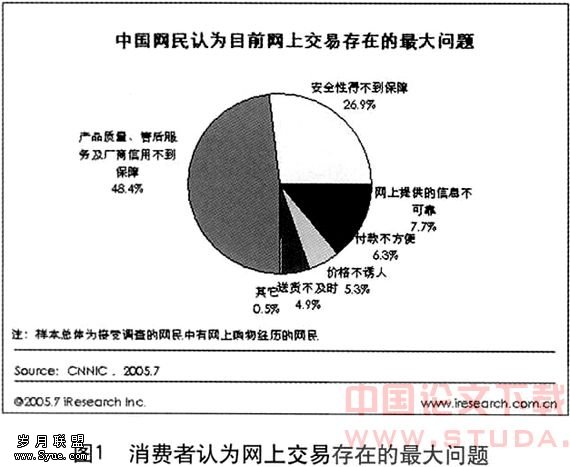
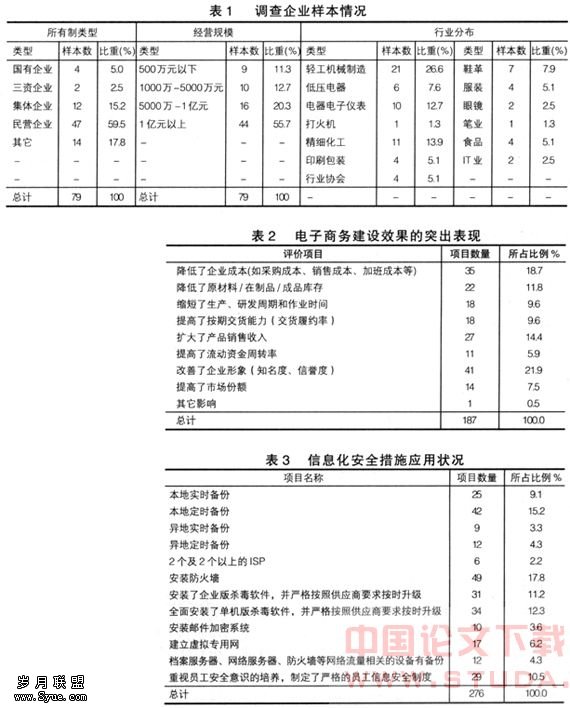
个性化电子商务系统中的自适应过滤算法探究
来源:岁月联盟
时间:2010-07-01
[关键词]个性化电子商务;自适应过滤算法;闽值优化算法;精确度;特征选择
电子商务伴随着互联网飞速发展,同时也为和顾客带来了一个新局面:企业发现竞争日益激烈,生存日益艰难;顾客发现产品日益增多,但信息处理负担日益加重,选择自己所需的产品日益困难。因此,亟需新的市场战略,如一对一的销售、客户关系管理等。学术界和实践者已强调了这一紧迫性。而个性化推荐,即为每个客户推荐一个产品清单供其选择,就是实施这些新战略的方案之一。
目前已经有许多推荐技术,其中协同过滤技术是当前最为成功和广泛使用的个性化推荐技术。它被广泛应用于网页、电影、文章和产品的推荐,作用原理是先识别出具有相似产品需求的顾客群,然后为这一顾客群推荐产品。然而,尽管这些推荐技术业已成功,但仍暴露出一些广为人知的可能导致不良推荐的局限性,如算法的可扩展性、评价数据的稀疏性和初始资源推荐问题。
鉴于此,笔者提出一个新的基于向量空间模型的自适应过滤算法。该算法改进了传统算法,并将自适应反馈研究机制引入智能控制中,因此具备两个优点:一是能够进行自我学习来提高精确度;二是过滤过程无需大量的初始文本。
一、自适应过滤算法结构
基于向量空间模型的自适应过滤算法分为两步:训练阶段和自适应过滤阶段。
训练阶段的任务是获取初始过滤轮廓并设置初始阈值。
自适应过滤阶段的主要任务是对轮廓和阈值进行适应性修改。因主题和文档均由向量空间模型展示,所以每个主题和文档都转化为特征向量。
(一)训练阶段的结构
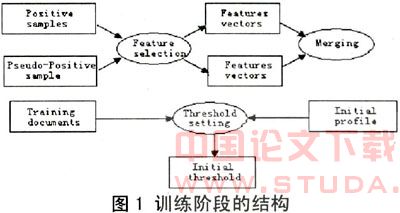
图1显示的是训练阶段的结构。首先从正文档和伪正文档中提取出特征向量。伪正文档即训练集里的那些具有与正文档非常相似的主题却未能标识成正文档的文档。它们可以由多种方式获得,可以通过伪反馈获得,或者通过种类分级结构获得:一个主题的伪正文档之高级种类与训练集提供的高级种类相同。
为得到特征向量,首先剔除禁用词,接着对剩余的词进行形态分析,然后根据公式(1)词语与主题之间的对数交互信息:
logMI(wi,Tj)=log(p(wi/Tj/p(wi)) (1)
上述公式中,wi是第i个词语,Tj是第j个主题。对数交互信息越高,wi和Tj相关性越高。p(wi/Tj)和p(wi)由最大可能性方法估计出。
对于每个主题,选取那些对数交互信息高于3.0而且在有关文档中出现不止一次的词语。对数交互信息不仅被用作选择标准,而且被用作特征词的权重。 得到正文档和伪正文档的特征向量之后,将其合并到初始轮廓中。初始轮廓是正文档和伪正文档的特征向量之加权和。然后根据训练集里每个文档的相似性为每个主题设置初始阈值。轮廓与训练文档之间的相似性由如下余弦公式(2)计算出:
pj是第j个主题的轮廓向量,di是第i个文档的向量,dik是di中第k个词语的权重,由下列公式(3)计算得出:
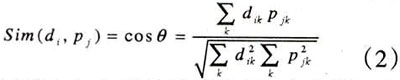
dik=1 log(tfikavdlIdl) (3)
此公式中,如是第i个文档中第k个词语的条件频率,dl是形态处理和禁用词剔除之后通过文档标志计数得到的文档长度,avdl是从训练集得到的平均文档长度。根据训练文档的相似性设置每一个初始阈值以达到最高过滤性能。
(二)自适应性算法的结构
自适应过滤是自适应过滤算法的一个非常重要的阶段。我们从训练阶段得到了初始轮廓和阈值。当过滤输入文档时,主题轮廓和阈值则依据各种不同信息,如:用户反馈、输入文档的向量等进行自适应更新。
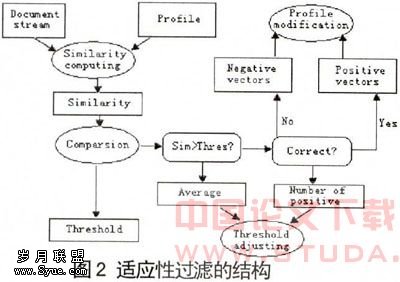
图2显示了适应性过滤的结构。当一个文档到达时,其与主题的相似性即被计算出。如果该相似性高于当前阈值,则这个文档被找回,用户的相关性判断也由此得出。如果该文档真正与主题相关,则其被认为是正实例,反之则是负实例。正实例和负实例的向量根据公式(4)被用于主题轮廓的修改。
p'j=pi αpj(pos) βpj(neg) (4)
p'j是修改后的主题轮廓,pj修改前的主题轮廓,pj(cos)是更新阶段得到的正实例的向量,pj(neg)是更新阶段得到的负实例的向量;α和β分别是正向量和负向量的权重。
(三)阈值优化算法
笔者提出一个新的阈值优化算法。定义该算法使用下列符号:
t:文档编号,可以看作是时问,因为文档是按照时间顺序处理的;
n(f):被处理的文档的数量;
nR(f):找回的相关文档;
nN(f):找回的不相关文档;
T(t):在t时刻的阈值;
S(tk,tk 1t):在(tk,tk 1)时间段中被拒绝的文档的平均相似性;
P(tk tk 1):在(tk,tk 1)时间段中过滤的精确度,并且p(tk,tk 1)=nR(tk 1-nR(tk/n(tk ))-n(tk) (5)
如果我们凭直觉处理,精确度太低就应该提高阈值,很少文档被找回则降低阈值。我们使用S(tk,tk 1)和P(tk,tk 1)来决定是提高阈值抑或降低阈值。
调整阈值的算法如下所示:
IF p(tk,tk 1)≤EP(ttk 1) THEN
T(tk 1)=T(tk) α(tk 1)(1-T(tk))
ELSEIF S(ttk,tk 1)<T(tk)r THEN
T(tk 1)=T(tk)Dt1 S(tk,tk 1)Dt2
ELSE
T(tk 1)=T(tk)Dt1 S(tk,tk 1)Dt2
