利用ClementineC5.0模型预测CDMA客户流失
来源:岁月联盟
时间:2014-06-01
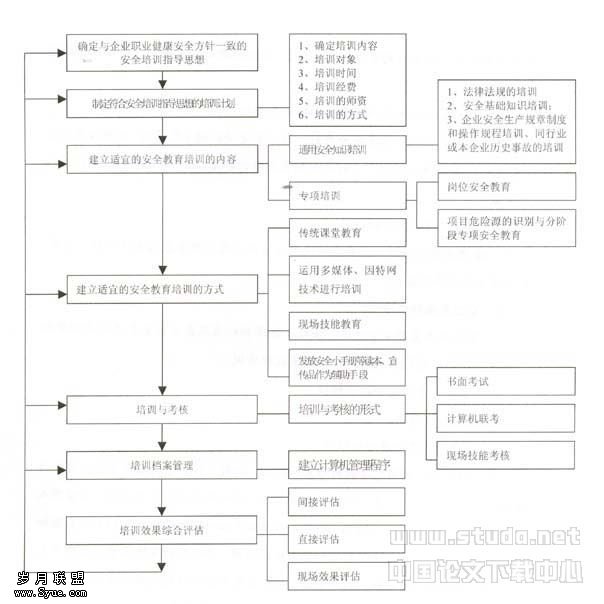
接着我们在模型里面选择C5.0模型,编辑模型的选项,有四种用于构建C5.0模型的训练方法:1.输出类型:指定希望生成的结果模型是决策树还是规则集,根据CDMA客户的性质和要预测的是流失项,在此选用决策树模型。2.群体字符:如果选中此选项,C5.0将试图组合输出字段中具有相似样式的符号值。3.使用推进:这是C5.0算法的一个特殊方法用于提高其准确率。工作原理是在序列中构建多个模型,第一个模型按常规方式进行构建;构建第二个模型时,将焦点集中于由第一个模型误分类的记录;构建第三个模型时,将焦点集中于第二个模型的错误,依此类推。最后,通过将整个模型集应用到观测值,并使用加权投票过程将单独的预测组合为一个总预测来分类观测值。推进可以显著提高C5.0模型的准确性,但也需要更长的训练时间。4.交互验证:此项使用一组模型(根据训练数据的子集构建)来估计某个模型(根据全部数据集构建)的准确性,可以指定用于交互验证的折叠次数或模型数。
C5.0有两种模式提供选择:1.简单模式:将试图生成尽可能精确的树,但有时可能会导致过度拟合,从而在将此模型应用于新数据时导致性能偏低。2.专家模式有以下几点:a.修剪严重性:确定对生成的决策树或规则集的修剪程度,增加该值可获得一个更简洁的小型树,减小该值可获得一个更精确的树。b.每个子分支的最小记录数:可使用子组的大小限制树的任何分支中的分割数,增加该值有助于防止使用噪声数据进行过度训练。c.使用全局修剪:分两个阶段修剪树,第一个阶段是本地修剪,此时将检查子树并折叠分支以提高模型的准确性。第二个阶段是全局修剪,在此阶段中将把树视作一个整体并折叠虚弱的子树。d.辨别属性:此项将在开始构建模型之前检查预测变量的有效性,如果发现不相关的预测变量,系统会自动把它从模型构建过程中排除。这个选项对于那些具有很多预测变量字段的模型非常有效,而且还可以有效地防止数据过于拟合。
单击对话框下面的“执行”按钮后,这样会在右面的窗口中生成的C5.0的模型,打开此模型,我们可看到统计后的数据及此模型的准确度和时间等信息,另外我们还可以在该模型中导出PMML或者SQL等。如果模型的准确度已经达到我们的要求,接下来将生成的模型导入到业务支撑系统中,根据需要在导出模板中选择数据库,输入服务器地址及数据库名称。模型选项和导入SQL数据库如图3-图4所示。
4 数据分析和总结
经过上面的操作,再对其进行分析整理后,可以看出CDMA客户流失的一些特征,如在使用彩铃的客户群中,有24%的流失率,远远超过不使用彩铃的用户,而在这些客户群中,使用彩铃并且在网时长大于25的客户,其流失率更高,达46%以上。这是要重点关注的用户群。分析结果如图5所示。
而在FEE_ALL这一项中,高端客户的流失率较低,CDMA流失最严重的客户群在月消费为10至40的客户,流失率在22%以上,这也是占比最多的一部分。如果CDMA用户捆绑有其他业务,如我的e家等,则流失率较低。而在网时长这一项中,在网时长小于15的客户是流失率较小。
由本研究不难看出,目前电信的客户流失率是一个非常值得关注的问题,对运营商造成影响是非常大的,因此电信运营商应该特别注意容易流失的客户群。挽留老客户,发展新用户。经过多个数据样本分析处理得出本文整体的技术路线是非常可行的,C5.0模型对电信客户流失预测的准确性是相当高的,可以为该电信分公司的经营分析支撑系统提供很好的参考实施价值。
参考文献:
[1] 段云峰,吴唯宁,李剑威,等.数据仓库及其在电信领域中的应用[M].北京:电子工业出版社,
[2] 邵峰晶,于忠清.数据挖掘原理与算法[M].北京:中国水利水电出版社,2003.
[3] 颜昌沁,胡建华,周海河.基于Clementine神经网络的电信客户流失模型应用[J].电脑应用技术,2009(1).
上一篇:试论基于价值管理的企业目标