基于PCANN的说话人识别方法研究
来源:岁月联盟
时间:2010-08-30
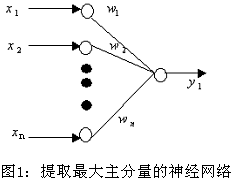
 2.2 基于Hebb 学习的主分量分析网络
2.2 基于Hebb 学习的主分量分析网络 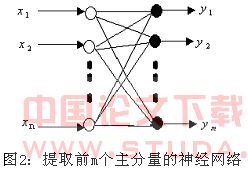



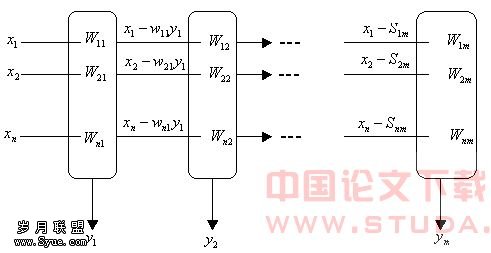 图3:提取前m个主分量的神经网络解析图3 识别系统特征参数以及模型3.1 语音的主分量特征参数(PCA特征)本文选用线性预测倒谱系数(LPCC)作为语音的原始特征参数然后对其进行主分量分析。LPCC系数是一种非常重要的特征参数。它的主要优点是比较彻底地去掉了语音产生过程中的激励信息,主要反映声道相应,而且往往只要十几个倒谱系数就能较好地描述语音信号的共振峰特性,因此在识别中取得了较好的效果。在实际中,LPCC参数不是由信号直接得到的,而是由LPC系数得到的。关系式如下:
图3:提取前m个主分量的神经网络解析图3 识别系统特征参数以及模型3.1 语音的主分量特征参数(PCA特征)本文选用线性预测倒谱系数(LPCC)作为语音的原始特征参数然后对其进行主分量分析。LPCC系数是一种非常重要的特征参数。它的主要优点是比较彻底地去掉了语音产生过程中的激励信息,主要反映声道相应,而且往往只要十几个倒谱系数就能较好地描述语音信号的共振峰特性,因此在识别中取得了较好的效果。在实际中,LPCC参数不是由信号直接得到的,而是由LPC系数得到的。关系式如下: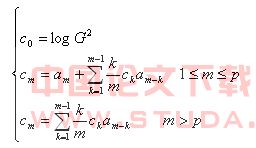 (8)这里 实际上是直流分量,反映频谱能量,其值的大小不影响谱形,在识别中通常不用,也不去计算。当LPCC系数个数不大于LPC系数个数时用第二式,当LPCC系数个数大于LPC系数个数时,用第三式进行计算。
(8)这里 实际上是直流分量,反映频谱能量,其值的大小不影响谱形,在识别中通常不用,也不去计算。当LPCC系数个数不大于LPC系数个数时用第二式,当LPCC系数个数大于LPC系数个数时,用第三式进行计算。
 4 实验及结果分析本文实现了一个在噪声环境下与文本无关的说话人自动识别系统。使用的是一个含20人的语音数据库,包括10名男性和10名女性,每人语音长度约90秒。采样率为12kHz,采用16bit量化。首先对数据进行预处理,包括端点检测、预加重(H(z)=1-0.95 )和加窗(Hamming窗,帧长20ms,帧移10ms)。原始特征选为12阶的LPCC倒谱参数,主分量特征个数选12阶。高斯模型混合数M=16。训练音长为40s,测试音为3s。实验结果如表(1):表1 实验结果(%)
4 实验及结果分析本文实现了一个在噪声环境下与文本无关的说话人自动识别系统。使用的是一个含20人的语音数据库,包括10名男性和10名女性,每人语音长度约90秒。采样率为12kHz,采用16bit量化。首先对数据进行预处理,包括端点检测、预加重(H(z)=1-0.95 )和加窗(Hamming窗,帧长20ms,帧移10ms)。原始特征选为12阶的LPCC倒谱参数,主分量特征个数选12阶。高斯模型混合数M=16。训练音长为40s,测试音为3s。实验结果如表(1):表1 实验结果(%)| 信噪比方法 | 0dB | 10dB | 20dB | dB |
| GMM | 32.1 | 60.8 | 80.5 | 98.4 |
| PCANN_GMM 2帧 | 44.7 | 78.3 | 90.4 | 91.5 |
| PCANN_GMM 3帧 | 45.9 | 79.6 | 89.9 | 93.2 |
| PCANN_GMM 5帧 | 46.6 | 77.1 | 89.2 | 95.4 |
