基于Kmeans和CBR方法的高校就业预测模型应用研究
【摘要】提出运用Kmeans聚类算法和CBR案例推理方法对高校学生就业趋向进行预测。针对采集的高校就业信息的高维海量数据,首先使用Kmeans聚类方法将已就业数据划分成不同的就业类别,从而极大地减少了特征分析工作量。对未就业数据进行预测时,先跟每一聚类中心的距离值,从而得到其合适的分类,再在每一类中进行CBR推理,最后得出对其的预测分类结果。实验结果表明,提出的算法预测结果较为精确,为高校就业指导提供了帮助。
【关键词】Kmeans聚类 CBR推理 高校就业预测
随着高校的扩招,我国高等已经由精英教育转向大众教育,从1999年开始,高等学校的办学规模、招生规模逐步扩大。而由此带来了应届毕业生的就业形势一年比一年严峻,2010年,全国普通高等毕业生达630万,比2009年的611万又增加了19万人[1]。面对如此大的就业压力,各个高校也加强了就业指导方面的工作。不少高校开展了对学生的就业指导,如收集、筛选有效的需求信息,为毕业生提供指导与咨询等,以提高学校的就业率。但很多高校就业工作还只是做了面上工作,缺乏实际效果,并不能真正解决学生的实际问题。
目前,很多高校都在使用就业管理系统、学籍管理系统等数据库帮助工作,但这些数据库往往还停留在简单的统计、查询等功能上。由于毕业生就业工作涉及的数据量十分巨大,而且时间集中,仅靠传统的数学和统计手段已经不够。如何运用数据库中的数据得到对就业指导有用的信息成为了一个非常有实际意义的研究内容,而数据挖掘技术可在高校就业预测中有很好的应用前景。
本文首先用Kmeans[2]方法对往年已就业学生进行聚类,对每一类特征进行分析,得到其就业特征信息。对未就业学生进行预测时,先将其与每一类中心点计算距离,将其分入某一类,在同一类中再用CBR[3]进行案例推理,从而得出其与哪几个个案最相似,用这些成功就业的特征作为该学生的预测结果,而且还可以根据这些学生特征给新同学一个建议。本文结构如下,第1节介绍基于Kmeans和CBR的高校就业预测模型,第2节给出实验结果和分析,最后一节给出结论。
1 基于Kmeans和CBR的高校就业预测模型
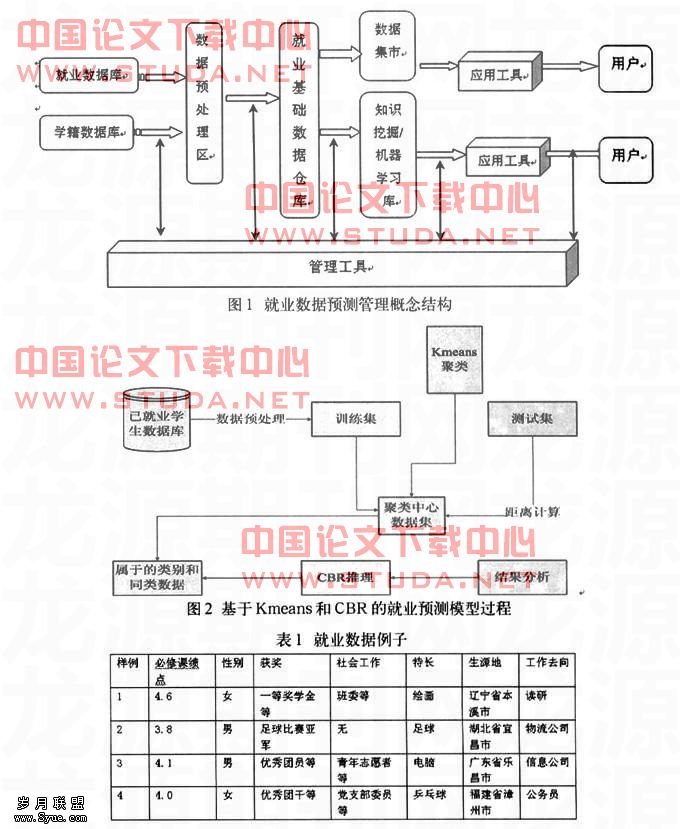
学生管理和就业数据数据量庞大,因此需要使用数据挖掘知识进行处理,使用数据挖掘对学生管理和就业数据进行管理的概念流程如图1所示。
在图1的数据挖掘和机器学习库中,可以使用多种算法,如决策树算法[4]、关联规则算法[5]、SVM(Support Vector Machine,支持向量机)[6]算法等等。本文重点是对就业数据进行预测,因此提出了使用Kmeans聚类算法和CBR算法,以得到较好的预测结果。
Kmeans(K均值)聚类算法是一种基于划分的聚类算法,建立在最小化误差平方和的准则上。其过程是先随机选择一些初始代表点作为初始聚类中心,然后计算其余样本点与各中心点的距离,把它们分到最近(距离最小)的类中去;然后对每一类中的样本点计算均值,把这个均值作为新的聚类中心点;反复迭代,直到聚类中心点不再改变或者达到迭代最大步数。Kmeans聚类算法的效率很高,时间复杂度为O(tkn),其中n是样本数,k是聚类的类数,t是算法迭代次数(t<
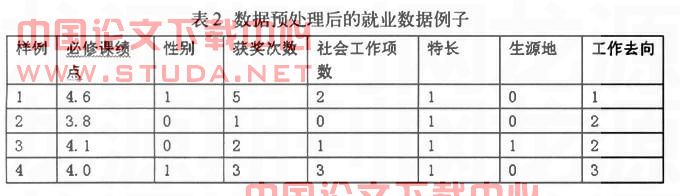
本文提出的基于Kmeans和CBR的高校就业预测模型的流程示意图如图2所示,首先用Kmeans方法对往年已就业学生进行聚类,对未就业学生进行预测时,先将其与每一类中心点计算距离,将其分入某一类,在同一类中再用CBR进行案例推理。
2 实验结果和分析
数据挑选自最近几年实际的就业信息,共320个样本,部分样本数据例子如表1:
2.1 数据预处理
首先要把数据进行预处理,不是数值型的数据转换成数值型数据。如性别男用0代表,女用1表示,获奖情况我们也将其数值化,考虑用获奖的次数来替换获奖这个属性,社会工作也是如此.对特长我们简单用有特长(数值1表示)、无特长(数值0表示)来区分。生源地则与工作单位所在地进行对比,如在同一省份则用数值1代替,否则用数值0代替。则上述就业数据例子变成
2.2 实验结果和分析
为了验证所提出方法的效果,我们使用Weka工具对预处理数据进行分析。
对320个数据进行聚类,得到第一步聚类结果如下:
kMeans
======
Number of iterations: 2
