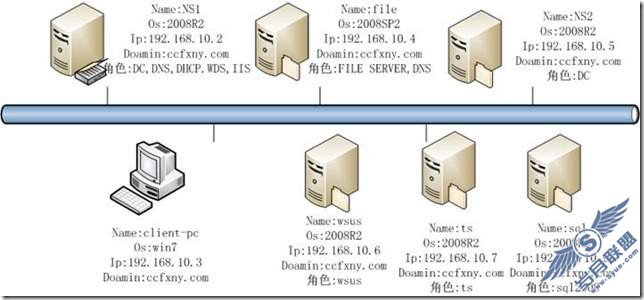
SQL Server 2008新特性之数据仓库可扩展性(2)
SQL Server 2008中新的资源监控器使你可以控制分配给你的关系型数据库工作负载不同部分的CPU和内存资源的数量。它可以用来防止失控查询(它阻止资源分配给其它工作负载)以及为你的工作负载重要部分预留资源。SQL Server 2005资源策略平等地对待所有的工作负载,并按需分配共享资源(例如,CPU带宽、内存)。这有时会引起资源分配不按比例,从而导致性能不均衡或意料外的速度降低。
资源监控器的首要目标如下所示:
a. 监控:使得可以监控每组请求的资源消耗(工作负载分组)。
b. 可预测性:使得能够对存在资源竞争的环境中预测工作负载的执行。这是通过显示制定工作负载间的资源边界来完成的(通过资源池控制)。资源边界的使用还能防止或降低查询失控的可能性。资源监控器所提供的监控功能使得更容易发现失控查询。
c. 优先级:使得可以设置工作负载优先级。
要理解资源监控器,有三个新的概念是很重要的:工作负载分组、资源池、分类(和分类器用户定义的函数)。
◆组:一个工作负载组,或组,是一个用户指定的请求分类,它与应用于每一个请求的分类规则类似。组的值存在于资源消耗聚合监控和一个用于组内所有请求的统一政策中。组定义了用于它的成员的政策。
◆池:一个资源池,或池,它显示了服务器一部分物理资源。根据它的设置,池可以有固定大小(每一个的最大和最小资源使用设置是相等的)或者在多个池之间共享一部分(它的最小小于它可用的最大设置)。在这种情形下,共享只是意味着资源提供给最先请求资源的池。在默认配置下,所有的资源都是共享的,因此维护向后兼容SQL Server 2005政策。
分类:分类是一组用户编写的规则,使得资源监控器可以将请求分类到之前描述的组里面。它是通过一个梯度Transact-SQL用户定义的函数(UDF)来执行的,UDF旨在作为资源监控器的一个“分类器UDF”。
这些概念在下面的图片里进行了描述。
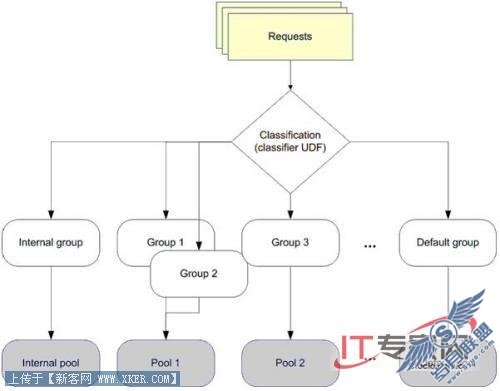
图5: 资源监控器例子:请求、分类、组,以及池
资源监控器可以用在没有任何应用程序改动的情况下。
4. 集成服务的改进
进行ETL将数据从你的操作系统中移到你的数据仓库里会是一个要求时间的工作。为了使这个过程更快,SQL Server 2008集成服务(SSIS)推出了两个重要的可扩展性特性:改进的Lookup性能和改进的转移管道性能。
4.1 Lookup性能
在SSIS中的Lookup 组件运行得更快,并且比在SQL Server 2005中更容易编程。一个lookup测试在记录流里每一行记录是否在另一个数据集里有一个相匹配记录。一个lookup就像一个数据库关联操作。一般情况下,你在整合过程中使用lookup,例如从源系统获得信息组装一个数据仓库的ETL层。
一个lookup建立一个用于保存从探测数据集获得记录的缓存。在SQL Server 2005中,Lookup组件只能从特定的OleDb连接里获得数据,而且缓存内容只能使用一个SQL查询来获得。在SQL Server 2008中,新版本的Lookup使你可以使用一个在同一个包或不同包里的单独管道来生成缓存的内容。你可以使用任何地方而来的源数据。
