用NodeJS实现反爬虫,原理&源码放送
爬虫,网络安全最大的威胁之一!
根据爬取数据类型而分,爬虫有不少种类,比如爬取Email地址的、爬取商品价格的、爬取图片的,而最多的是爬取内容的,内容数据爬虫是为泛滥的!
爬虫让很多人对其深感苦恼,今天的Node.JS实战,将实现一种防护性能很强的反爬虫系统。
首先展示防护效果,然后付上完整代码,以了解实现方法。
防护效果展示
根据两个核心思路进行效果展示如下:
1、字体加密
创建自定义字体库,将字体进行加密。
举一个最直白的例子:
比如要在网页中显示文字:“我是我,你是你,她是她”,在正常的情况下,网页中就是存在这几个字,爬虫当然可以爬取。
我们要实现的效果是,让这几个字不存在,网页源码中可能是:
但是在网页中可以正常显示: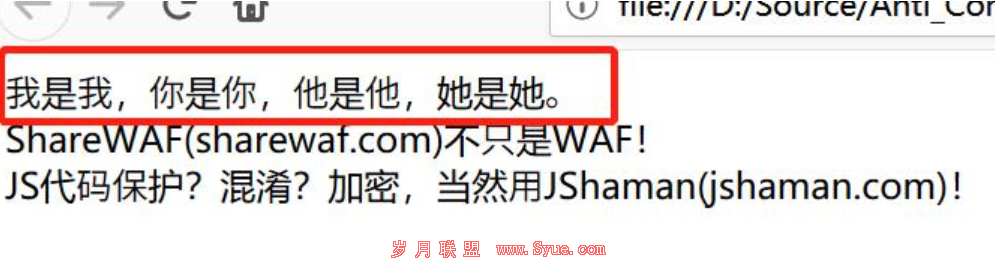
但是却不可复制,复制后,全部或部分内容将不能正常显示: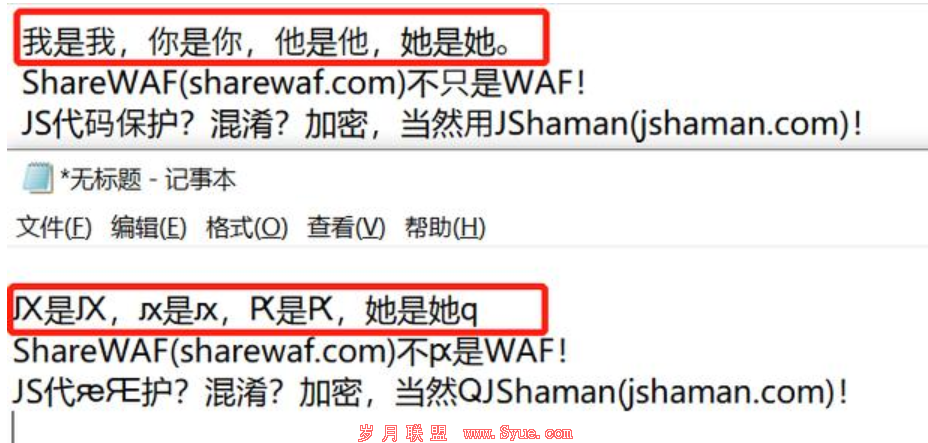
2、字体防破解
单纯的字体加密,是不太难被破解的,因为上述的“密文乱码符号”,其实也就是一种对应关系,例如:“A”对应“啊”,“B”对应“不”。只要获得足够的对应关系,替换就可以破解还原出原内容。
具体实施时,可以从网页中获取字体文件。
如TTF,通过格式转换,化为TTX,即可得到对应关系。
也可以手动记录对应关系。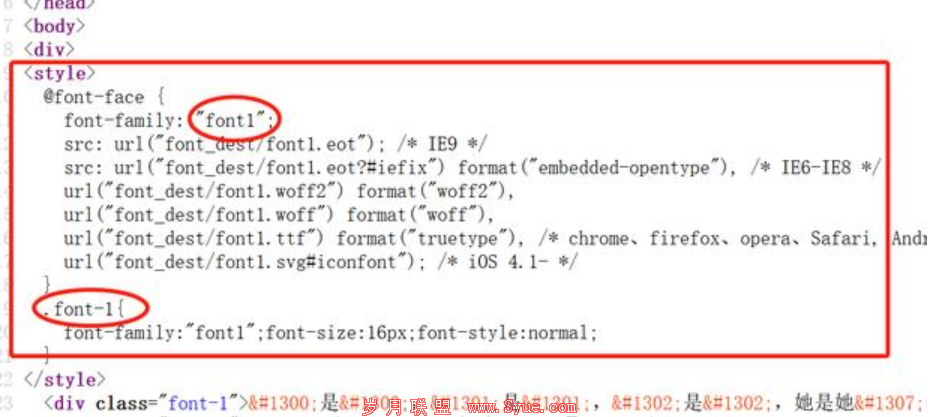
那么对于这两种破解,我们也需要进行防护。
1、防止字体文件被下载;
动态字体路径:
注意以下两图,不同的字体路径: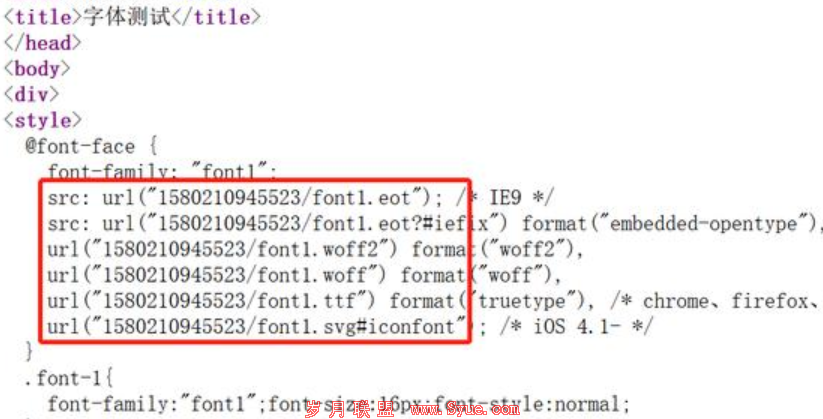
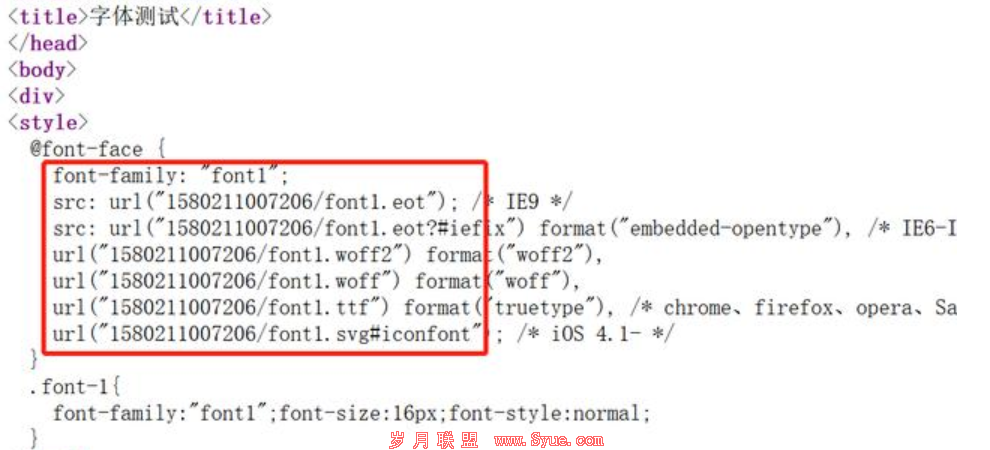
即:每次访问都是不同的字体路径,而且,此动态路径文件是不可下载的:
当然,文件的正常使用是不受影响的。
2、使用动态对应关系,防止字体对应被获取。
我们内置一套系统,自动或手动实现编码变化:
