基于数据分组方法的数据仓库并行预计算和查询(四)
第七章 实验
在本章中通过实验说明算法的有效性和可扩展性。实验的平台是一台有三个节点的刀片服务器,每个节点上的处理器主频为1.8GHz,内存容量为1GB,操作系统是Linux,内核版本2.6.9,节点间采用千兆连接。MPI运行环境为MPICH2.0,C++编译器g++版本为3.4.3,MPI环境下C++编译器MPICXX的版本为1.0.3。
7.1 数据描述
在实验中,使用了一个来自不同气象站所收集的1985年9月的天气数据[Hahn94]。它包含了1,015,367个元组,一共20维。在这次实验中,所使用的是它前16维的数据,每个维度的依次如下表所示:
维度 | 维度名称 | 维度的势 |
1 | 时间 | 240 |
2 | 天空明亮度 | 2 |
3 | 纬度 | 3809 |
4 | 经度 | 5359 |
5 | 气象站编号 | 7037 |
6 | 气象站所处地点 | 1 |
7 | 当前天气情况 | 101 |
8 | 云层覆盖总量 | 9 |
9 | 低层云数量 | 10 |
10 | 低层云高度 | 11 |
11 | 低层云类型 | 13 |
12 | 中层云类型 | 14 |
13 | 高层云类型 | 11 |
14 | 中层云数量×100 | 24 |
15 | 高层云数量×100 | 24 |
16 | 中层云数量 | 10 |
表7.1 天气数据集
7.2 预计算实验
在本实验中,将讨论基于数据分组方法的并行预计算程序对于串行预计算程序在性能上的提高,以及这两种方法在不同规模数据集上进行运算的性能表现。讨论并行查询程序的加速比。
在预计算实验中,在单节点环境下和三节点环境下分别对13个不同的数据进行了串行和并行预计算。这13个不同的数据的维度各不相同,从4维到16维,分别是天气数据集20维数据中的前4维到前16维等,元组条数都是1,015,367条。三节点环境下的数据分割采用平均分割,每个节点上收到的元组条数基本上是相等的。
在单节点环境下的实验使用串行的预计算程序。统计两个时间:(1)程序进行预计算写入文件的时间。(2)程序运行时间。
在三节点环境下的实验使用并行的预计算程序。因为从机不需要等待主机完全读入数据文件便可得到一部分数据进行预计算,使得从机预计算时间和主机读取文件有交叉。因此在此实验中,每台机器都会统计三个时间:(1)主机从开始读取数据文件到数据完全载入内存并发送出去的时间。(2)每台机器进行预计算的时间。(3)每台机器总的运行时间。
通过实验发现,刀片服务器的网络效率非常高,在实验中,几乎所有的MPI点对点通信时间都可以在0.2秒之内完成,加上实验中的MPI通信次数比较少,所以MPI通信的时间可以忽略不计。
7.2.1 预计算实验结果分析
图7.1所示是分别在两种环境下的预计算时间,也就是程序生成立方体的计算时间。并行环境下的预计算时间是取三个节点预计算时间的平均值。如图中所示,基于数据分组的并行预计算方法能够有效地缩短预计算的时间。在数据维度少于或等于9维时,预计算的时间增长显得比较缓慢,在这个维度区间内,预计算程序的性能始终保持着较高水平。但随着数据维度的增多,预计算性能开始出现衰减。从11维数据开始,每增加一维数据,串行预计算时间便会增加约33%,而并行的预计算时间增长率为29%左右。
图7.2所示是串行预计算时间和并行平均预计算时间的比值。在4到10维之间时,串行预计算时间一直维持在并行计算时间的2.9倍左右。但在11维或更多维数据时,串行预计算时间的增长率开始大幅超过并行预计算时间,使得并行计算的加速比在11维时达到了理想状态的3倍,并且呈线性增长的趋势。可见,随着数据量的增大,DFS算法性能会相应地下降,而减少元组条数可以继续使得DFS算法保持高性能。

图7.1 预计算时间
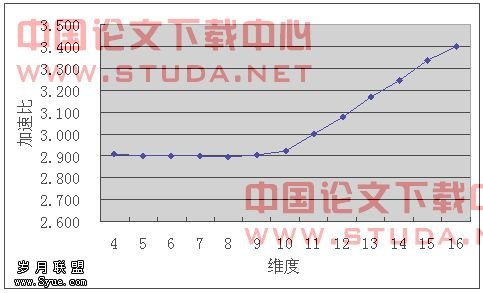
图7.2 预计算加速比
