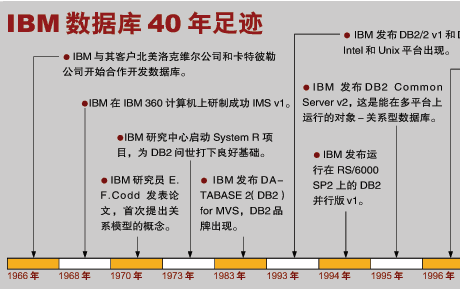
IBM DB2 Connect简介
在本系列的 第 1 部分中,我们初步地谈到了 Connect 提供的不同编程接口以及实现这些接口的驱动程序。在最后的几节中,我们大致地描述了 Connect 提供的通信基础设施,并看到这个基础设施如何大大减少对大型主机资源的使用,如何允许分布式应用程序充分利用大型主机平台的优势(例如轻松地管理混合工作负载以及提供连续的应用程序可用性)。
您可能仍记得图 1,在这幅图中, Connect 由编程接口(被实现为 JDBC™、SQLJ、ODBC、 CLI、OLE DB、.NET® 和 Embedded SQL 驱动程序)和一个通信基础设施组成。
图 1. Connect 由编程接口和一个通信基础设施组成,通信基础设施使客户机服务器应用程序和基于 Web 的应用程序能利用大型主机的优势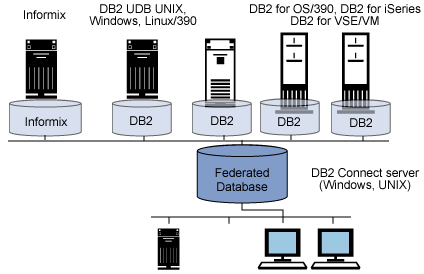
我们将在本文中讨论上述通信基础设施的功能之一,即 Connect 如何提供对异构型分布数据的统一访问。
在讨论这种解决方案在统一访问、分布式和异构等方面的细节之前,我们需要先将目光转向通信基础设施本身。 Connect 以通信服务器的形式提供这种通信基础设施,通信服务器可以部署在 Windows®、Linux (例如 Linux for zSeries)和 UNIX® 服务器上。这种通信服务器是使用在构建 UDB 数据库服务器时所用的相同代码基础构建的,因此,它继承了 UDB 服务器那种架构中具备的所有品质。
实际上,我们在本文中所描述的功能有一个要求,那就是在 Connect 服务器本身上创建一个数据库(在这里您不需要 Universal Database™ (UDB))。乍一看来,这似乎与本系列第 1 部分中的说法相矛盾,在那里我们说 Connect 只是将应用程序连接到 for z/OS 和 for iSeries® 数据库, Connect 并不管理数据。然而需要澄清的是,我们要在 Connect 服务器上创建的这个数据库并不存放数据。它只是作为一个单一的连接点来使用,以便向应用程序提供统一的或单一的数据库镜像。于是, Connect 服务器只是将对数据的请求路由到真正管理数据的不同数据库服务器。本篇文章发表于
虽然在第 1 部分您了解到真正使 Connect 有别于其他竞争者的通信管道的一些特性,但您很可能已经知道, Connect 至少尽到了责任(将应用程序连接到大型主机)。现在您对 Connect 的底层架构有了更好的理解,接下来是该提供比本系列文章的第 1 部分(副标题 - 内有乾坤)更进一步内容的时候 ―― 我们将从这里开始第 2 部分。
