linux文件系统实现浅析
之前有两篇文章整理过linux虚拟文件系统的结构,和linux文件读写的流程。其中一些由具体文件系统类型来实现的地方并没有深入叙述,只是说这是由具体的文件系统来实现的。比如,读写文件的时候,文件的读写位置怎么对应到实际的磁盘块呢?这是由具体的文件系统来实现的;再比如,寻找一个文件路径的时候,怎么知道XXX目录下是否有YYY文件存在呢?这也是由具体的文件系统来实现的。
前些天同事问起linux下inode的含义,我也就此整理一下自己的思路,看看具体的文件系统大致需要实现什么样的功能,并且可以怎样去实现。
inode
先从inode说起。文件系统中的文件形成了一个树型结构,其中的每一个结点就是一个文件(目录也是文件),对应一个inode。inode的具体结构因文件系统类型的不同而异,但是大体上应该包含如下信息:文件所有者(包括uid、gid)、权限位、文件大小、时间(创建时间、修改时间等)、文件内容。其中最值得一说的是文件内容。
文件有目录和普通文件之分,这两者的内容有着不同的含义,其内容的组织也可能有着不同的结构。
对于普通文件来说,其内容就是用户能够看到的文件内容。当用户程序通过系统调用读写文件时,需要通过某种索引结构来知道文件中某个offset的数据应该在哪个磁盘块上,然后转换成对该块的读写请求。当文件的内容很小时,文件内容的索引信息可以完全存放在inode结点中;如果文件很大,索引也会很大,inode结点可能装不下,就需要分配新的块来存放这些索引信息。而文件的内容则多半是放在inode结点之外的,依靠inode里面的索引信息来找到它们。
比如ext2文件系统中,文件内容的索引结构如下(摘自《ULK3》):
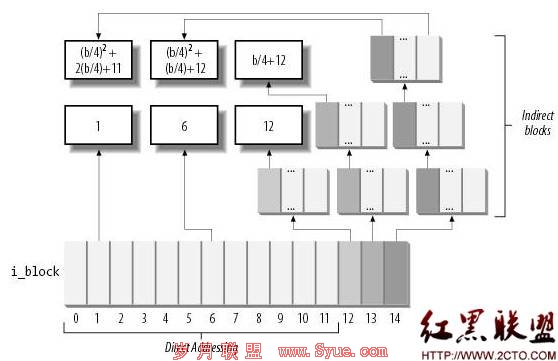
文件内容小于12个块的部分,其块号直接存放在inode中的i_block结构中;从第13块开始,使用一级间接索引,之后随偏移的增大又扩展到二级、三级间接索引。
对于目录,其内容一般是结构化的信息,描述了该目录下的文件的情况(主要包括每个文件的名字、inode号、等)。这是需要由具体的文件系统来解释的,用户看到这些原始内容是没有意义的。只有由具体文件系统将其解释为文件列表后,对用户才有意义。当用户程序寻找一个文件路径时,通过当前目录的inode,就能遍历到目录中的每一个结点(文件名+inode号)。匹配了下一级文件的名字以后,就能得到其对应的inode号,从而找到下一级文件的inode。这些下一级文件的信息也是因为其信息大小的不同,而直接存放在inode结点中,或另外的块中。
比如ext2文件系统中,目录信息结构如下(摘自《ULK3》):
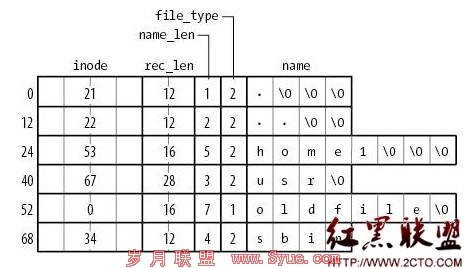
对于每一个下一级文件,记录了它的inode号、文件名、以及文件类型。
符号链接是一种特殊的文件。作为对另一个文件的代指,符号链接文件的内容就是它所代指的文件的路径。这个文件路径信息保存在inode或被inode引用的块中。具体的文件系统类型会实现其特定的读符号链接的方法。用户也可以通过readlink系统调用读到符号链接指向的文件路径。
在打开一个符号链接时,它代指的文件路径(也就是符号链接文件的内容)一般并不被用户程序所关心。内核会对此做一层包装,让用户程序自动访问到它所代指的文件的路径上去。
说了符号链接,也顺便提一下硬链接。硬链接并不会生成新的inode,而是同一个inode被包含在多个目录结点中,从而存在多个文件路径可以找到该文件。
super_block
前面描述了通过一个目录结点找到下一级文件的问题,那么文件系统中的第一个目录结点(也就是根目录)从哪里来呢?
