SPSS在犯罪学研究中的应用——以刑事发案率的多元线性回归为例
导 言
在犯罪与罪犯研究领域,常常会遇到彼此有关系的两列或多列变量。对于这些变量之间的关系,可以根据不同的研究目的,从不同的角度去分析。如果要分析变量之间关系的强度,我们可以采用相关分析的方法,但是,如果要确定变量之间所可能具有的数量关系,并将这种形式表示为某个数学模型,就需要用回归分析。
回归分析应用非常广泛。在犯罪学领域,如果建立了变量之间的数学模型,实际上就是确立了变量之间的关系模型,从而可以从某些变量的变化来预测其他变量的变化情况。例如,我国学者杨家騄建立了物价指数与盗窃犯罪案件之间的数学模型,从而依据某年度的物价指数来预测该年度的盗窃案件数量;[1]我国学者高树桥等在犯罪人的受年限与犯罪次数之间建立了数学模型,根据某犯罪人的教育年限,我们就可以预测其可能的犯罪次数。[2]
但是,由于犯罪现象是一种非常复杂的社会现象,往往牵扯到多个变量之间的关系问题。因此在回归分析中常常需要分析两个及两个以上的自变量,分析变量之间的关系,推导出含有多个自变量的函数,这种方法就是多元回归分析。多元回归分析要比一元回归分析更为,这是由事物的复杂性决定的。例如,盗窃案件的数量不单与价格指数有关,还受其他一系列因素的影响,国外有学者甚至研究了防盗门的销售量与盗窃案件的关系。可见,当我们研究某一个犯罪问题时,多元回归分析更为准确和有效。
多元回归自变量的个数很多,相当繁琐,一般手工计算几乎不大可能,我们可以借助SPSS来满足计算要求。
一、多元线性回归分析方法
多元线性回归的数学模型为:
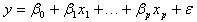
其中,![]() 为应变量;
为应变量;![]() 为p个自变量。
为p个自变量。![]() 为常数项,
为常数项,![]() 称为偏回归系数;
称为偏回归系数;![]() 为随机误差,又称残差,它是
为随机误差,又称残差,它是![]() 的变化中不能用自变量解释的部分,服从
的变化中不能用自变量解释的部分,服从![]()
![]() )分布。
)分布。
多元线性回归分析的前提条件是:线性、独立、正态和等方差,在进行回归分析时,应当首先进行这些假设检验。
还有一个重要问题就是如何选择自变量。实际上,模型中包含的自变量是无法事先确定的,如果把一些不重要的或者对应变量影响很弱的变量引入模型,则会降低模型的精度。所以自变量的选择是必要的,基本思路是:尽可能将对应变量影响大的自变量选入回归方程中,并尽可能将对应变量影响小的自变量排除在外,这样才能建立最优方程。这里就涉及到筛选自变量的方法,现在比较常用的是逐步回归法。这种方法的特点在于,每引入一个自变量,都会对已在方程中的变量进行检验,对符合剔除标准的变量要逐一剔除。
另外,在进行多元线性回归分析中,由于自变量之间还可能具有高度相关关系,导致所建立的模型的解释力受到削弱,因此,还要对模型进行多重共线性检验,最后计算出相对更优的数学模型。
二、对刑事发案率的多元线性回归分析
刑事发案率的影响因素很多,有、、文化等社会因素,也有个体性因素,所涉及的变量相当复杂,创建一个完全周延的数学模型几乎是不可能的。鉴于本文主要是介绍SPSS在犯罪学研究中的意义,同时也为了深化《报告》中关于犯罪率与社会发展指标的研究,因此在社会指标的选择上,仍然参照《报告》所采用的指标,包括人均GDP、受教育状况、城市化和基尼系数。《报告》中只是计算了这四项指标与刑事发案率的相关系数[3],如果要确定他们之间的数量关系,就需要建立数学模型,进行回归分析。
表 SEQ 表 /* ARABIC 1刑事发案率与其他社会指标统计表
年份 | 刑事发案率
| 人均GDP
| 受教育状况
| 城市化
| 基尼系数
|
1992 | 135.9 | 288.4 | 18.6 | 27.46 | 36.92 |
1993 | 137.2 | 323.6 | 21.4 | 27.99 | 37.93 |
1994 | 139.3 | 360.4 | 23.4 | 28.51 | 38.34 |
1995 | 140.3 | 394 | 24 | 29.04 | 37.76 |
1996 | 131.5 | 427.1 | 24.7 | 30.48 | 35.97 |
1997 | 131.2 | 460.3 | 25.7 | 31.91 | 36.81 |