图7.3、7.4和7.5分别是预计算程序读入数据文件时间、程序总运行时间和总运行时间的加速比。并行环境下程序总运行时间是指程序开始运行直到最后一个进程完成计算退出为止。并行程序中数据读入与数据发送是结合在一起的,数据读入一部分之后即可将该部分数据发送给相应的进程进行计算,但读入数据文件这一部分不能达到完全的并行化,所以程序总运行时间的加速比性能并没有已经完全并行化的预计算加速比那么可观。但随着维度的增多,预计算时间的增长,数据读入时间所占的总运行时间比例也相应地减少。在高维度的预计算中,并行的预计算程序最终还是可以达到3倍这个理想性能加速比。
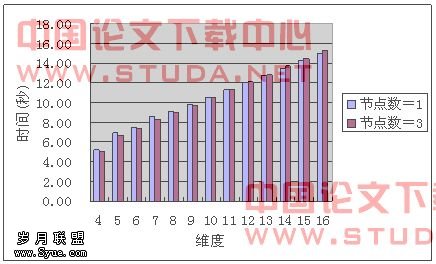
图7.3 数据读入时间
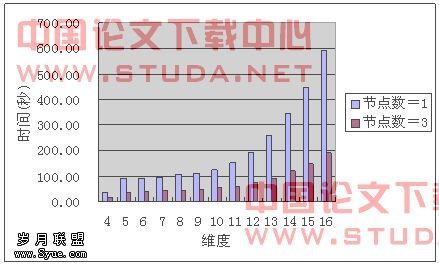
图7.4 总运行时间
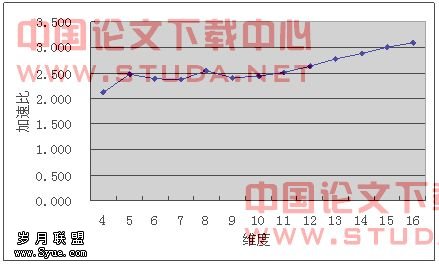
图7.5 总运行时间加速比
7.3 查询实验
本实验的主要内容是在预计算生成的商立方体基础上,对4至13维的商立方体进行单节点串行和三节点并行点查询实验。讨论并行查询程序相对于单机查询程序在性能上的提高,计算并行查询程序的加速比。
首先各个维度都随机地生成了1000条点查询。生成的点查询是从基表中随机抽取出1000条元组,并随机地将元组中的某些属性改为“*”。经观察,串行查询程序与并行查询程序所得到的查询结果是一致的,在本实验中,主要讨论并行查询程序对于串行程序的加速比,因此,查询的具体结果便不再讨论。串行查询与并行查询的程序运行时间如图7.6所示。
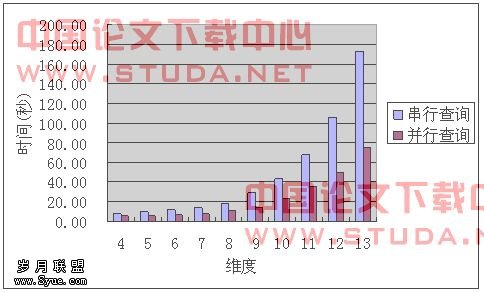
图7.6 查询程序运行时间
7.3.1 查询实验结果分析
尽管在并行查询中,每台机器所查询的立方体单元数目基本上只相当于串行查询中立方体单元数目的三分之一,如图7.7所示,但通过实验发现,并行查询程序的性能加速比并未能够达到理想的加速比,如图7.8,只能达到2倍左右的性能加速。对其原因进行分析,发现这是由于查询语句未能直接命中,会造成额外开销的问题(本文4.3节中提到)所造成的。
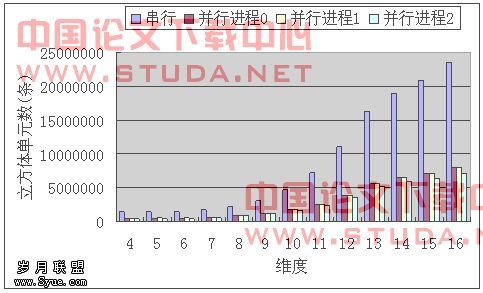
图7.7 商立方体单元数

图7.8 程序加速比
在基于数据分组方法的预计算中,经过预计算的商立方体数据是分布式地存放各台机器上的。对于一条查询语句q,当程序用q在A机器的商立方体中进行查询时,q的覆盖集里面的所有元组在预计算时可能都没有分配到A机器上。在这种情况下,q在A上的查询便会产生巨大的额外开销:首先会从q所在层次h1里的单元中开始查找,在h1找不到的情况下,会继续查找h1的下一层h2。但是由于q在A上是无法命中的,查询程序会一层接着一层地往下扫描下去,直到扫描完最后一层。
随机生成的1000条点查询语句是根据基表中的元组生成的,这样在串行查询中,较少会出现语句在某一层未能命中,需要扫描下一层的情况。然而在并行查询中,由于元组的分布性,产生了较多的查询不命中,使得程序必须进行额外的层次扫描,而且这种额外的层次扫描的代价十分巨大。在并行查询中,开销巨大额外的层次扫描使得查询的时间急剧地增加,从而使得程序性能没能达到预期的效果。
尽管如此,在三台机器上能够实现缩短一半的时间,并行查询程序的性能还是令人满意的。
7.4 小结
由于硬件平台条件的限制,实验最多只能在三个节点上运行,无法进行更多的实验来验证本文提出的基于数据分组的并行预计算和并行查询方法的可扩展性。
第八章 与展望
在数据仓库数据量急剧增长的今天,并行数据仓库技术成为了解决海量数据预计算和存储问题的一种重要的、有效的手段。本文主要研究了一种基于数据分组的并行数据仓库预计算和查询技术,并在串行程序基础上实现了并行预计算和查询的程序。然后通过实验数据来说明该方法的有效性和分析了这种方法的优点和存在的缺陷。
8.1 结论
由于实验平台的限制,使得各项实验最多只能在三个节点的环境下运行,无法在更多节点的计算环境下进行实验,研究本文提出方法的可扩展性。通过实验的观察和分析,本文提出的基于数据分组的数据仓库并行预计算和并行查询方法有以下一些优点:
(1) 该实现方法的并行策略简单,该方法可以经过很少的修改,便可以将很多已经实现的串行程序改为并行程序。使用MPI和C++进行编程,使得程序具有良好的可移植性、面向对象性。
