专家仔细讲解分布式数据库的优劣说
假设恢复、诊断、优化和局域网结构中的问题能得到解决,分布式数据库系统将有更加长足的发展,并将成为未来计算机发展的一个重要领域。
20世纪70年代以来,由于计算机网络通信的发展,以及地理上分散的各种公司、团体和组织对数据库更为广泛应用的需求,在集中式数据库系统成熟技术的基础上产生和发展了分布式数据库系统。
分布式数据库系统是数据库技术和网络技术两者相互渗透和有机结合的成果,在数据库领域已形成一个分支。经过将近三十年的发展,分布式数据库已经发展的非常成熟,推出了很多实用化的系统。
世界上第一个分布式数据库系统SDD-1是由美国计算机公司(CCA)于1979年在DEC计算机上实现。
20世纪90年代以来,分布式数据库系统进入商品化应用阶段,传统的关系数据库产品均发展成以计算机网络及多任务操作系统为核心的分布式数据库产品,同时分布式数据库逐步向客户机/服务器模式发展。
成熟的产品从早期原INGRES公司的INGRES/STAR,Oracle公司的SQL*STAR到现在Sybase公司的SQL REPLICATION SERVER等。
怎么样的一个数据库系统才能称得上是一个分布式系统?分布式系统有两个必须满足的特征:
1. 分布性。数据库中的数据不是存储在同一个场地,更确切的说,是数据不是存储在同一台服务器的存储设备上,或者说,是存储在多个独立的数据库服务器中。
2. 逻辑整体性。分布式数据库系统中的数据是相互联系的,逻辑上是一个统一的整体,也就是从外界看来,就像是一个集中式数据库系统。
这也是分布式数据库系统区别于那些分散在计算机网络上的不同节点上的集中式数据库或者文件系统的区别。后者在逻辑上是没有内在的联系。
下面我们通过分析两个例子来描述分布式数据库和集中式数据库的区别。
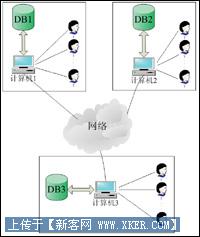
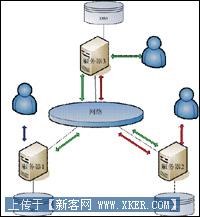
在上面描述的系统中,有三台服务器,每台服务器有自己的数据库系统,三台服务器之间通过网络相连接。每台服务器都有各自的客户端,用户可以直接通过客户机来对本地数据库中的数据执行局部应用;也可以通过客户机对两个或者两个以上的节点中的数据库执行全局应用。
全局应用对用户来说是透明的,用户并不关注数据存储的位置,用户只需要根据需要发出查询的请求。
客户机屏蔽了数据库的这种分布性。在图中描述了三种查询操作,用户1执行的是查询操作1,如蓝色线条所示,只需要对服务器1的数据进行查询就可以获得结果;用户2执行的是查询操作2,如红色线条所示,不仅需要查询服务器2的数据,同时也需要通过网络对服务器3的数据进行查询;而用户3执行的查询操作3则需要对三个数据库进行访问。
上面描述中的配置与图1的不同之处在于三个后台数据库通过网络连接,服务器执行数据库管理功能,只有一个前台的客户机面向用户,尽管这样的系统可以将数据分布在不同的场地,但是这样的系统不是分布式数据库系统。原因在于每个数据库系统并不是一个单独的系统,不能执行局部的数据应用。
所以,分布式数据库的这种分布性不仅仅是要求物理上的分布,而且这种分布应该是面向应用的。
分布式数据库系统是在集中式数据库系统的基础上发展起来的,但是分布式数据库系统并不是简单的将集中数据库分散到不同的场地,它的实现具有自己的特征。
在实现数据库的独立性、数据共享、数据冗余、并发控制、完整性、安全性、事务处理等方面具有更加丰富的内容。我们可以总结出分布式数据库具有以下特点:
◆ 数据的物理分布性与逻辑整体性:
数据的物理分布性是分布式数据库系统区别于集中式数据库系统的显著特征。数据的逻辑整体性是分布式数据库系统与分散式数据库系统的最大区别。
这种逻辑整体性也可以称之为数据的分布透明性。也就是用户不必关心数据的逻辑分片,不必关心数据物理位置的分布细节,同时也不必关心数据的冗余处理、不必关心具体某个场地的数据库类型。在用户看来,所有的这些不同的数据库都是一个完整的整体。
◆ 场地自治和协调:
数据库是一个多用户共享的资源,在分布式数据库系统中,数据的共享分为两个层次,局部共享和全局共享。
局部共享是指局部场地上存储的该场地上用户之间的共享数据,在本地用户之间共享这些数据;全局共享则是分布式数据库系统中各个场地存储的供其它场地用户使用的共享数据,支持全局的应用。
所以,分布式数据库系统常采用集中和自治相结合的控制策略。局部的DBMS可以管理该场地的数据库,具有自治功能;同时,系统中又设置有全局集中控制机构,来对各个独立的数据库进行协调,执行全局应用。
◆ 数据的冗余及冗余透明性:
在分布式数据库系统中,常常需要增加冗余数据,在不同的场地存储数据的多个副本。
通过增加冗余数据,可以提高系统的可靠性,当某个场地的数据出现故障之后,可以利用其它场地的数据进行操作;另外也提高了系统性能,用户可以选择最近的副本,减小网络开销。
这种冗余对用户来说是透明的,但是,数据冗余也增加了分布式数据库更新维护方面的操作成本,需要着重处理数据的不一致问题。
◆ 事务管理的分布性:
数据分布性造成事务执行和管理的分布性。在分布式数据库系统中,全局的应用需要涉及到两个以上的节点,而全局的事务则可能由不同场地上的多个操作组成。这样,如果在一个某一个节点发生故障,操作失败了,那么就会有这样的一些问题:如何执行事务的回滚,如何通知其它节点撤回操作,或者是其它节点不必执行事务其它操作等等。
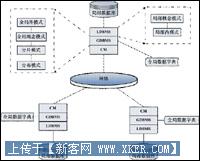
从逻辑角度来说,分布式数据库系统一般都具有如下的模式结构:
由上图可知,一个分布式数据库系统由四部分组成:
1. LDBMS:局部数据库管理系统。功能是建立和管理局部数据库,提供场地自治功能,执行局部应用以及全局查询的子查询。
2. GDBMS:全局数据库管理系统。提供分布的透明性实现,协调全局事务处理,保证数据库全局应用的一致性、并发控制、全局恢复等功能。
3. 全局数据字典:存放全局概念模式、分片模式、分布模式的定义以及各模式之间的映像定义,存储用户、权限等数据库安全信息。
4. 通信管理:在分布式数据库各个节点之间传递消息和数据,完成通信功能。
在实际的应用中,由于LDBMS和GDBMS的不同配置策略导致了不同的分布式数据库系统的分类:同构型、异构型、集中型、分散型和可变型。
同构型是指在各个结点行的数据库数据模型相同,譬如都是采用关系型数据库,同时又可以细分为同构同质型和同构异质型。同质是指采用的数据库产品是一样的,比如都是DB2数据库;异质是指采用不同的数据库产品,比如采用DB2和Oracle。
集中型的分布式数据库系统的全局控制信息位于一个中心的结点上,所有对全局的访问操作必须通过全局结点来控制。而分散型则是在每一个结点上都有全局控制信息的一个副本。
可变型的分布式数据库系统的全局信息保存在一组主结点中,另外还有一组辅节点没有全局控制信息。
接下来介绍几种典型分布式数据库系统。
1. ENCOMPASS:
ENCOMPASS是一种同构型分布式数据库管理系统,它是根据Tandem公司的Non Stop计算机体系结构和GUARDIAN OS建立起来的。计算机的体系结构和OS两者都具有对实现分布式数据库管理系统极其有用的特性。