1998 | 159.9 | 491.4 | 27.3 | 33.35 | 36.84 |
1999 | 179.4 | 521.7 | 32.8 | 34.78 | 38.21 |
2000 | 288.1 | 559.2 | 43.9 | 36.22 | 40.13 |
2001 | 350.7 | 596.7 | 56.3 | 37.66 | 42.95 |
2002 | 338.7 | 642 | 70.3 | 39.09 | 46.7 |
2003 | 341 | 697.9 | 86.3 | 40.53 | 47.66 |
数据来源:朱景文,《法律发展报告》,中国人民大学出版社,2007;中国统计年鉴(1993-2005)。其中,刑事发案率是指每10万人口的(公安机关)立案数量;GDP按照人均国内生产总值指数计算,1978年为100;城市化按照城镇人口占总人口的比例计算;受教育状况按照每100000人口大学生数量计算;4.基尼系数是笔者根据中国统计年鉴中的收入分组数据计算得出。
首先绘制散点图(见图1),判断这四个变量对刑事发案率有无影响,借助的是SPSS软件中的多元线性回归分析,使用Stepwise法来进行判断。
图 SEQ 图 /* ARABIC 1 发案率对学生化残差的散点图
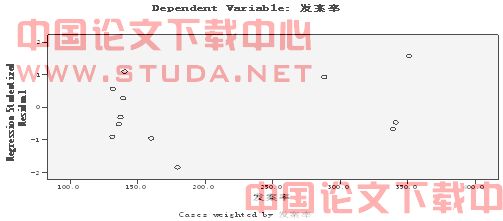
图中观察点学生化残差的绝对值均小于2,也没有发现极端点,这表明人均GDP、城市化、受教育水平和基尼系数对刑事发案率均有影响,该回归模型符合假设,无需重新拟合。
其次,对SPSS生成的结果进行解释。首先看模型的筛选过程(见表2),模型1用逐步法选入了城市化,然后模型2用逐步法选入了人均GDP,城市化仍在模型2中;模型3用逐步法选入了基尼系数,城市化、人均GDP扔在模型3中;模型4用逐步法选入了教育状况,城市化、人均GDP、基尼系数仍在模型4中。
表 SEQ 表 /* ARABIC 2 模型的筛选过程
Variables Entered/Removed(a)
Model | Variables Entered | Variables Removed | Method |
1 | 城市化 | . | Stepwise (Criteria: Probability-of-F-to-enter <= .050, Probability-of-F-to-remove >= .100). |
2 | 人均GDP | . | Stepwise (Criteria: Probability-of-F-to-enter <= .050, Probability-of-F-to-remove >= .100). |
3 | 基尼系数 | . | Stepwise (Criteria: Probability-of-F-to-enter <= .050, Probability-of-F-to-remove >= .100). |
4 | 教育状况 | . | Stepwise (Criteria: Probability-of-F-to-enter <= .050, Probability-of-F-to-remove >= .100). |
a Dependent Variable: 发案率
表3是拟合的四个模型决定系数的变化情况,从调整的决定系数来看,随着人均GDP、基尼系数、教育状况等变量的载入,模型4可解释的变异占总变异比例比模型1、2、3均高,但是,高出的数值有限。
表 SEQ 表 /* ARABIC 3 拟合的四个模型决定系数的改变情况
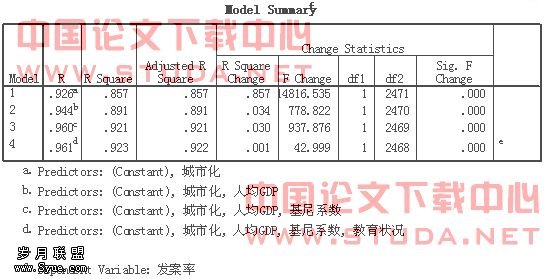
表4是对拟合的4个模型的方差分析检验结果。由结果可知,四个模型都有统计学意义。但是,模型有统计学意义不等于模型内所有的变量都有统计学意义。还需要进一步对各自变量进行检验。
表 SEQ 表 /* ARABIC 4 对拟合的4个模型的方差分析检验结果
Model |
| Sum of Squares | Df | Mean Square | F | Sig. |
1 | Regression | 19025829.263 | 1 | 19025829.263 | 14816.535 | .000(a) |
