论域划分为等价类,生成粗糙集的上近似和下近似。在此,针对我们所研究问题的特殊性,考虑采用基于相似关系的模糊粗糙集。理由如下:⑴ 粗糙集是利用经典集合的等价关系给出的近似来考虑元素间的不可区分性,但是在实际应用中,往往把知识划分过细,造成问题处理的复杂化。模糊集是用来表示集合中子类边界的模糊性,是由隶属函数刻画的,与我们得到的信息空间的模糊表示相吻合。因此,将粗糙集和模糊集结合起来生成模糊粗糙集[8]不失为解决此类问题的一种好方法。⑵ 传统粗糙集的上下近似集依赖于不可分辨关系(等价关系)。在实际应用中,用对象之间的不可分辨关系描述数据间的关系往往过于精确,使得粗糙集的适用范围受到限制。而我们的文本模糊分类最终得到的分类结果应是一种相似关系(不满足传递特性)[9],而不是等价关系。因此我们考虑用一种相似类取代传统粗糙集中的等价类,其主要不同是不再形成对原有集合的划分,它们之间具有相互重叠的关系。
通过以上的操作,我们得到了对论域D={D1,D2,…,Dn}的分类。应该注意到,在此得到的分类并不是严格的等价关系,因为某一文本往往并不属于一个类。 3.1.2 通过反映用户需求的网页来构建描述用户需求的模糊粗糙集为了解用户的需求,我们采用让用户提交一些反映他需求的网页的方式,再利用上面的文本模糊分类方法,得到反映其需求信息的模糊集,这个模糊集表示为:A=(μ1/C1, μ2/C2,…, μk/Ck)下面我们进一步考虑将所得到的反映需求信息的模糊集表示成模糊粗糙集的形式。粗糙集[7]理论是从一个新的角度把知识和划分联系在一起,为处理不完整和不确定的信息提供了一种新的数学工具。粗糙集理论以不可分辨关系(等价关系)为基础,把论域划分为等价类,生成粗糙集的上近似和下近似。在此,针对我们所研究问题的特殊性,考虑采用基于相似关系的模糊粗糙集。理由如下:⑴ 粗糙集是利用经典集合的等价关系给出的近似来考虑元素间的不可区分性,但是在实际应用中,往往把知识划分过细,造成问题处理的复杂化。模糊集是用来表示集合中子类边界的模糊性,是由隶属函数刻画的,与我们得到的信息空间的模糊表示相吻合。因此,将粗糙集和模糊集结合起来生成模糊粗糙集[8]不失为解决此类问题的一种好方法。⑵ 传统粗糙集的上下近似集依赖于不可分辨关系(等价关系)。在实际应用中,用对象之间的不可分辨关系描述数据间的关系往往过于精确,使得粗糙集的适用范围受到限制。而我们的文本模糊分类最终得到的分类结果应是一种相似关系(不满足传递特性)[9],而不是等价关系。因此我们考虑用一种相似类取代传统粗糙集中的等价类,其主要不同是不再形成对原有集合的划分,它们之间具有相互重叠的关系。 根据以上定义,求得信息需求模糊集A所对应的模糊粗糙集,也用A来表示。3.2 网页集团拓扑结构前面我们已经对基于超链接结构分析的算法进行了回顾,下面将应用这些知识对网页集团拓扑结构进行分析,得到网页集团内成员网页间的相似性度量,从而得到相似类划分,为构建模糊粗糙集和语义分类间的映射做好准备。 3. 2 . 1 引入模糊熵过滤掉部分网页集团
根据以上定义,求得信息需求模糊集A所对应的模糊粗糙集,也用A来表示。3.2 网页集团拓扑结构前面我们已经对基于超链接结构分析的算法进行了回顾,下面将应用这些知识对网页集团拓扑结构进行分析,得到网页集团内成员网页间的相似性度量,从而得到相似类划分,为构建模糊粗糙集和语义分类间的映射做好准备。 3. 2 . 1 引入模糊熵过滤掉部分网页集团 根据求得的结果,模糊熵越高的网页集团紧密度越低,其成员网页的信息关联性越低,因此可将部分不满足要求的网页集团删掉。3.2.2 建立模糊相似矩阵S由于进行模糊聚类需考虑任两个样本间的接近度,因此,需对集团内部任两个网页间的相似度进行定义。在这里,应用HITS算法及相应改进算法,任两个网页间的作用力,进而求得受作用力的相似性,再与网页内文本相似度一起,表示成两个网页间的混合相似度的形式。
根据求得的结果,模糊熵越高的网页集团紧密度越低,其成员网页的信息关联性越低,因此可将部分不满足要求的网页集团删掉。3.2.2 建立模糊相似矩阵S由于进行模糊聚类需考虑任两个样本间的接近度,因此,需对集团内部任两个网页间的相似度进行定义。在这里,应用HITS算法及相应改进算法,任两个网页间的作用力,进而求得受作用力的相似性,再与网页内文本相似度一起,表示成两个网页间的混合相似度的形式。