(2) 可以更好地适用于大数据量场合。对于串行版本的预计算程序,在对于高维度数据集进行预计算时,随着数据量的增加,性能衰减得很厉害。并行预计算时的性能加速比十分可观,在数据量很大的情况下,甚至可以超过理想加速比。
(3) 预计算后生成的商立方体数据以分布式方式存储,在查询时,各台机器都可以同时对立方体数据进行读取,充分利用了各台机器的磁盘I/O带宽。
同时本文提出的并行预计算和并行查询方法存在的一些不足:
(1) 对于并行查询,查询的效率未能达到理想的加速比。这是由于数据元组的分布性与商立方体的特性所造成的,当查询语句覆盖集中的元组没被分配到某台机器上时,该查询语句在该台机器上的查询操作便无法命中。商立方体的特性使得查询在某一层上界中找不到所覆盖的上界的时候,必须到下一层进行查找,如果一直找不到,便会一直找下去,直到全部都扫描过。查询语句在某台机器上无法命中的后果是会产生很多额外的层次文件扫描操作,这样一层层的扫描操作代价是十分巨大的,但这种情况在数据元组分布式存储的情况下又是无法避免的,这样便使得并行查询程序的加速比未能达到理想状态。
(2) 基表元组的映射可以提高预计算和查询的响应效率,但是对于映射这个步骤还不能完全地并行化处理。
8.2 未来的改进
对于本文提出的并行预计算和并行查询方法存在的一些不足和缺点,可以存在这样一些补充和改进的地方:
(1) 预计算算法还需要做出一些修改以适应立方体分布式存储环境,如聚集操作中的平均操作,除了对该维度量值做平均值计算之外,还应该同时加上计算总和的计算。这样才能保证元组条数的信息不至于丢失,在主进程最终做统计运算的时候才能得到正确的结果。
(2) 对于基于顺序查询方法的并行查询,可以预先判断一下是否在该机上命中查询。如果可以预先判断出查询不命中,则可以减少许多额外的层次扫描开销,提高效率。预先的判断应该可以通过扫描本地预计算输入基表里有没有查询语句覆盖集内的元组进行。
(3) 改进查询程序的算法。顺序查询是最简单、易行的查询方法,但这种方法的效率确实不高。
(4) 改进立方体数据结构,商立方体存在着查询效率不高的问题,对此人们提出了各种基于商立方体的改善型立方体数据结构,如QC-Tree[LPZ03]和Semi-Closed Cube[LW05],基于此类型的立方体结构应该能够改善查询的响应速度。
[Beo07] Beowulf.org: The Beowulf Cluster Site
[CCS93a] E. Codd, S. Codd, C. Salley. Beyond decision support. Computer World, 27(30): 87-89, 1993
[CCS93b] E. Codd, S. Codd, C. Salley. Providing OLAP to User-Analysts. PC World, (9), 1993
[Chen99] 陈国良. 《并行计算——结构·算法·编程》. 北京, 高等出版社, 1999
[Du01] 都志辉. 《高性能计算并行编程技术——MPI并行程序设计》. 北京, 清华大学出版社, 2001
[Fly72] M. Flynn. Some Computer Organizations and Their Effectiveness. IEEE Transactions on Computers, C21(9), 1972
[GCB+97] J. Gray, S. Chaudhuri, A. Bosworth, A. Layman, D. Reichart, M. Venkatrao, F. Pellow and H. Pirahesh. Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals. Journal of Data Mining and Knowledge Discovery, 1(1): 29-53, 1997