以下两图,两种不同的编码展示,前面部分是编码,后面是对应的字: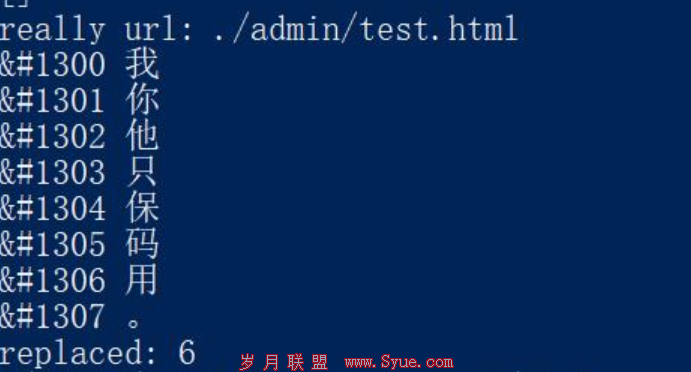

源码展示
实现以上功能的代码并不复杂,本例由两个文件,一个目录组成:
acs.js是主文件,内容如下:
/**
* Anti Content Splider
* Auther:WangLiwen
* www.ShareWAF.com
*/
var fs = require('fs')
var font_carrier = require("font-carrier")
var body_parser = require("body-parser")
var mime = require("mime");
//变码矩阵,存放字和unicode的对应关系
var transfer_result = require("./config").tramsform_matrix;
/**
* TTF变码
* 基于一种字体,生成另一种新字体
* 参数:ttf,原始字体
* 参数:words,要变码的字
* 参数:new_ttf,新的字体
* 返回值:新字体中,unicode和字的对应关系
*/
function transform_ttf(ttf,words,new_ttf){
//创建新的空字体
var font = font_carrier.create()
//从ttf字体中获取文字
var font_transfer = font_carrier.transfer(ttf)
if(words.length==0){
return{};
}
var result={};
var key,value,word;
//遍历传入的参数:要变码的字体
for(var i=0;i//新的unicode
key="‚"+i;
//unicode对应的字
value=words[i];
//字形
word=font_transfer.getGlyph(words[i]);
//加入到新字体中
[1] [2] [3] [4] 下一页