SQL Server 2005在每次使用缓存的时候将它重新加载。例如,如果你在同一个包里面有两个管道,每一个都要求相同的参照数据集,每一个Lookup组件将缓存它自己的拷贝。在SQL Server 2008中,你可以将这个缓存保存到虚拟内存或永久的文件存储。这意味着在相同的包里面,多个Lookup组件可以共享相同的缓存。你可以将这个缓存保存到一个文件并将它与其它包共享。这个缓存文件格式为了加快速度进行了优化,并且对它的访问比从原始关系型数据源重新加载这个参照数据集要快几个数量级。
在SQL Server 2008中,Lookup组件推出了不匹配缓存(miss-cache)特性。当这个组件配置为直接对数据库进行查找时,不匹配缓存特性通过可选地将在参考数据集中的不匹配入口键值加载进缓存从而节省了时间。例如,如果这个组件从进来的管道得到值123,但是Lookup组件已经知道在参考数据集里没有匹配入口,这个组件将不会再在参考数据集里查找123。这降低了到数据库中的一个多余而又昂贵的旅程。这个不匹配缓存特性在某些场合下可以将性能提高40%。
其它对Lookup组件的改进之处包括:
◆优化的I/O路径使得缓存加载和查找操作更快速。
◆更直接的用户界面,简化了Lookup组件的配置,特别是缓存选项。
◆输入中不匹配至少参考数据集中的一个入口的记录会被发送到不匹配输出。错误输出只处理错误,例如截断。
◆在查找转换中的查询语句可以在运行时做更改,使得编程转换更加灵活。
◆改进了信息和错误消息来帮助故障排除和性能分析。
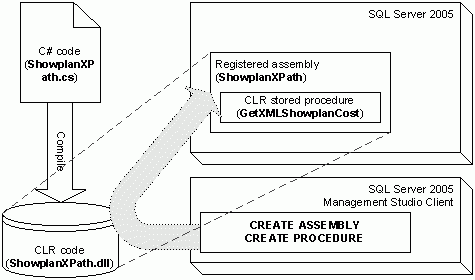
下图描述了一个使用这个新Lookup的场景。
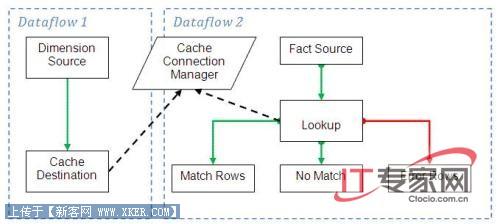
图6: Lookup场景
数据流1从一个定制源组装了一个缓存连接管理器(Cache Connection Manager,CCM),然后数据流2使用相同的CCM来组装lookup的缓存。这个图片还显示了Lookup组件3个输出的使用。
4.2 管道性能
在SQL Server 2008 SSIS 中,几个线程可以一起协作进行在SQL Server 2005 SSIS中要求一个单独线程自己进行的工作。这使你的ETL性能可以提高几倍。
在SQL Server 2005 SSIS 中,管道并行是非常粗糙的。当用户有一个简单的包,其中具有一个或两个执行树时,只会使用一个或两个处理器,并且这个包可能不会获益于具有几个处理器的多处理器机器。即便是用户使用多点传送将数据流逻辑上分割,一个多点传送的所有输出路径页属于同一个执行树,并且它们由SQL Server 2005 SSIS数据流任务连续执行。
为了获得高级并行,在SQL Server 2008 SSIS 中的管道允许更多的并行处理,这意味着使用多处理器机器可以获得更高的性能。