[GGKK03] A. Grama, A. Gupta, G. Karypis, V. Kumar. Introduction to Parallel Computing (Second Edition). Pearson Education, 2003. 张武, 毛国勇, 程海英 等译. 《并行计算导论》. 北京, 机械出版社, 2005
[Hahn94] C. Hahn et. al. Edited synoptic cloud reports from ships and land stations over the globe, 1982-1991. cdiac.est.ornl.gov/ftp/ndp026b/SEP85L.Z, 1994.
[HPF06] High Performance Fortran Forum
[Inm02] W. H. Inmon. Building the Data Warehouse (Third Edition), John Wiley & Sons, Inc. 2002. 王志海, 林友芳等译. 《数据仓库》. 北京, 机械工业出版社, 2003
[LAM07] LAM-MPI Parallel Computing
[LPH02] L. Lakshmanan, J. Pei and J.Han. Quotient Cube: How to Summarize the Semantics of a Data Cube. In VLDB’02
[LPZ03] L. Lakshmanan, J. Pei and Y. Zhao. QC-Trees: An Efficient Summary Structure for Semantic OLAP. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, ACM, 2003
[LW05] S. Li and S. Wang. Semi-Closed Cube: An Effective Approach to Trading Off Data Cube Size and Query Response Time. Journal of Computer Science and Technology, Vol.20, No.3, pp.367-372, 2005
[MPI03a] MPI: A Message-Passing Interface Standard.
[MPI03b] MPI-2: Extensions to the Message-Passing Interface.
[MPI07] MPICH2 home page
[OMP07] OpenMP: Simple, Portable, Scalable SMP Programming
[PTP06] POSIX Thread Programming
[PVM07] Parallel Virtual Machine Web Site
[SRD02] Y. Sismanis, N. Roussopoulos, A. Deligiannakis and Y. Kotidis. Dwarf: Shrinking the Petacube. In Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data, ACM, 2002
[ST98] D. Skillicorn and D. Talia. Models and Languages for Parallel Computation. ACM Computing Surveys, 30(2): 123-169, 1998
[WLFY02] W. Wang, H. Lu, J. Feng and J. Yu. Condensed Cube: An Effective Approach to Reducing Data Cube Size. In Proceedings of the 18th International Conference on Data Engineering, IEEE Computer Society, 2002.