Within cluster sum of squared errors: 259.0277777777773
Cluster centroids:
Cluster 0
Mean/Mode: 3.950 1.50.51 0
Std Devs:0.1505 N/A0.5016 0.5016 0 N/A
Cluster 1
Mean/Mode: 4.31 4 2.51 0
Std Devs:0.3009 N/A1.0031 0.5016 0 N/A
Clustered Instances
0 160 ( 50%)
1 160 ( 50%)
即结果聚成了两大类,如对比表1中数据,我们发现样例1(读研)和样例4(公务员)被聚在一类中,而样例2(物流公司)和样例3(信息公司)的被聚在另一类,这一结果说明去公司的同学有相似地方,而读研和考公务员的同学有相近的成绩和爱好。进一步还可以对这两类结果进行细分分析。
如果把320个样例划分成训练集和测试集来验证我们算法的预测准确度,如预测工作省份与生源地是否相同省份,可得如下结果:
IB1 classifier
Correctly Classified Instances 109 100 %
Incorrectly Classified Instances 00 %
Kappa statistic 1
Mean absolute error 0
Root mean squared error 0
Relative absolute error 0 %
Root relative squared error 0 %
Total Number of Instances 109
TP RateFP RatePrecisionRecall F-MeasureClass
1 0 1 1 10
1 0 1 1 11
=== Confusion Matrix ===
a b<-- classified as
82 0 |a = 0
0 27 | b = 1
这个结果表明可以完全正确的预测出工作地点,从而可以给就业工作提供一些指导和帮助。
3 结论与展望
该文建立了基于Kmeans聚类算法和CBR推理的高校就业预测模型,阐述了使用数据挖掘对学生管理和就业数据进行管理的概念流程、基于Kmeans和CBR的就业预测模型过程、就业数据的收集以及数据数值化预处理等过程,最后将Kmeans方法和CBR方法应用到高校就业预测中。
经实验检验,证明了基于Kmeans和CBR方法的有效性和可靠性,同时将该方法应用在高校就业预测中,为高校就业指导提供一个定量的依据,为从事就业指导工作的教师提供重要。本文分析了高校学生的就业情况,将数据挖掘技术应用于就业数据,实现Kmeans和CBR 算法并得到聚类知识。通过对学生就业数据进行挖掘分析,找到学生就业信息与学生学习成绩、社会活动能力等属性之间的关联,有助于学校目标、教育方向、教育手段的定位与改进,有助于在校生明确加强学习与实践的方向, 为学生培养与就业指导提供决策依据,提高对毕业生就业指导的实效性,实现毕业生更快、更好地就业。
参考
[1] 袁贵仁.2010年全国普通高校毕业生就业工作视频会议.
[2] Kaufman L and Rousseeuw P J.Finding groups in data: an introduction to cluster analysis.New York:John & Sons,1990.
[3] Aamodt,A.and Plaza,E. Case-Based Reasoning: Foundational Issues, Methodological Variations,and System Approaches.AI Communications,7(i):pp 39-59,1994.
[4] J.R.Quinlan.Induction of Decision Trees,Machine Learning,1(1):pp81-106,1986.
[5] Rakesh Agrawal,Tomasz Imieliński,Arun Swami.Mining association rules between sets of items in large databases,ACM SIGMOD Record,22(2),pp.207-216,1993.
[6] V.Vapnik.Statistical Learning Theory.Wiley,N.Y.,1998.