Tandem公司的计算机的最好的特性在于它是由几个(至少两个)独立CPU组成。因为Tandem公司的计算机的基本体系结构是分布式的,所以Guardian操作系统能在由不同CPU执行的各进程之间提供方便的通信。
根据这种计算机体系结构和OS,分布式数据库管理系统能够提供数据分布查询处理和分布式事务处理的管理。
2. SDD-1 DDBMS:
美国计算机公司(Computer Corporation of America)研制的SDD-1项目是第一个分布式数据库管理系统的样机。它是在1976年到1978年间设计的,并于1979年在DEC-10和DEC-20型号的计算机上实现。
各地点由ARPANET连接,并采用叫做数据计算机的当前DBMS。这个项目特别有助于理解分布式数据库的重要问题和对其中某些问题的解决方法。
SDD-1的体系结构是基于三个相对独立的虚拟机:数据模块、事务处理模块和可靠的网络。这种体系结构允许把分布式数据库管理问题分成三个系统,以限制相互的影响。
SDD-1一直是分布式数据库管理方面的一个大型项目,并且验证了许多新技术,并第一次应用了许多设想(如:段存储、连接、并发控制的时标、假脱机器和备用协调者等)。
SDD-1的整个体系结构在各模块和半各层次中具有清楚的分解编译。然而,SDD-1系统的性能不佳。其某些特征似乎比较差,例如保守的并发控制、不支持网络划分等。
3. IBM System R* :
R*系统是在美国CA州的IBM San Jose Research Laboratory开发的。它的目的是建立由协同操作,但却是独立的地点构成的分布式数据库系统。每个地点支持一个关系数据库系统。R*是R系统向分布式环境的自然扩展。
R*系统由3个主要部分组成:局部DBMS、提供信息传输的数据通信部分和能协调实现多地点事务处理的事务处理管理程序。
局部DBMS可进一步分为两个部分:存储系统(用于数据的存储与检索),数据库语言处理器(用于将高级SQL语句转换成存储系统上适用的操作命令)。
尽管R*是一种研究样机,但是它是采用系统的和有效的方式开发出来的,利用了用于事务处理管理的大部分成熟技术(2阶段锁定和2阶段提交)。这个原型机可以看作是开发先进系统的重要基础。
总的看来,分布式数据库兴起于20世纪70年代,繁荣于80年代,而在90年代分布式数据库更是以其在分布性和开放性方面的优势又获得了青睐,进入21世纪之后,分布式数据库持续发展。
现在,应用领域已经不再是局限于OLTP应用,从分布式计算、因特网应用、数据仓库系统等等都可以找到分布式数据的身影。
而随着硬件条件的改善、网络环境的日益普及等,新的应用也呈现出来许多类似的特点。
例如,数据仓库系统一般建立在原有的多个数据库系统基础之上,需要从异构的数据库中提取数据并且能够逐步扩展系统的处理能力和系统规模;而越来越多的因特网商业应用都具有分布性和开放性的特点;Web的商业应用也从简单的数据查询、读取转变为分布式的数据读写操作,这样的业务需求都是现有系统所面临的巨大挑战。
所以,促使分布式数据库系统发展的根源在于应用的驱动。目前,分布式数据库是多家硬件和DBMS厂商非常感兴趣的课题,也是高校和科研机构的研究重点。
假设诸如恢复、诊断、优化和局域网结构中的问题能得到解决,那么在现在这样的网络、分布、异构和开放的大环境下,分布式数据库系统将有更加长足的发展,并且将成为未来计算机发展的一个重要领域,得到更加广泛的利用。

链 接
分布式数据库系统是在集中式数据库系统的基础上发展起来的,但并不是简单的将集中数据库分散到不同的场地,它在实现数据库的独立性、数据共享、数据冗余、并发控制、完整性、安全性、事务处理等方面具有更加丰富的内容。