α(tk 1)是阈值提高系数,β(tk 1)是阈值降低系数,它们也可以被看作是关于nR(t)的函数。在试验中,我们采用nR(t)的线性函数,该函数如公式(6)、公式(7)所示:

αo是初始提高系数,β是初始降低系数,参数u代表应该用于调整阈值、修改轮廓的正文档的最大数量。我们设置αo=0.02,u=0.1,(应该是βo吧)μ=300。从以上等式可以看出,随着时间推移,nR(tk)将逐渐增大,α(tk)和β(tk)将逐渐减小。这也反映出过滤将越来越好,调整步阶将越来越小这一趋势。
参数r表示:如果s(tk 1,tk)低于T(tk 1)r,阈值应该由系数D1和D2来降低。在试验中,我们设置r=0.1,=0.8,=0.2。
EP(t 1k)表示我们所期望的过滤应该在tk时刻达到的精确度。我们首先将其作为常数,尝试不同的值来观察过滤性能,但是结果不尽如人意。我们意识到在过滤初期就希望达到最终期望精确度是不正确的,因而采用了一个逐渐上升的函数,该函数如公式(8)所示:
EP(tk 1)=P (Pfinal-P0)nR(tk 1)IU
(8)
P0和Ptfinal分别是过滤初期和过滤末期我们所希望过滤达到的精确度。
nR(tk 1)-nR(tk)的值决定着过滤对阈值的调整频率,其越小表明过滤对阈值的调整越频繁。在我们的适应性过滤中,我们将其设为1,即意味着过滤只在找回一个正实例之后才调整阈值。
二、试验
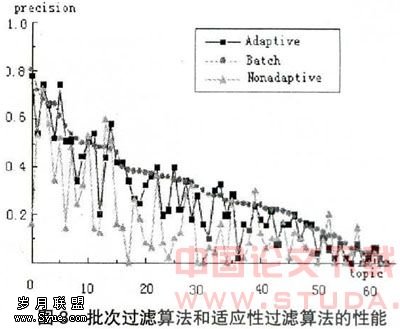
根据研究,我们将个性化服务系统的合作项目与社区结合起来。笔者构建了一个基于为特定社区服务的商务的个性化推荐系统网站。为得到对比试验结果,传统的过滤批次算法和自适应过滤算法被分别应用于个性化社团过滤模块中。试验数据从上面提及的电子商务网站得到,并划分成两个集合:训练实例(5062个社区)和测试实例(4028个社区)。64个主题也被用于该试验。试验结果如图3所示。x轴是64个主题按照精确度从高到低排列,Y轴是传统批次过滤和自适应过滤对于每个种类的精确度。传统批次过滤为每个主题提供了12个相关社团,适应性过滤则提供了3个。此外,每个种类只有3个相关社团。
从图3可以看出,批次过滤算法的性能下降不快,两条曲线非常接近。事实上,两个平均值分别是30.9%和25.8%,范围只降低了16.3%。但是,大多数种类的精确度在不使用适应性过滤算法的情况下下降很多,平均精确度是17.6%,下降45.2%。这就完整揭示了自适应功能。
三、结论
综上所述,笔者提出一个新的基于向量空间模型的用于电子商务的自适应过滤算法。将该算法应用于基于电子商务的个性化服务系统中进行测试,测试结果证明它是有效可行的。希望本文能为其他研究者提供一定的价值。
下一篇:用JSP访问电子商务网站数据库