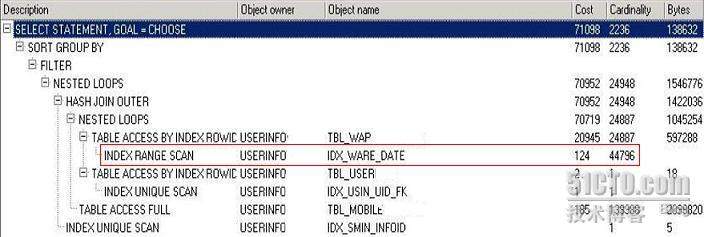
数据质量体系结构介绍
有三股力量已将对将数据集成、数据质量的关注呈现在组织管理层优先执行活动中。它们是:一、普遍地认为"如果仅能看到数据,而无法确定其质量等级,就无法更好的管理的业务"的认识,正在持续增长。绝大多数的知识工作者相信对自身的工作职能来说,数据是至关重要的;二、绝大多数的全球化的,分布式的组织机构逐步形成共识,集成分散在全球各地的业务数据是企业竞争力的必要因素;三、急剧增长法律符合性的要求也是一个重要的因素。
仅这三个方面的驱动力,对于强调数据质量的问题显然还并不充分。幸运的是, 还有一股强大的动力正来自除了IT部门以外的业务人员。业务人员正在逐步的认识到数据质量问题是一个严重的,需要高昂的成本的问题,这样,组织主动性地提供数据质量就有了更大的动力。但是,多数的业务人员可能并不能完全了解数据质量问题产生的原因,找到提高数据质量的方法。有时他们认为数据质量问题主要是IT部门操作层面的问题。在这样的情况下,IT部门就应该更加认识到:数据质量问题不可能仅通过IT部门来单独改善,更需要业务部门的积极、主动参与。事实上,数据质量领域一个极端的看法认为:"数据质量问题几乎和IT没有任何的关联"。
在关注数据质量时,如果仅仅要求前台的操作人员在输入数据时保持足够的细心,或要求销售人员在录入订单的客户和产品信息时保持足够的仔细显然都是不够的。我们还可以通过在数据的录入界面上附加更加严格的技术性约束来避免和修复数据的质量问题。这些方法提供了一些修复或避免数据质量问题的线索,但是在采取这些技术性措施之前,我们需要用一个更大的视野关注数据质量问题。例如:在一个零售银行,身份证号码是空白的或者是填入了一些垃圾信息。一个不错的想法是增加一个诸如必须满足999-99-9999的技术限制,系统不接受任何不满足格式约束的输入信息。在这种约束下,身份证号码可能不再为空或者任何字符数据,但前台的数据录入人员就会由于完成后续工作的需要而被强迫录入有效的身份证号码,但在并没有客户有效身份证号码的情况下,他们只好使用了自己的身份证号码。
1. 建立质量传统、重建运行过程
众所周知,如果没有来自组织高层对建立企业范围的数据质量体系的承诺,技术人员说明的数据质量问题尝试往往很难发挥作用。在日本,汽车制造商通常将控制数据质量的态度渗透到组织的各个层面,从CEO到一线的生产线人员,从而保证了其准确、高效的决策效率。为了说明管理层对建立数据质量文化的重要性,我们使用一个大型的连锁药店作为例子来说明,在这家药店,采购部门和数量庞大的供应商保持合作、供应关系。在采购部,采购助理将每一个采供来的药物录入到IT系统当中,这些信息包含大量的属性。这样采购助理会面对巨大的工作量,他们不得不评估一个小时他们可以录入多少的数据,多长时间才可以将这些信息录入完毕。同时,采购助理也没有清晰的概念,谁将使用那些数据,那些数据对那些使用者更加重要。有时,采购助理会由于明显的输入错误受到指责,但更麻烦的情况是,采购助理拿到的数据本身就是不完整或不可靠的。例如:对药物的毒性水平,没有规范化的标注,长期以来,不同的药品,不同的品类,这个指标都是各不相同的。那么,这个药店应该如何提高数据质量呢? 这里有一个9步骤的数据质量模版,它不仅可以用到这个药店,也可以应用到其他任何一个希望对数据质量进行管理的组织。这9个步骤包括:
● 获得来自组织高层对数据质量文化的承诺
● 在执行层面上,形成保证数据质量的工作流程
● 对提高数据录入的环境有所投资
● 提高应用间集成性
● 需要投入成本来改变存在问题的工作流程
● 提高end-to-end的团队理解
● 提升部门间的协作
● 公开的表彰数据质量提升的事件
● 提供持续的过程,不断的量度和提升数据质量
从上面我们可以看到,在这个药店,需要一些资金用于修改数据数据录入系统,为采购助理提供一些录入时的选择和上下文提示。公司的管理层也需要明确地强调采购助理工作的重要性,指明采购助理的工作是公司各个层面决策正确、有效性的基础。采购助理的辛勤工作应该受到来自管理层的公开的表彰,并进行奖励。从而达到实现团队的end-to-end互相了解和欣赏。
在执行层的支持和组织框架就需之后,就需要选用特定的技术方案。后面,我们将讨论如何选择、使用恰当的技术来支持数据质量目标。这些技术目标包括:
● 早期的诊断和治疗数据质量问题