在第 2 部分中,我们将谈到作为数据访问平台的 Connect,在这里我们不仅仅是谈论大型主机上的 。例如,您知道吗, Connect 工作站可以在同一个事务中执行一个 for z/OS 数据库和 Windows 数据库上的 Informix® IDS 之间的分布式连接(join),它还可以在同一个提交范围内使用内建的对两阶段提交(two-phase commit,2PC)的支持来更新这些数据源。我提到过您将发现一些巧妙的特性,这就是其中之一!如果说这听起来像是联邦,或者更像是 WebSphere® Information Integrator (前身为 Information Integrator),那就对了。实际上,所有 UDB 和 Connect 服务器都附带了 WebSphere Information Integrator 对整个 UDB 家族和内建在引擎中的 Informix IDS 的联邦支持。WebSphere Information Integrator 之类的产品扩展了联邦引擎的范围,使之包括其他关系数据源(、Microsoft® SQL Server)、非关系数据源(ADABAS、VSAM)、OLE DB、XML 和企业中任何其他数据源。
对异构型分布数据源的统一访问
您也许知道统一(unified)、分布(distributed)和异构(heterogeneous)的意思是什么,但可能并不清楚 Connect 是如何实现这些概念的。您也许熟悉 IBM WebSphere Information Integrator 产品,并且会想,这些词语很好地描述了这些产品。请继续阅读本文,如此一来这些产品之间的相互关系就会变得更加清晰。
统一访问是减少在异构环境中开放应用程序的复杂性的一种非常好的方法。虽然应用程序编程人员总能一一建立到各个数据源的连接,但更容易的方式还是在应用程序中只使用一个数据库连接。到不同数据源的不同连接需要多个驱动程序(例如,一个单独的 和 Informix JDBC 驱动程序)。如果在应用程序中使用多个不同的连接,那么在对待数据时,就不能把数据看作是由单个数据库管理的那样(例如,应用程序编程人员必须从多个数据源取数据,然后才可以执行连接操作)。而且,当使用多个不同连接时,代码在应用程序中的位置便会固定下来,这样数据架构师就不能自由地修改数据的位置,以适应不断变化的业务需求。
相反,统一数据访问机制则为应用程序编程人员提供了到企业所有数据资产的单点连接。它允许使用单个 API (驱动程序),允许使用一种风格的 SQL(您不必担心 SQL Server 使用货币数据类型而 UDB 不使用这种类型),它还对数据位置进行抽象,以便可以在不影响现有应用程序的情况下更改数据位置。最后,它允许编程人员一致地对待所有数据,就好像它们来自同一个关系数据库,并且那个数据库可以在保证事务完整性的情况下管理对数据的连接、排序和过滤 ―― 并且,由于有了对 Connect 基本特性的扩展,后端数据源不必一定是关系数据源(例如,它可以是 VSAM 或 ADABAS 数据源)。
我希望您已经清楚,使用单个数据库比起协调对多个数据源的访问来要简单得多。但我们 IBM 信息管理解决方案的不同之处在于,我们并不期望您取消现有的应用,全部移植到 数据库,因为那样不现实。