每一个文件系统的实例中都有一个super_block(超级块),这就是该文件系统实例的源头。super_block里面主要有如下信息:根目录inode结点的结点号、inode号与块的对应信息、块的分配信息(总共有多少块、哪些已使用、等等)。
利用inode号与块的对应信息,就能知道一个结点号所对应的inode保存在什么地方。(这种对应信息也可以是某种约定,比如号码为N的inode,存放在M*N块上。)
通过super_block中的根目录inode号,在文件系统被挂载时就能得到其根目录结点。(根目录inode号也可以是具体文件系统约定的,比如约定1号inode就是根目录。)
此外,一个文件被创建之后,其大小是随时可能改变的。利用super_block中记录的块的分配信息,就能在文件增大时为其分配新的块、在文件减小只回收已经不需要使用的块。(这些信息并不是直接存放在super_block中,但是可以通过super_block找到它们,或者作为某种约定。比如约定super_block之后的块是某种结构化信息,块的分配信息就保存于其中。)
那么,这个super_block又从哪里来呢?这一般就只能是约定的了(比如约定第0个块就是super_block)。
我们知道,在使用一个磁盘之前,需要将它格式化一下,格式化成某种具体文件系统所支持的格式。这就包括在磁盘上生成super_block、根目录inode、以及一些必要的文件。并且按照该文件系统的约定,正确摆放它们的位置。
最后,以上提到的块号,实际上都是虚拟的块号。当一块磁盘被划分成若干分区时,每个分区都被当作一个设备,都拥有各自独立的块号。所以,如果super_block固定存放在0号块上,那么同一磁盘的分区0和分区1都有自己的0号块(它们分别对应到实际磁盘的两个不同的块上),从而都有自己的super_block。
块的缓存
在《linux文件读写浅析》中提到,存在一个磁盘高速缓存层,把文件的内容缓存在内存中。那么,文件内容以外的信息(比如inode)存在类似的缓存吗?
在linux上,设备也被当作是文件。读一个磁盘设备文件,能够读出磁盘上的原始数据。这些原始数据是什么呢?里面有super_block、inode、文件内容、还有一些脏数据(它们一般被文件系统理解为空闲空间)。同样,磁盘设备文件也像普通文件一样,拥有与之对应的磁盘高速缓存。当内核需要读磁盘上的某某块时(比如想读出存储在某块上的inode),实际上也是先在这个磁盘高速缓存上去寻找对应的内容,如果找不到再发起磁盘请求,并在读取到数据后更新磁盘高速缓存。
然而,类似inode的块读写与文件内容的读写还是不大一样。文件内容是连续的,具体文件系统在将文件内容存储在磁盘上时,也会尽量分配连续的块。这样,一次磁盘DMA,就可以读取若干个块,有益于效率。但像inode这样的东西却是孤立的,如果N号块是一个inode,N+1号块则很可能与之毫不相干。对一个inode的读写基本上是针对一个块的,不需要拥有像文件内容缓存那样的预读特性。
这两种缓存有着不同的名字,文件内容的缓存叫cache,inode之类的块缓存叫buffer(在linux下查看内存使用情况时,一般会分别看到buffer和cache的大小)。
在磁盘高速缓存中,缓存的单位是页(因为缓存是内存)。而一个内存页的大小往往是块大小的若干倍(常见值是:page为4K、block为1K),所以需要在磁盘高速缓存的内存页上再做一些细分,才能精确到块。在作为磁盘高速缓存页面的page结构上,附加buffer_head信息,如图(摘自《ULK3》):
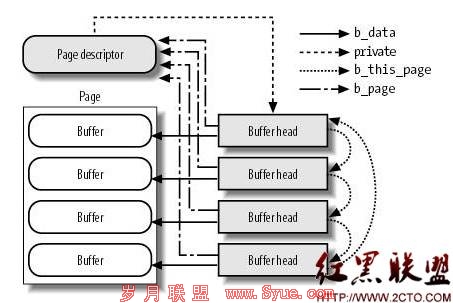
然后,在向通用块层发起磁盘读写请求时(参见《linux文件读写浅析》),bio的构造将是基于buffer_head的(而对于文件内容的读写,bio基于page来构造)。