| Residual | 3173254.074 | 2471 | 1284.094 |
|
|
| Total | 22199083.337 | 2472 |
|
|
|
2 | Regression | 19786488.765 | 2 | 9893244.383 | 10129.465 | .000(b) |
| Residual | 2412594.572 | 2470 | 976.680 |
|
|
| Total | 22199083.337 | 2472 |
|
|
|
3 | Regression | 20450610.941 | 3 | 6816870.314 | 9626.813 | .000(c) |
| Residual | 1748472.396 | 2469 | 708.113 |
|
|
| Total | 22199083.337 | 2472 |
|
|
|
4 | Regression | 20480549.642 | 4 | 5120137.410 | 7353.666 | .000(d) |
| Residual | 1718533.695 | 2468 | 696.270 |
|
|
| Total | 22199083.337 | 2472 |
|
|
|
a Predictors: (Constant), 城市化
b Predictors: (Constant), 城市化, 人均GDP
c Predictors: (Constant), 城市化, 人均GDP, 基尼系数
d Predictors: (Constant), 城市化, 人均GDP, 基尼系数, 教育状况
e Dependent Variable: 发案率
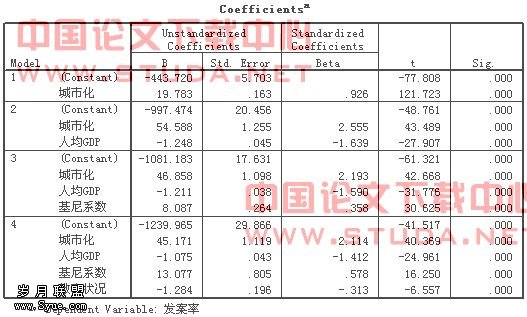
表5是对4个模型中各个系数检验的结果,用的是t检验。从结果可以看出,模型4中四个变量的系数都有统计学意义。城市化的偏回归系数为45.171,标准化回归系数为2.114;人均GDP偏回归系数为-1.075,标准化回归系数为-1.412;基尼系数的偏回归系数为13.077,标准化回归系数为0.578;教育状况的偏回归系数为-1.284,标准化回归系数为-0.313.通过比较这四个变量的标准化回归系数的绝对值,可以将这四个变量对发案率的贡献度进行排序,依次是城市化、人均GDP、基尼系数和教育状况。
表 SEQ 表 /* ARABIC 5 对4个模型中各个系数的检验结果
根据以上的检验,我们可以初步列出此数学模型:
![]()
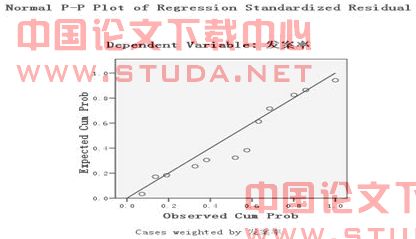
图2所示为残差的正态P-P图,可以由此观察残差分布是否正态。可见散点基本呈直线趋势,可以认为因变量服从正态分布。
图 SEQ 图 /* ARABIC 2 残差的正态p-p图
三、共线性检验及其处理——主成分分析
在多重回归分析中,无法避免的一个问题就是多重共线性问题。所谓多重共线性是指自变量之间存在近似的线性关系,即某个自变量能近似的用其他自变量的线性函数来表示。一般而言,自变量较低程度上的相关不会对回归结果造成严重影响,然而,当共线性趋势非常明显时,就会对模型的拟合带来严重影响。一般来说,如果两个自变量的相关系数超过0.9,对模型的影响就会很大。当然,仅靠相关系数仅仅是初步判断,实践中借助SPSS,常常使用方差膨胀因子、特征根或条件指数来判断。当膨胀因子大于10、特征根为0或条件指数大于30时,提示存在共线性。
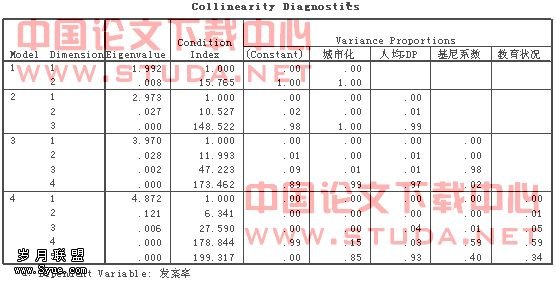
在SPSS中,共线性诊断仍然是通过多元线性回归分析来实现的。表6是SPSS线性诊断的结果,从中我们可以发现,特征根有两项为0,条件指数有两项分别为178.8、199.3,在常数项、城市化和人均GDP这三项中,VP值均很高,分别为0.99、0.85、0.93,提示三者高度相关。原回归模型存在严重的共线性,我们必须对其进行处理。
表 SEQ 表 /* ARABIC 6线性诊断的结果
共线性处理有多种方法,其中比较常用的是主成分回归。所谓主成分回归分析就是试图以较少的相互独立的指标来代替原来的多个指标,新指标包含了原指标的主要信息。上文给出的模型既然存在着共线性问题,下面就用主成分回归的方法来解决。
首先我们要确定原自变量的均数、标准差等信息,具体可见表7.
