基于机器学习检测僵尸网络中的域名生成算法
来源:岁月联盟
时间:2020-03-16

FANCI系统使用的许多特征实际上不会在比较测试中使用,特征如上表。例如FANCI的特征5,具有有效TLD是二分类特征,表示该域名具有有效的顶级域。显然,没有DGA会输出带有无效TLD的域名,因为这些域名将永远无法解析,因此毫无用处。但此特性在FANCI系统中非常有用,因为它可以轻松检测域名TLD部分中的人为输入错误,因此,这些错误显然不是DGA生成的域名。
0x06 DGA CLASSIFICATION RESULT
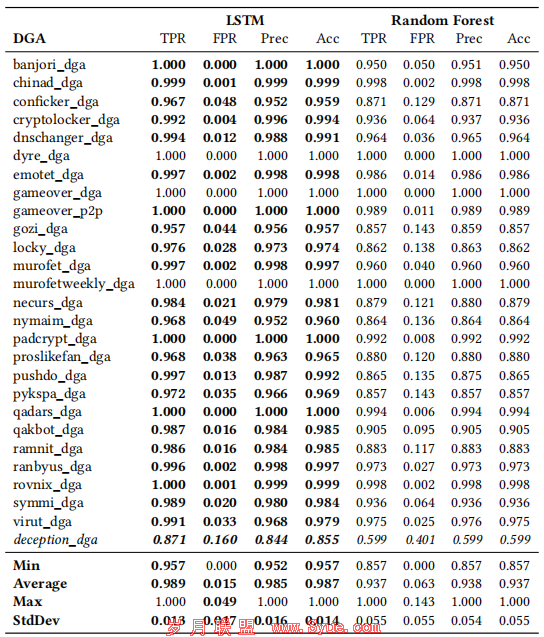
下表中列出了两个分类器测试DGA的分类结果。对于所有测试DGA,LSTM分类器得出的检测率(TPR),误报率(FPR),精度和准确性。平均而言,随机森林分类器的FPR是LSTM的4倍以上。 LSTM分类器的平均准确性为98.7%,而随机森林分类器的平均准确性为93.7%。
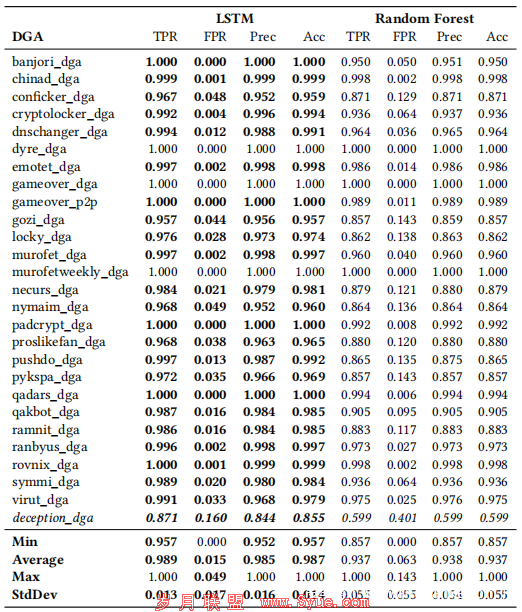
随机森林分类器的FPR标准差是3倍,随机森林分类器准确性的标准差是4倍,这表明LSTM不仅产生了更好的分类结果,而且获得了更高的不同DGA的分类结果一致性。值得注意的是,具有FANCI功能的随机森林在gozi_dga,locky_dga,nymaim_dga,pushdo_dga和pykspa_dga DGA上的性能要差得多。
LSTM分类器更好的一致性的一种可能解释是,LSTM网络在训练过程中会自动学习其使用的分类特征,而随机森林需要人工特征工程,这可能会更好或更不适合不同的DGA。但是,使用人工特征工程还存在另一个危险:DGA开发者可以了解到使用的特征并修改域名生成算法以使其变得不易检测。
0x07 Design a new DGA

接下来利用FANCI分类结果创建一个新的DGA,将其命名为deception_dga,该DGA考虑了分类器的特征以规避检测。攻击者迭代地改善其DGA(如上图),直到获得所需的次优分类结果为止,从而有效地绕过了DGA检测分类器。在创建deception_dga DGA时仅使用了Alexa列表中的数据,模仿了DGA作者可用的信息。
下图显示了DGA“模拟”不同特征时分类准确性的影响。通常,随着DGA模拟更多特征,随机森林分类器的准确性开始下降。新的DGA还给LSTM带来了困难,将其精度降低到0.855,这是LSTM迄今为止记录的最低水平,与gozi_dga,locky_dga,nymaim_dga,pushdo_dga和pykspa_dga DGA的随机森林精度相当。 LSTM上的回合数从10增加到15,将精度稍微提高到0.860。将LSTM输出空间维数从128更改为256,可以得到0.865的分类精度。同时应用较大的输出空间维数和将训练时期数增加到15个组合,仍会产生0.864的分类精度。
0x08 Conclution
在本工作中比较了当足够数量的DGA生成的域名时,机器学习中两种用于检测域名生成算法的方法。结论表示深度学习方法始终优于具有人工特征工程的随机森林,其中递归神经网络评均分类精度为98.7%,而随机森林的分类精度为93.8%。
结果还表明,人工特征工程的缺陷之一是DGA可以基于用于检测的特征知识来调整其策略。为了证明这一点,利用所使用特征集合的知识设计了一个新的DGA,它使随机森林分类器分类精度下降到59.9%。深度学习分类器也受到影响(尽管影响较小),其准确性降低到85.5%。
上一页 [1] [2]