 根据以上定义,求得网页集团内任两个成员网页的混合相似度,就可以得到整个网页集团的模糊相似矩阵。然后,通过λ_截集,对该模糊矩阵进行基于相似关系的相似类划分。再在每个相似类中,选取几个代表性网页,选取标准可以考虑隶属函数及其权重的乘积。3.3 映射关系至此,我们已经得到了网页集团各个相似类中的代表性网页,下面要考虑将用户需求信息加入进去,从而得到网页集团在信息需求分布上的模糊粗糙集。这样就可以和前面得到的需求信息在Web信息空间的模糊粗糙集进行比较。考虑用模糊粗糙集A和A´的上、下近似之差来描述它们的相似度。定义10 模糊粗糙集A和Aj´间的相似度为:
根据以上定义,求得网页集团内任两个成员网页的混合相似度,就可以得到整个网页集团的模糊相似矩阵。然后,通过λ_截集,对该模糊矩阵进行基于相似关系的相似类划分。再在每个相似类中,选取几个代表性网页,选取标准可以考虑隶属函数及其权重的乘积。3.3 映射关系至此,我们已经得到了网页集团各个相似类中的代表性网页,下面要考虑将用户需求信息加入进去,从而得到网页集团在信息需求分布上的模糊粗糙集。这样就可以和前面得到的需求信息在Web信息空间的模糊粗糙集进行比较。考虑用模糊粗糙集A和A´的上、下近似之差来描述它们的相似度。定义10 模糊粗糙集A和Aj´间的相似度为: 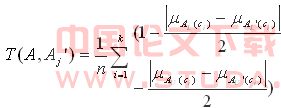 其中,A为用户需求在Web信息空间的模糊粗糙集;Aj´为网页集团j所对应的模糊粗糙集,j=1,2,…,m,即共有m个网页集团;Ci为信息空间的分类类别,i=1,2,…,k。由此可得到搜索优化的具体算法如下:Input:依据前面规则选取的m个网页集团和各自的n´个代表性网页Output:搜索结果网页排序①For j=1 to m (对m个网页集团) Begin
其中,A为用户需求在Web信息空间的模糊粗糙集;Aj´为网页集团j所对应的模糊粗糙集,j=1,2,…,m,即共有m个网页集团;Ci为信息空间的分类类别,i=1,2,…,k。由此可得到搜索优化的具体算法如下:Input:依据前面规则选取的m个网页集团和各自的n´个代表性网页Output:搜索结果网页排序①For j=1 to m (对m个网页集团) Begin ⑤求A´关于(U,R)的一对下近似AL´和上近似AU´,由AL´和AU´构成模糊粗糙集Aj´⑥计算T( A,Aj´),并存入数组sort[j]中endfor⑦对数组sort[j]按照升序进行排序,可得到一个基于用户信息需求与网页集团相关度的排序⑧选取前面几个网页集团,再从每个网页集团中选取Authority值较高的网页显示 ⑨end.4 结论本文所提出的在语义结构和Web链接结构之间,通过基于相似关系模糊粗糙集之间的映射比较,来进行Web搜索优化的方法,有以下几点优势:(1)从用户问题直接搜索小量网页集团,可以减少搜索面,提高搜索的有效性。(2)在分析网页集团内的成员网页间的相似度时,将超链结构与文本信息结合起来考虑,可以提高对网页信息分析的精度。(3)相似分类符合客观实际,如算法分析既属于数学范畴,又属于计算机范畴。(4)粗糙集方法能够获得分类所需的最小特征属性集,利用这些属性能够在不降低精度的条件下提高分类的速度。本文所提出的方法是有效的。[1] Brin S,Page L.The anatomy of a large_scale hypertextual Web search engine[J].In: Thistlewaite P,et al.,eds. Proceedings of the 7th ACM-WWW International Conference. Brisbane: ACM Press,1998.107-117.[2] Kleinberg J.Authoritative sources in a hyperlinked environment.In: Tarjan RE,et al.,eds. Proceedings of the 9th ACM-SIAM symposium on Discrete Algorithms.New Orleans: ACM Press,1997.668-677.[3] Jon Kleinberg,Steve Lawrence.The Structure of the Web[J].In: Science[Z],2001.294[4] 王晓峰,刘惟一. 通过网页集团对Web信息搜索进行优化[J].云南大学学报(版),2003,25(6A):75-78.