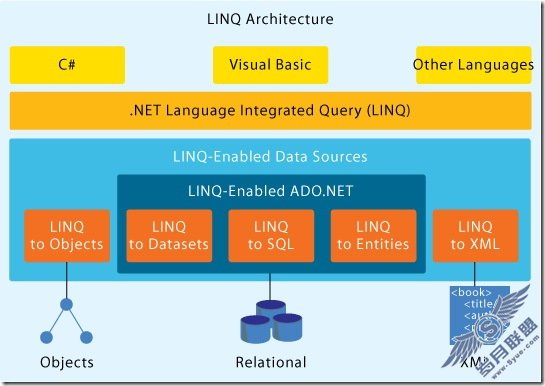
那些年,我收集的一些.net函数。分享给大家,项目中有些是经常用到的。
分享几个常用的函数,希望对大家有帮助。
一:由于类似在帖子,新闻列表的时候往往有个帖子。这时候就得过滤html标签了。过滤html标签的网上百度下有蛮多的。分享下当摘要中有图片的时候的过滤图片的函数:
public string removeIme(string s)
{
string str = s;
str.Replace("IMG", "img");
string reg = "<img//s+[^(src>)]*src//s*=//s*[/"']{0,1}(?<SRC>[^(//s/"'>)]*)[/"']{0,1}//s{0,1}[^>]*>";
while (Regex.IsMatch(str, reg))
{
str = str.Replace(Regex.Match(str, reg).Value, "图片..");
}
r
二:SQL注入攻击是web网站的安全难题。能否做到防注入也成为了重要课程。除了在sql语句,存储过程中做功夫外,我分享下对前台用户输入检测的一个函数。
public static string InputText(string text, int maxLength)
{
text = text.Trim();
if (string.IsNullOrEmpty(text))
return string.Empty;
if (text.Length > maxLength)
text = text.Substring(0, maxLength);
text = Regex.Replace(text, "[//s]{2,}", " "); //two or more spaces
text = Regex.Replace(text, "(<[b|B][r|R]/*>)+|(<[p|P](.|//n)*?>)", "/n"); //<br>
text = Regex.Replace(text, "(//s*&[n|N][b|B][s|S][p|P];//s*)+", " "); //
text = Regex.Replace(text, "<(.|//n)*?>", string.Empty); //any other tags
text = text.Replace("'", "''");
return text;
}
三:ubb是当前流行,较为完全的代码。也是防范sql注入和跨站脚本的手段之一。分享下将ubb转化成html代码的函数。
public static string decode(string argString)
{
string tString = argString;
if (tString != "")
{
Regex tRegex;
bool tState = true;
tString = tString.Replace("&", "&");
tString = tString.Replace(">", ">");
tString = tString.Replace("<", "<");
tString = tString.Replace("/"", """);
tString = Regex.Replace(tString, @"/[br/]", "<br />", RegexOptions.IgnoreCase);
string[,] tRegexAry = {
{@"/[p/]([^/[]*?)/[//p/]", "$1<br />"},
{@"/[b/]([^/[]*?)/[//b/]", "<b>$1</b>"},
{@"/[i/]([^/[]*?)/[//i/]", "<i>$1</i>"},
{@"/[u/]([^/[]*?)/[//u/]", "<u>$1</u>"},
{@"/[ol/]([^/[]*?)/[//ol/]", "<ol>$1</ol>"},
{@"/[ul/]([^/[]*?)/[//ul/]", "<ul>$1</ul>"},
{@"/[li/]([^/[]*?)/[//li/]", "<li>$1</li>"},
{@"/[code/]([^/[]*?)/[//code/]", "<div class=/"ubb_code/">$1</div>"},
{@"/[quote/]([^/[]*?)/[//quote/]", "<div class=/"ubb_quote/">$1</div>"},
{@"/[color=([^/]]*)/]([^/[]*?)/[//color/]", "<font style=/"color: $1/">$2</font>"},
{@"/[hilitecolor=([^/]]*)/]([^/[]*?)/[//hilitecolor/]", "<font style=/"background-color: $1/">$2</font>"},
{@"/[align=([^/]]*)/]([^/[]*?)/[//align/]", "<div style=/"text-align: $1/">$2</div>"},
{@"/[url=([^/]]*)/]([^/[]*?)/[//url/]", "<a href=/"$1/">$2</a>"},
{@"/[img/]([^/[]*?)/[//img/]", "<img src=/"$1/" />"}
};
while (tState)
{
tState = false;
for (int ti = 0; ti < tRegexAry.GetLength(0); ti++)
{
tRegex = new Regex(tRegexAry[ti, 0], RegexOptions.IgnoreCase);
if (tRegex.Match(tString).Success)
{
tState = true;
tString = Regex.Replace(tString, tRegexAry[ti, 0], tRegexAry[ti, 1], RegexOptions.IgnoreCase);
}
}
}
}
return tString;
}
摘自 青牛客