通过使用一个共享线程池,多点传送的多个输出可以同时执行。简要的说,这个多点传送提供了在每一个输出上具有一个可用缓冲的能力,并且不只有一个缓冲(和一个可用线程),这个能力提供给每一个输出。你不需要使用“Union All”技巧作为一个平台来推出更多的并行。
例如,假设你有一个包含具有四个输出的多点传送数据流。每一个输出都流入一个聚合里。在SQL Server 2005 SSIS 中,同一时间只处理一个聚合。在SQL Server 2008 SSIS 中,这四个聚合可以并行处理。
下图显示了增强的SQL Server 2008管道并行是怎样工作的。
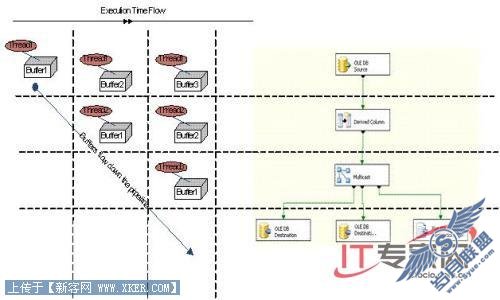
图7: 集成服务中改进的管道并行
5. 分析服务的改进
SQL Server 2008分析服务(SSAS)使用新的块计算、写回和可扩展的共享数据库执行特性显著地提高了查询速度。管理能力还改进了备份更大规模数据库的能力。
5.1 MDX查询性能:块计算
在SQL Server 2008 SSAS中改进的块计算主要通过只作用于立方体空间的非null值从而加快了MDX查询处理。它没有花费时间评估null单元。子空间计算的主要思想通过与一个计算的“本地”逐个单元评估相比较可以很好的得出。假设一个计算RollingSum 计算了上一年和今年的销售总和,而一个查询是查找RollingSum 2005年所有产品的总和。
RollingSum = (Year.PrevMember, Sales) + Sales
SELECT 2005 on columns, Product.Members on rows WHERE RollingSum
这个计算的一个逐个单元评估过程如下图所示。
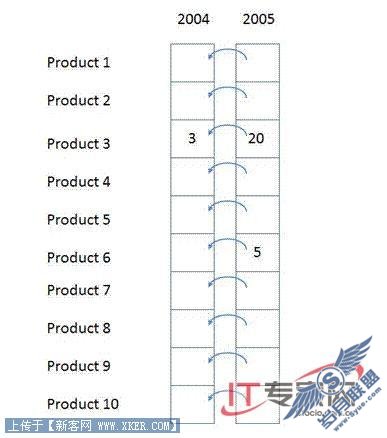
图8: 逐个单元评估例子
[2005, all products]的10个单元轮流评估。对于每一个,我们回到上一年,取得销售值,并将它添加到今年的销售里。这个方法有两个明显的性能问题。
首先,如果数据是稀疏的,那么即使是会返回一个null值的单元也会被计算。在这个例子里,计算除了Product3和Product6以外的任何一个单元都是种浪费。这个影响可能极大——在一个稀疏立方体种,被评估的单元数目可能会相差好几个数量级。
其次,即使数据总的来说是密集的——意味着每一个单元都有一个值并且没有浪费时间访问空单元,也还是有重复的工作。每一个产品都重复做了相同的工作(例如获得上一年成员、为上一年单元建立新的上下文、检查递归)。将这个工作从评估每一个单元的内部循环中删除将会使得更为高效。
现在假设使用一个子空间计算方法来执行相同的例子。首先,我们以自己的方式建立一个执行树,确定应该填写哪块空间。假设我们需要为下面的查询计算空间:
[Product.*, 2005, RollingSum]
假设有这个计算,这意味着我们必须先计算空间:
[Product.*, 2004, Sales]
接着这个空间:
[Product.*, 2005, Sales]
然后对这两个空间应用‘+’操作符。