[5] Gray Willian Flake, Steve Lawrence.Self_organization and Identification of Web Communities.In: IEEE Computer[Z].2002.[6] 刘惟一,田雯.数据模型[M]. 北京:科学出版社,2001.[7] Pawlak Z. Rough sets. Int. J.Computer and Information Sci.,1982,11:341-356.[8] Pawlak Z. Rough sets and fuzzy sets[J].In: Fuzzy Sets and Systems,1985,17:99-102.[9] R.Slowinski et al. A generalized definition of rough approximations based on similarity.In: IEEE Trans. on knowledge and data engineering,2000,12.
⑤求A´关于(U,R)的一对下近似AL´和上近似AU´,由AL´和AU´构成模糊粗糙集Aj´⑥计算T( A,Aj´),并存入数组sort[j]中endfor⑦对数组sort[j]按照升序进行排序,可得到一个基于用户信息需求与网页集团相关度的排序⑧选取前面几个网页集团,再从每个网页集团中选取Authority值较高的网页显示 ⑨end.4 结论本文所提出的在语义结构和Web链接结构之间,通过基于相似关系模糊粗糙集之间的映射比较,来进行Web搜索优化的方法,有以下几点优势:(1)从用户问题直接搜索小量网页集团,可以减少搜索面,提高搜索的有效性。(2)在分析网页集团内的成员网页间的相似度时,将超链结构与文本信息结合起来考虑,可以提高对网页信息分析的精度。(3)相似分类符合客观实际,如算法分析既属于数学范畴,又属于计算机范畴。(4)粗糙集方法能够获得分类所需的最小特征属性集,利用这些属性能够在不降低精度的条件下提高分类的速度。本文所提出的方法是有效的。[1] Brin S,Page L.The anatomy of a large_scale hypertextual Web search engine[J].In: Thistlewaite P,et al.,eds. Proceedings of the 7th ACM-WWW International Conference. Brisbane: ACM Press,1998.107-117.[2] Kleinberg J.Authoritative sources in a hyperlinked environment.In: Tarjan RE,et al.,eds. Proceedings of the 9th ACM-SIAM symposium on Discrete Algorithms.New Orleans: ACM Press,1997.668-677.[3] Jon Kleinberg,Steve Lawrence.The Structure of the Web[J].In: Science[Z],2001.294[4] 王晓峰,刘惟一. 通过网页集团对Web信息搜索进行优化[J].云南大学学报(版),2003,25(6A):75-78.[5] Gray Willian Flake, Steve Lawrence.Self_organization and Identification of Web Communities.In: IEEE Computer[Z].2002.[6] 刘惟一,田雯.数据模型[M]. 北京:科学出版社,2001.[7] Pawlak Z. Rough sets. Int. J.Computer and Information Sci.,1982,11:341-356.[8] Pawlak Z. Rough sets and fuzzy sets[J].In: Fuzzy Sets and Systems,1985,17:99-102.[9] R.Slowinski et al. A generalized definition of rough approximations based on similarity.In: IEEE Trans. on knowledge and data engineering,2000,12.
下一篇:基于混沌的组合域数字水印算法