[ZCML06] 张林波, 迟学斌, 莫则尧, 李若. 《并行计算导论》. 北京, 清华大学出版社, 2006
附 录
| 时间(秒) | |
维度 | , , 串行 | 并行 |
4 | 5.18 | 4.98 |
5 | 6.94 | 6.68 |
6 | 7.50 | 7.36 |
7 | 8.55 | 8.28 |
8 | 9.08 | 8.98 |
9 | 9.83 | 9.76 |
10 | 10.58 | 10.54 |
11 | 11.29 | 11.32 |
12 | 12.02 | 12.08 |
13 | 12.75 | 12.78 |
14 | 13.47 | 13.70 |
15 | 14.26 | 14.49 |
16 | 14.96 | 15.31 |
表1 数据文件读取时间
时间(秒) | |||||
维度 | 串行 | 并行进程0 | 并行进程1 | 并行进程2 | 并行平均 |
4 | 28.92 | 9.95 | 10.29 | 9.58 | 9.94 |
5 | 84.40 | 29.04 | 30.09 | 28.24 | 29.12 |
6 | 84.70 | 29.13 | 30.10 | 28.42 | 29.22 |
7 | 87.78 | 30.23 | 31.23 | 29.40 | 30.29 |
8 | 92.41 | 31.81 | 32.91 | 31.07 | 31.93 |
9 | 100.98 | 34.69 | 35.74 | 33.84 | 34.76 |
10 | 114.48 | 39.24 | 40.19 | 38.11 | 39.18 |
11 | 139.92 | 45.93 | 49.33 | 44.88 | 46.67 |
12 | 180.65 | 57.77 | 61.94 | 56.26 | 58.73 |
13 | 244.26 | 78.17 | 78.25 | 74.78 | 77.07 |
14 | 332.70 | 104.71 | 103.72 | 98.87 | 102.43 |
15 | 431.87 | 132.03 | 130.22 | 126.22 | 129.49 |
16 | 576.41 | 173.32 | 170.31 | 164.59 | 169.41 |
表2 预计算时间
时间(秒) | |||||
维度 | 串行 | 并行进程0 | 并行进程1 | 并行进程2 | 并行完成 |
4 | 34.10 | 16.10 | 14.74 | 15.72 | 16.10 |
5 | 91.34 | 36.84 | 35.58 | 36.02 | 36.84 |
6 | 92.20 | 38.58 | 37.05 | 37.86 | 38.58 |
7 | 96.33 | 40.69 | 38.86 | 39.86 | 40.69 |
8 | 107.49 | 42.15 | 40.2 | 41.41 | 42.15 |
9 | 110.81 | 46.01 | 43.74 | 45.15 | 46.01 |
10 | 125.06 | 51.26 | 48.65 | 50.13 | 51.26 |
11 | 151.21 | 60.09 | 56.86 | 58.37 | 60.09 |
12 | 192.67 | 73.34 | 69.57 | 70.45 | 73.34 |
13 | 257.01 | 92.72 | 88.46 | 89.32 | 92.72 |
14 | 346.17 | 120.28 | 114.66 | 114.43 | 120.28 |
15 | 446.13 | 148.56 | 141.81 | 142.74 | 148.56 |
16 | 591.37 | 190.8 | 182.58 | 182.07 | 190.80 |
表3 预计算程序运行时间
单元数(条) | |||||
维度 | 串行 | 并行进程0 | 并行进程1 | 并行进程2 | 并行总和 |
4 | 1476016 | 508194 | 513514 | 503833 | 1525541 |
5 | 1480006 | 509514 | 514914 | 505273 | 1529701 |
6 | 1480006 | 509514 | 514914 | 505273 | 1529701 |
7 | 1702776 | 610851 | 618488 | 596856 | 1826195 |
8 | 2211668 | 847229 | 861503 | 817868 | 2526600 |
9 | 3147573 | 1190299 | 1208486 | 1136715 | 3535500 |
10 | 4747893 | 1738919 | 1756447 | 1634975 | 5130341 |
11 | 7140853 | 2532913 | 2551943 | 2321907 | 7406763 |
12 | 11034333 | 3818969 | 3832601 | 3458299 | 11109869 |
13 | 16386342 | 5595663 | 5598401 | 5077096 | 16271160 |
14 | 18964307 | 6469585 | 6464190 | 5824463 | 18758238 |
15 | 20850282 | 7091770 | 7071021 | 6369647 | 20532438 |
16 | 23480070 | 7979451 | 7945029 | 7131160 | 23055640 |
表4 预计算生成的单元数
时间(秒) | |||||
维度 | 串行 | 并行进程0 | 并行进程1 | 并行进程2 | 并行完成 |
4 | 8.13 | 5.67 | 5.67 | 5.28 | 5.73 |
5 | 10.44 | 6.03 | 6.30 | 5.62 | 6.30 |
6 | 12.22 | 6.95 | 7.18 | 7.30 | 7.30 |
7 | 13.96 | 8.47 | 8.20 | 8.53 | 8.56 |
8 | 18.16 | 11.18 | 10.94 | 9.67 | 11.26 |
9 | 28.79 | 14.34 | 14.03 | 13.84 | 14.38 |
10 | 42.97 | 23.50 | 22.44 | 19.30 | 23.54 |
11 | 67.36 | 35.46 | 33.46 | 31.67 | 35.58 |
12 | 106.22 | 49.84 | 48.09 | 47.26 | 49.94 |
13 | 173.07 | 74.75 | 73.73 | 74.32 | 74.83 |
表5 查询时间