销售是一个基本测量,所以我们简单获得存储引擎数据将这两个空间填写在叶子节点,然后生成这个树,应用这个操作符填写根节点的空间。因此获得了这个记录(Product3,2004,3)以及这两个记录{ (Product3,2005,20),(Product6,2005,5)},并对它们应用了+操作符来生成结果。
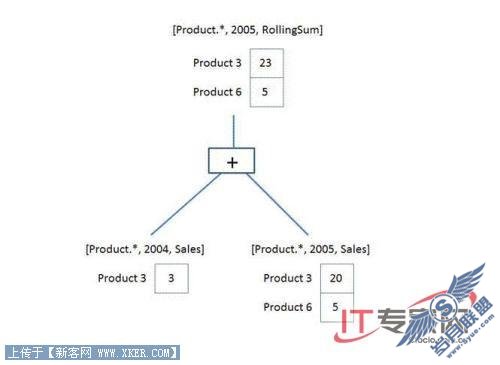
图9: 避免对NULL单元进行操作的块计算例子
+操作符操作于空间,不是简单的数量值。它结合两个空间以生成一个包含每个空间中产品的空间,它的值是它们的总和。
我们只对可用于结果的数据进行操作。我们不打算对整个空间执行计算。
5.2 查询和回写性能
回写操作的性能,以及对回写数据的查询,在SQL Server 2008分析服务中获得了提高。在分析服务中的单元回写是提供给终端用户在叶子级或聚合级更新单元值的能力。单元回写为每一个测量组使用一个特别的回写分区,它存储了最新的单元值和原始值之间的不同(delta)。当一个MDX查询请求这个测量组的单元数据时,存储引擎访问所有分区,包括回写分区,并将结果聚合以生成正确的单元值。
在SQL Server 2005和更早的版本中,分析服务要求回写分区具有ROLAP存储。这通常是单元回写中发生性能问题的原因,因为ROLAP分区按需查询关系型数据源以获得它们的数据。在SQL Server 2008中,我们允许回写分区使用MOLAP存储。从压缩MOLAP格式获得回写数据比查询关系型数据源要快得多。因此,MOLAP回写分区具有比ROLAP更好的查询性能。这个性能改进的多少是很大不同的,并且取决于一些因素,包括回写数据的大小和查询本身。
MOLAP回写分区还应该提高了单元回写性能,因为服务器从内部发送查询来计算回写delta,而这些查询很可能访问回写分区。注意,回写事务提交可能会慢一些,因为服务器不只要更新回写表,还必须更新MOLAP分区数据,但是这与获得的其它性能相比就无关紧要了。
5.3 分析服务加强备份
在SQL Server 2008服务中你会发现其中的一个性能改进是新的备份存储子系统。现在的备份存储子系统已经重写了,它使得可以得到更好的性能和可扩展性。这个改变对于你的应用程序来说是透明的——使用它不必改动代码。
新的备份存储子系统为分析服务备份文件推出了一个新的格式。这个文件名称扩展名没有改变。但是,内部的格式不同了,所以备份可以很好的升级到可以处理GB规模的数据库。
SQL Server 2008分析服务备份完全向后兼容SQL Server 2005分析服务。它使得你可以恢复在SQL Server 2005分析服务中备份的数据库。SQL Server 2008分析服务不具有以SQL Server 2005分析服务中所使用的旧格式来存储备份的能力。
新的高性能备份存储子系统允许客户执行新的备份场景。而在以前你需要依靠不成熟的文件系统拷贝工具来备份大型数据库,现在你可以使用与事务型系统集成在一起的内置备份子系统,并且可以与其它操作并行运行备份。
5.4 用于分析服务的可扩展共享数据
现在你可以就使用一个单独的数据库拷贝来升级你在许多小型服务器上的OLAP查询工作负载。SQL Server 2008分析服务通过一个叫可扩展的共享数据库(SSD)来支持这么做。