● 明确对源系统的需求,集中力量提供更高质量的数据
● 明确地描述在抽取、转换和加载过程中遇到的数据的错误问题
● 提供捕捉数据质量问题的框架
● 提供精确的度量数据质量的框架
● 为最终的数据提供质量信心度量
2. 数据质量探查的角色
数据质量探查是一种描述数据上下文、一致性、数据结构的分析技术。某种意义上说,当使用SELECT DISTINCT对某些字段数据查询时,就在完成一个数据质量探查的工作。现在,已经有很多功能强大的工具可以帮助完成数据质量探查的工作。一般来说这些工具已经提供了非常方便的接口来帮助用户了解数据和数据间的关系。在数据仓库项目中,数据质量探查可以同时在战略和战术的的层面上扮演重要角色。在DW项目开始时,一个数据源确定之后,就需要首先对它进行一次快速的数据质量探查过程来评估数据质量,为是否才用其作为有效的数据源作为策依据。理想的情况下,这种战略性的评估应该在1,2天内完成。早期的了解数据、揭示数据的问题是一个负责任的步骤。几个月后才进行这项工作,对项目的目标有可能会是致命的。
从战略的角度决定将这个数据源纳入到项目中后,还需要有一个详细的战术性的数据质量探查来尽可能揭示更多的数据问题。在这个阶段揭示的问题最终需要呈现在详细的规格说明中来处理,处理的方式包括:1) 将这些数据反馈给源系统,提请修正这些问题;或2) 将这些问题数据的处理融合到ETL过程中。我们相信绝大多数的数据问题都可以在这两个过程中揭示出来,并得到解决。
3. 质量Screen
质量Screen是数据仓库ETL架构的心脏,在数据流图中它担负着数据质量医生的作用。质量Screen简化了在ETL或数据迁移过程中测试工作实践。如果测试通过,一般不需要记录任何事情;但是如果测试失败,Screen必须要完成:
● 将错误事件记录到错误事件主题中,并
● 选择中止处理过程,将用于恢复的数据放到的临时存储中或者仅仅标记错误的数据
所有的质量Screen在架构上是相似的,参照Jack Olson的分类方式,分为三个简单类型:列Screen、结构Screen和业务规则Screen。
列Screen用于测试单一列中的数据。列Screen过程通常比较简单,进行一些比较明显的测试,如:某个列包含不希望的NULL,列值超过了定义的列的精度,或列值不满足格式的要求。
结构Screens测试跨列的数据间关系。例如:列间的层次关系、一对多的关系。结构Screens包括测试两个表域间的主外键关系, 也包括对邮政地址的整个数据块的测试。
业务规则Screens实现更加复杂的、不适合列和结构Screens的测试。例如:客户的Profile可以进行依赖时间的业务规则进行测试。如:白金卡的常旅客要求至少5年,并每年至少2万公里的飞行距离。业务规则测试也可以进行聚合规则的阕值的测试等。
4. 错误事件主题模型
错误事件主题模型是一个集中式的维主题模型,它用来在保存质量Screens过程中抛出的错误事件。这个方法可以方便应用在通常的数据集成应用中。在下图可以见到错误事件的ER模型:
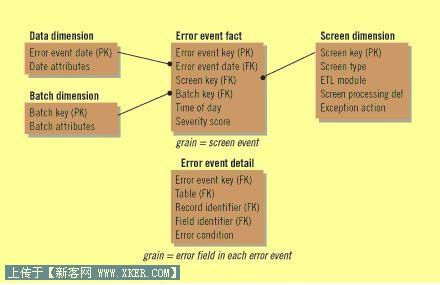
图1: 错误事件主题模型
这个模型的主表是错误事件事实表。它的粒度是在ETL或数据迁移时质量Screens中抛出的错误事件。事实表的粒度是事实表纪录内容的物理描述。即,每一个质量Screen错误在这表中产生一条记录,表中每一条记录对应一个发现的错误。
错误事件的主题模型包含的维表包括错误发生的日历日期、Screen和Batch工作维。日历日期不是用分秒表示的时间戳信息,而是提供了一种通过通用的日历日期属性对错误事件提供约束和聚合的有用信息,例如:工作日、财年的最后一天等这样的描述信息。事实表中的Time-of-day列则是一个完整的时间戳,用于精确的描述错误发生的时间。这样格式在希望用时间做一些计算方面是非常有用的,例如计算两次错误发生的时间间隔等。
Batch维不仅能处理批操作,也可包含持续的操作过程。Screen维精确的描述了Screen的标准是什么,当错误发生时我们应当做什么?(中断处理、发出信息挂起某些操作或者仅仅对数据进行标记等)。
错误事实表包含一个唯一的主键Error Event Key。和维表的主键一样,这是一个用整数序列生成的代理键。这个键域是非常有必要的,保证大量的错误在一次操作中同时发生时,将其加入到这个事实表当中的时候。当然,这种错误情况最好不要发生。