表 SEQ 表 /* ARABIC 7 原指标的描述信息
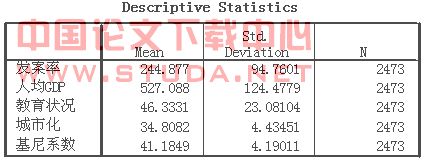
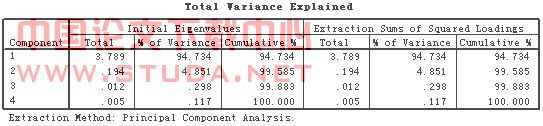
其次,我们借助SPSS因子分析程序,得到主成分的统计信息,具体可见表8。通过观察表8的数据,我们可以知道,第一主成分的特征根为3.786,它解释了总变异的94.734%;第二主成分的特征根为0.194,它解释了总变异的4.851%。前两个特征根的累积贡献率为99.585%。也就是说,前两个主成分包含了原有4个指标的99.585%的信息。因此,我们可以取前两个主成分来代替原有的4个指标变量。
表 SEQ 表 /* ARABIC 8 主成分的统计信息
再次,通过SPSS列出因子得分系数矩阵,具体可见表9,通过该矩阵可以将所有主成分表示为各个变量的线性组合。
表 SEQ 表 /* ARABIC 9 因子得分系数矩阵
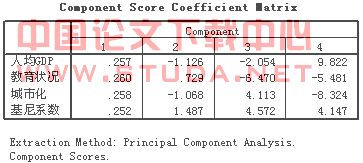
根据以上数据,可以写出两个主成分的表达式(方程1)
![]()
![]()
这里的 为标准指标变量。根据表7的信息,我们可以创建标准指标变量和原指标的关系(方程2):
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
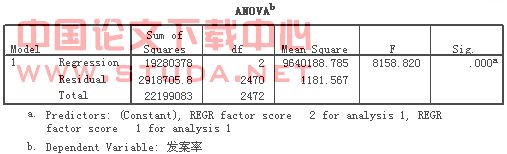
最后,对主成分进行回归分析,分析主成分回归结果。通过SPSS的运算,根据表10,我们可以判断,主成分回归分析模型拟合较好(![]() ,方差分析
,方差分析![]() );
);
表 SEQ 表 /* ARABIC 10 主成分回归分析模型结果

根据主成分分析的参数估计及其假设检验结果,我们可以判断其是否有统计学意义。具体见表11。
表 SEQ 表 /* ARABIC 11 主成分回归分析的参数估计及其假设检验结果
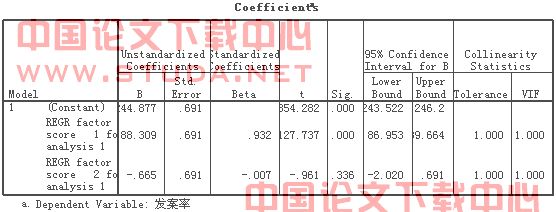
表11显示常数项、![]() 、
、![]() 均有统计学意义,即
均有统计学意义,即![]() 和
和![]() 对应变量都有作用。由此我们可以写出其线性回归方程(方程3):
对应变量都有作用。由此我们可以写出其线性回归方程(方程3):
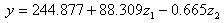
将公式![]() 、
、![]() (方程1)的表达式代入上述回归方程,得到应变量
(方程1)的表达式代入上述回归方程,得到应变量![]() 与标准自变量
与标准自变量![]() 的线性回归方程(方程4):
的线性回归方程(方程4):
![]() 244.877+23.4442
244.877+23.4442![]() +22.47556
+22.47556![]() +23.49394
+23.49394![]() +21.26501
+21.26501![]()
根据标准自变量和原自变量之间的关系,可以将标准自变量还原为原自变量。将方程2代入方程4,即得到应变量y与原自变量之间的线性回归方程:
![]()
![]()
![]()
[1] 杨家騄,《犯罪调查统计学》,第215-221页,中华书局,1969.
[2] 高树桥等,《犯罪调查及其统计方法》,第299-302页,群众出版社,1986.
[3] 朱景文,《报告》,导论部分,中国人民大学出版社,2007.
![广州青年律师群体政治态度的调查与分析[2]](/d/file/20100707/d463dc1e740ba1cc0117bccc391f1a3d.jpg)