升级可以应用于很多场景和工作负载,例如处理、查询、数据和缓存管理。对于分析服务来说,最常见的升级场景是响应不断增加的并发用户数量,扩展多个服务器上的查询负载。这在过去是通过使用一个负载平衡解决方案来实现的,例如在多个服务器前面使用Microsoft Network Load Balancing (NLB)功能以及在服务器间复制数据。管理这样的环境会遇到许多挑战,而数据复制是主要的一个。可扩展的共享数据库特性使得数据库管理员可以将一个数据库标记为只读的,并将它从一个Storage Area Network(SAN)在多个服务器实例间共享,从而不再需要复制数据。这节省了磁盘空间,以及花费在拷贝数据上的时间。
下图描述了一个典型的SSD配置。
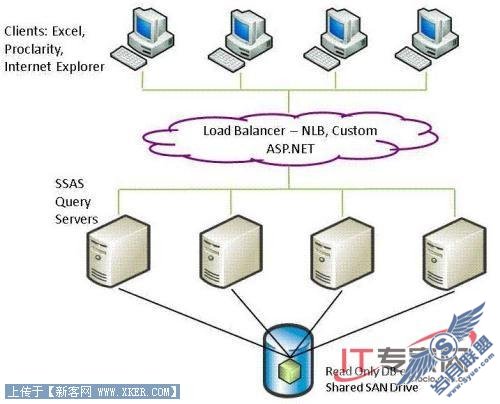
图10: 用于分析服务的可扩展共享数据库
提高性能的一个可选解决方案是升级,用一个单独的大型服务器替代多个小型服务器。升级的好处是在一个更大型的机器上,单独的查询可以处理的更快。但是通过SSD使用升级可以为你节省硬件(假设每个处理器成本更低),并仍然满足你对许多多用户工作负载的需求。此外,SSD允许你扩展为比可以用在一个单独的大型服务器上更多的处理器。
可扩展的共享数据库特性包含三个逻辑部分:
◆只读数据库:允许将一个数据库标记为只读的
◆数据库存储位置:允许一个数据库放在服务器数据文件夹外
◆附加/分离数据库:允许从任何UNC路径附加或分离数据库
这些特性一起使得可以查询升级场景。然而,每一个特性都是独立的,并且还有查询扩展以外的用法。
用于分析服务特性的SSD与在SQL Server 2005关系型数据库中推出的SSD特性工作方式类似。
6. 报表服务的改进之处
SQL Server 2008报表服务(SSRS)提供了性能、扩展和设计改进,使得它可以很好的满足你的企业报表需求。在这里我们着重介绍两个主要的可扩展性改进。
6.1 报表可扩展性
SQL Server 2008报表服务报表引擎与之前版本相比具有一个较大的提高,它可以渲染比以前大得多的报表。尽管这不是数据仓库的一个重要提高(它在操作性报表中也可以使用),但是它在一些数据仓库场景中是非常有用的。如果你创建具有几百甚至上千页的报表,那么SQL Server 2008报表服务可以帮助你更快地渲染报表。而且,在相同的硬件配置下,可以渲染的最大报表规模显著地增加了。
6.2 服务器可扩展性
SQL Server 2008报表服务不是运行在IIS内部。它可以管理它自己的内存,并具有它自己的内存限制。这使得你可以配置内存设置以便SSRS可以更加高效地与其它服务运行在同一台机器上,例如SQL Server。
7. 总结
QL Server 提供给你在数据仓库方面所需要的所有东西。在2008版本里,它进一步扩展,比之前版本都更加可以满足最大规模企业的需求。正如这篇文章里所描述的许多数据仓库改进之处,它与之前的版本相比改进了很多。你将看到最重要的改变是用于数据仓库建设、关系型查询处理、报表和分析的、改进的可扩展性。