Python 新浪微博 各种表情使用频率
主题:用新浪微博API积累了微博广场的1.4万条数据,我选择了21个字段输出为TXT文件,想用Python稍微处理一下,统计一下这1.4万条微博里面表情使用情况,统计结构在最后。
无聊的时候用了下新浪JAVA版的API,对JAVA还不熟悉,但是稍微改一下还是没问题的,数据保存为TXT文件,再用Python处理,JAVA部分很简单,Python部分只涉及到表情的正则提取,都不好意思写出来了。
1、调用新浪JAVA API下载微博广场数据
步骤思路:
初始化API的Weibo类,设置Token后,设置下载间隔,然后重复调用getPublicTimeline()函数就可以了,下面是主要类的代码:
这个不是完整的代码,没有初始化暂停间隔,可以掠过,很简单。
1 class WriteWeiboData{ 2 private int n; 3 public WriteWeiboData(int count) 4 { 5 this.n=count; 6 } 7 public void Start(){ 8 System.setProperty("weibo4j.oauth.consumerKey", Weibo.CONSUMER_KEY); 9 System.setProperty("weibo4j.oauth.consumerSecret", Weibo.CONSUMER_SECRET);10 try {11 //获取前20条最新更新的公共微博消息12 Weibo weibo = new Weibo();13 //weibo.setToken(args[0],args[1]);14 weibo.setToken("keystring", "keyscrect");15 for(int i=0;i<this.n;i++){16 System.out.print("Start to get weibo data num "+(i+1)+"/n");17 List<Status> statuses =weibo.getPublicTimeline();18 for (Status status : statuses) {19 SaveData(status);20 }21 try{22 System.out.print("Success to get weibo data num "+(i+1)+"/n");23 System.out.print("Sleep for 30 seconds");24 Thread.sleep(30000);25 }catch(Exception ee){26 System.out.print("Sleep Error");27 }28 }29 } catch (WeiboException e) {30 e.printStackTrace();31 }32 }33 public void SaveData(Status status){34 //Return data format:35 //created_at,id,text,source,mid36 //user:id,screen_name,name,provience,city,location,description,url,domain,gender,37 //followers_count,friends_count,statuses_count,favourites_count,created_at,verified38 //annotations:server_ip39 try{40 User user=status.getUser();41 FileWriter fw=new FileWriter("F:/Sina.txt",true);42 fw.write(status.getCreatedAt()+"/t"+status.getId()+"/t"+status.getText()+"/t"+43 status.getSource()+"/t"+status.getMid()+"/t"+44 user.getId()+"/t"+user.getScreenName()+"/t"+user.getName()+"/t"+45 user.getProvince()+"/t"+user.getCity()+"/t"+user.getLocation()+"/t"+46 user.getDescription()+"/t"+user.getURL()+"/t"+user.getUserDomain()+"/t"+47 user.getGender()+"/t"+user.getFollowersCount()+"/t"+user.getFriendsCount()+"/t"+48 user.getStatusesCount()+"/t"+user.getFavouritesCount()+"/t"+user.getCreatedAt()+"/t");49 fw.write("/n");50 fw.close();51 }52 catch(Exception e){53 System.out.print("IO Error");54 }55 }56 }
2、数据格式:

要取得数据就是微博内容,先练一下手玩玩。
3、Python处理数据
目标:查看微博用户表情使用情况,暂时只分性别,如果积累了合适的数据后可以分析各个时间段人们爱用哪种表情。
步骤:
$ 读取TXT文件,递归处理每一行
$ 单独提取出微博字段,正则提取表情字段,同时把性别提取出来,放到一个dict里面,dict的格式是:表情/女性使用频率/男性使用频率,递归处理,累积频率
$ 把结果写入到文件
注意:Python正则提取中文部分,先解码成unicode编码,再正则提取,表情的标志是[],虽有误差,但无大碍。
代码:
__collection函数是处理函数,返回处理结果(dict)
1 class EmotionFrequent(): 2 infoFile='F:/Sina.txt' 3 def __init__(self): 4 pass 5 def __collection(self): 6 f=open(self.infoFile) 7 d=dict() 8 n=1 9 for line in f.readlines():10 if line.strip()=='' or line.strip()=='/n':11 pass12 cols=line.split('/t')13 if len(cols)<20:14 continue15 n+=116 es=[]17 #if cols[2].find('[')!=-1 and cols[2].find(']')!=-1:18 info=cols[2]19 for i in re.findall(r'/[/S+?/]',info.decode('utf-8')):20 data=i[1:-1].encode('utf-8')21 if d.has_key(data):22 if cols[14]=='f':23 d[data][0]+=124 d[data][2]+=125 else:26 d[data][1]+=127 d[data][2]+=128 else:29 if cols[14]=='f':30 d[data]=[1,0,1]31 else:32 d[data]=[0,1,1]33 print 'Total records num '+str(n)34 return d35 pass36 def WriteDict(self):37 d=self.__collection()38 f=open('F:/keys.txt','w')39 for k in d:40 f.write(k+'/t')41 f.write(str(d[k][0])+'/t')42 f.write(str(d[k][1])+'/t')43 f.write(str(d[k][2])+'/n')44 f.close()45 pass46 def Run(self):47 self.WriteDict()48 pass 脚本运行结果:

把结果放到EXCEL里面重新排序,得到如下结果:
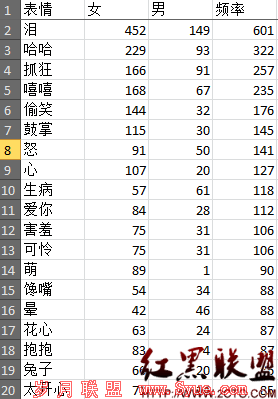
至于怎么解读这个结果,有没有意义,各有各的想法
5、今晚才把正则认真看了一下,虽然很久之前就知道应该掌握正则表达式
6、没有写博客的习惯,写得难看见谅。
晚安
作者:L Cooper
图片内容
最近更新
随机推荐
- 伪装攻击 IP地址的洪水Ping攻击详解
- iPhone存在安全问题 将轻易被网络安全
- 6成网站含重大漏洞 多因疏于管理
- Sun安全公告:Sun ONE Application S
- 视频网站发难百度版权 实为移动流量入
- 夜神猎人新版V1.1.10 全面打通翻译兼
- 前三季度国内科技并购交易额453亿美元
- APP威胁出租车行业:挑战仍大 多方打
- SonicWALL SSL-VPN登录页面远程格式串
- 我用电脑黑了全世界(六十八)
- MS07-033:Internet Explorer月度累积
- 亚马逊移动应用商店开始支持HTML 5网
- LG钢净洗衣机捍卫家人健康 高效抑制细
- 感染25万台电脑 一黑客面临60年监禁
- 中信保诚人寿创新推出Airdoc人工智能
- 当“雾”之急 LG空气净化器帮你给空
- 微软称黑客已利用陷阱Windows 7发起攻
- 美团确定摩拜将退出海外市场 减少运营
- 网易花田搅局婚恋网 社会化婚恋的逆袭
- 支付宝与腾讯的“爱恋纠葛” 就这样