这个错误事件主题还包含另外一个事实表,以更加详细的粒度纪录这个发生的问题。在这个表中的每一条记录标示了数据记录中发生错误的每一个域。这样,就可以记录和处理诸如复杂的结构或者业务规则在更高的层面上发生的问题。这样的错误有可能在Event Detail 事实表中产生多条记录。两个事实表通过Error event域间的主外键关系进行关联。这样Error Event Detail表就可以从表、记录、域的角度精确的描述发生的问题,同样在这个表中通过主外键关系继承来自高粒度事实表的Date、Screen、Batch的信息。到目前为止,我们已经拥有了一个可以处理复杂的多域、多错误的主题模型。
错误事件细节表也可以包含精确的时间戳用于提供完整的、精确的描述在一段时间内错误多个纪录的聚合阕值问题。
5. 响应质量事件
从上面,已经注意到对每一个质量Screen都需要有所应对。可能的选择包括:1)终止处理过程; 2)设置防御性标志挂起进程用于后续的附加操作;3)标记问题内容,继续后续的处理。这三个选项都可能不是的最佳选择。中断处理是一个明显的痛苦的选项,中断之后,我们还不得不进行手工的干预、诊断,选择重新启动、从断点处处理或者完全的结束这次的工作,进行异常恢复。选择挂起也不是一个很好的选择,因为没有人清楚什么时间问题可以被修复,甚至是否可以被修复。一般的推荐,对很小的数据问题,尽量不要使用挂起的策略。第三个选择,标记问题数据继续进行处理往往是比较好的。错误事实表的数据在下面的审计维中会有所讨论。错误的维数据也可以借鉴审计维的方式,同时为了以防万一,对数据丢失或者产生垃圾数据,也可以用域本身对错误进行标记处理。
6. 建立审计维
审计维和其他维类似,在ETL后台处理中与事实表关联。下图是针对Shipment Invoice事实表和与其相关的审计维的例子:

图2: 审计维样例
上图中Shipment是一个典型的事实表,包含一大串的外键用来与维表关联,还有三个用DD标示的退化维和6个数字的域。这是数据仓库维模型设计中是一个典型的结构。
审计维包含事实表创建过程的元数据描述。数据质量系统的设计人员可以选择在错误发生时,保存获得或多或少的元数据记录。用上面的例子说明审计维表的产生产生过程。假如Shipment事实表每天以批操作的方式处理一次。今天运行的非常好,没有任何的错误纪录或标记。在这种情况下,只需要在审计表中生成一条审计纪录。这样,所有的错误信息对每一条事实记录将是相同的,它的作用仅是表明今天的工作一切正常。
如果上面的假设不存在,运行进程或者数据常常发生问题,例如,折扣数据有问题,触发了一个Out-of-Bound错误。就需要在审计维表中用一些信息来记录发生的问题,需要考虑如何对错误条件和版本号选择恰当的值,将错误问题的主外键关系进行恰当的关联。更多的关于这方面的详细信息请参阅《The Data Warehouse ETL Toolkit 2004》。
在完成最终的审计报告时,看看下面的审计报表,会发现一些可爱的地方。如下图:

图3: 利用审计维产生的报表
图中上测的那个报告看似是个正常的报表;但是下面的报表,可以清晰的揭示报告中存在的异常。在有审计维的体系结构中,通过一个简单的命令,这些质量审计报表就可以快速地实现。
7. 应用Six Sigma质量标准
借鉴制造业成功的质量管理实践,这些经验在数据仓库的领域也是非常有用的。在制造商的世界里,6 Sigma质量实践已经在帮助他们取得了具体、明显的质量进步,甚至将缺陷率降低到百万分之3到4的水平。而错误事件主题模型是一个非常好的基础,可以用来才采用6 Sigma标准来指导数据仓库领域的质量的实践。在错误事实主题中记录的所有的错误事件使得我们有机会通过使通过特定的机制对质量问题进行监控、评估,用于未来的改善。
本文中描述的数据质量框架,提供了一种可以以较小的代价,增量的添加到已有的数据仓库和数据集成环境中。一旦错误事件主题模型成功地建立之后,我们可以根据实际的环境确定质量Screen实施进度。需要完成的就是后面两个具体的两个工作:记录每一次发生的问题;决定对特定问题的特定的处理方式。错误Screen的实现并不拘泥于特定的技术,可以嵌入自己的代码中,也可以借助于特定的专业化的ETL 工具。
当然,数据质量管理过程是一个没有终点的过程,也没有统一架构原则。这里提供的是一种针对数据仓库项目可以简单实现的、可扩展的、一种相对比较完善的捕捉数据质量事件,同时对其进行量度和控制的方法。