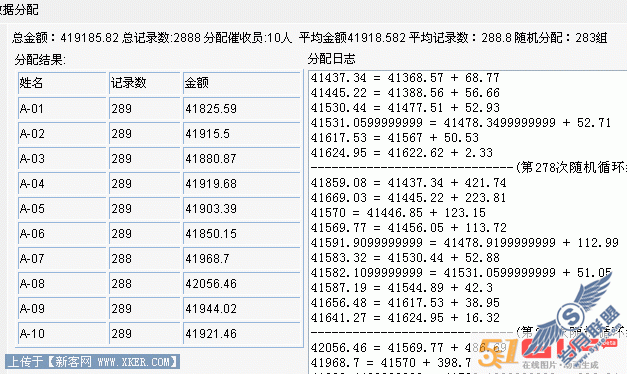
下面识别OCR验证码用.NET来实现,主要使用到Tesseract组件
来源:岁月联盟
时间:2012-03-16
.NET版本Tesseract下载地址:
http://www.pixel-technology.com/freeware/tessnet2/
另外发现这个用法非常简单,注意还需要下载语言包,我这里识别的是纯字母的,所以就用英文的语言包了。另外为了提高验证率,还可以自己进行训练,由于我的需求比较简单,我就没有做这个步骤了,直接使用英文语言包了。
关键测试代码:
ocr = new tessnet2.Tesseract();
ocr.SetVariable(“tessedit_char_whitelist”, “0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ”);
ocr.Init(Application.StartupPath @”/lng/eng”, “eng”, false);
WebClient wc = new WebClient();
byte[] oimg = wc.DownloadData(“some url”); // 这里我地址做了隐藏,自己修改成要识别的地址吧
Bitmap bp = new Bitmap(new MemoryStream(oimg), true);
pictureBox1.Image = bp;
bp = ImageProcess.RemoveGreen(bp);
bp = ImageProcess.ToBW(bp);
pictureBox2.Image = bp;
List<tessnet2.Word> result = ocr.DoOCR(bp, Rectangle.Empty);
string txt = “”;
foreach (tessnet2.Word word in result)
{
txt = word.Text;
}
textBox1.Text = txt;这里先对图像进行了简单的预处理,去除干扰,转换成二值图像。对于简单的验证码,效果还不错