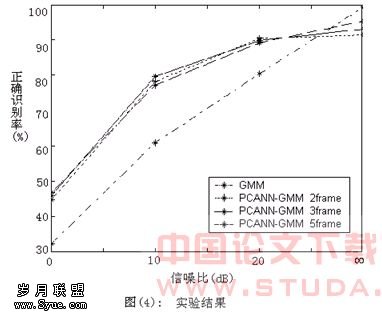 图(4)是根据表(1)中的数据画出的曲线。从表(1)可以看出,与传统的GMM方法相比,PCANN_GMM方法明显增强系统抗噪声能力,改进了识别效果。并且在PCANN_GMM中,帧数不同对识别也有较小的影响,当帧数大于5帧时,系统的识别性能不再提高。5 本文运用PCANN/GMM方法进行说话人识别,将多帧特征参数合并为一帧,利用了帧间相关性,对其进行主分量分析,减少了冗余度,提高了系统的鲁棒性。另外,当前的说话人识别研究还主要集中在声学特征层次进行,基于人们说话中含有的高级特征所进行的研究虽然很多,下一步的工作将结合声学特征和高级特征,研究它们之间的关系,从而进一步提高说话人识别系统的性能。 [1] 赵力. 语音信号处理 北京:机械出版社,2003 [2] E.Oja. “A Simplified Neural Model as a Principal Components Analyzer”,Journal of Mathematic Biology,VOL.19,pp.267-273,1982[3] Sanger T D. “Optimal Unsupervised Learing In a Singer Layer Linear Feedforward Neural Network”,Neural Networks, pp459-473, 1989[4] 何振亚 顾明亮 语音信号的主分量特征 应用学报, VOL 17,NO.4,1999[5] Simon Haykin. 神经原理. 北京:机械工业出版社, 2004[6] Chanchal Chatterjee. and Vwani P.Roychowdhury. “On Relative Convergence Properties of Principal Component Analysis Algorithms”,IEEE Transactions On Neural Networks, VOL.9,NO.2,March 1998[7] Oh-Wook Kwon. and Kwokleung Chan. “Speech Feather Analysis Using Variational Bayesian PCA”,IEEE Signal Processing Letters,VOL.10,NO.5,May 2003
图(4)是根据表(1)中的数据画出的曲线。从表(1)可以看出,与传统的GMM方法相比,PCANN_GMM方法明显增强系统抗噪声能力,改进了识别效果。并且在PCANN_GMM中,帧数不同对识别也有较小的影响,当帧数大于5帧时,系统的识别性能不再提高。5 本文运用PCANN/GMM方法进行说话人识别,将多帧特征参数合并为一帧,利用了帧间相关性,对其进行主分量分析,减少了冗余度,提高了系统的鲁棒性。另外,当前的说话人识别研究还主要集中在声学特征层次进行,基于人们说话中含有的高级特征所进行的研究虽然很多,下一步的工作将结合声学特征和高级特征,研究它们之间的关系,从而进一步提高说话人识别系统的性能。 [1] 赵力. 语音信号处理 北京:机械出版社,2003 [2] E.Oja. “A Simplified Neural Model as a Principal Components Analyzer”,Journal of Mathematic Biology,VOL.19,pp.267-273,1982[3] Sanger T D. “Optimal Unsupervised Learing In a Singer Layer Linear Feedforward Neural Network”,Neural Networks, pp459-473, 1989[4] 何振亚 顾明亮 语音信号的主分量特征 应用学报, VOL 17,NO.4,1999[5] Simon Haykin. 神经原理. 北京:机械工业出版社, 2004[6] Chanchal Chatterjee. and Vwani P.Roychowdhury. “On Relative Convergence Properties of Principal Component Analysis Algorithms”,IEEE Transactions On Neural Networks, VOL.9,NO.2,March 1998[7] Oh-Wook Kwon. and Kwokleung Chan. “Speech Feather Analysis Using Variational Bayesian PCA”,IEEE Signal Processing Letters,VOL.10,NO.5,May 2003
下一篇:Web挖掘个性化模型研究