Connect 通过以下三种不同机制之一实现简单直观的访问方法:
- 联邦数据库
- 存储过程
- SQL 函数
Connect 和联邦数据库
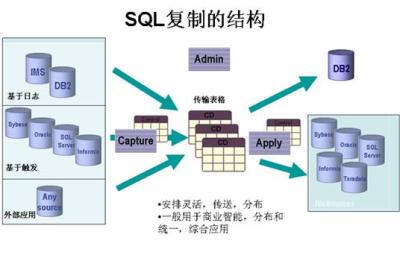
Connect 附带了一个内建的基础级联邦数据库功能。您可能对这个功能比较熟悉,因为之前 IBM DataJoiner 产品也提供了这个功能。从 Version 8 开始,联邦数据库支持已成为 Connect 和 UDB 服务器的一部分,任何人不需要购买额外的产品就可以使用该功能。换句话说,当您在 Linux、Windows 和 UNIX 服务器上部署了 Connect 服务器时,就可以创建一个联邦数据库,并且应用程序可以连接到这个联邦数据库。建立了与联邦数据库的连接后,请求被路由到真正的数据源 ―― 但是函数补偿、数据类型转换、有效数据检索的优化等复杂性对用户来说是透明的。
Connect 的联邦组件包括对 UDB for Linux、 UDB for UNIX 、 UDB for Windows、 UDB for VSE/VM、 UDB for z/OS、 UDB for iSeries 和 Informix IDS 数据库服务器的读/写支持。
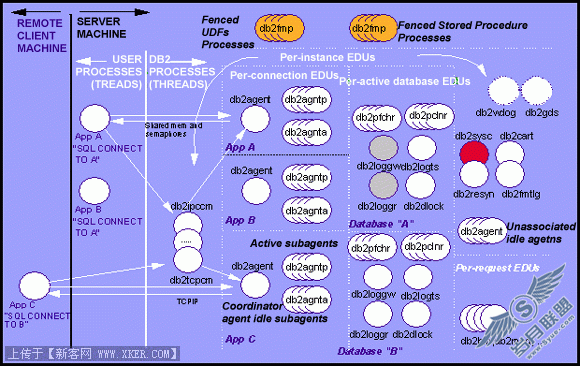
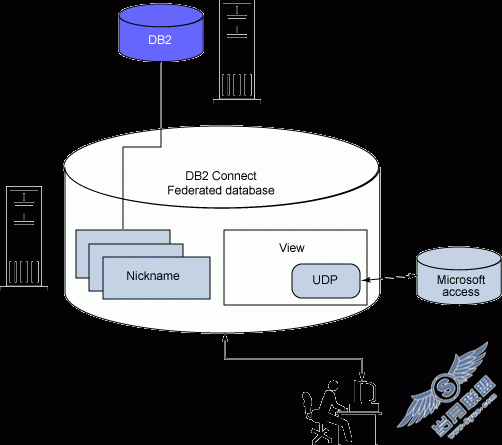
您可以使用 Connect 中的联邦功能来执行跨这些服务器的分布式请求,如图 2 所示:
图 2. Connect 的联邦数据库功能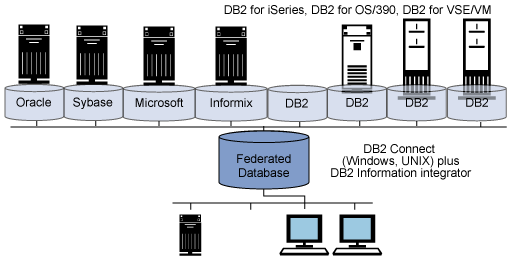
例如,以下语句:
|
可用于返回来自不同服务器上不同数据库中各种表的结果。例如,表 T1 可能在一个 UDB for z/OS 数据库上,它可以与表 T2 相连接,后者在一个 Informix IDS for Windows 数据库上。
这个功能使应用程序开发人员可以在同一条 SQL SELECT 语句中引用由 UDB 家族中多个成员管理的对象 ―― 完全不必知道查询是分布式的。使这种特性更强大的是,负责编写这类应用程序的开发人员可以把这些数据源看作本地 表(通过昵称),并使用相同的 SQL API 来访问每个数据源 ―― 这些操作甚至可以在他们各自的集成开放环境(IDE)中进行!他们不需要理解后端数据存储之间有何不同,因为在集成开放环境中,或者对于 SQL API 来说,这些数据存储像是一个虚拟的数据库(关于这方面的更多内容请参阅本系列的另一个部分)。
Connect 与 WebSphere Information Integrator 相结合作为联邦服务器
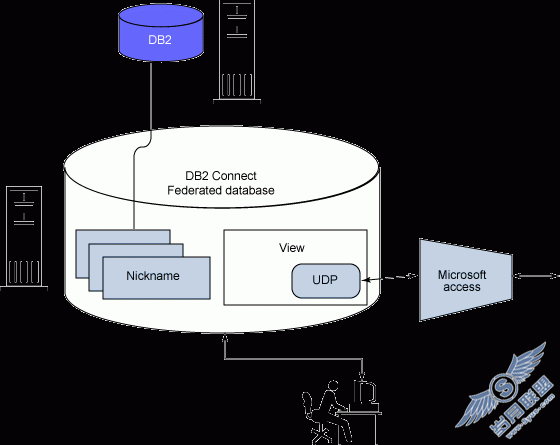
在前一小节中,您看到 Connect 如何以 UDB 和基于 Informix IDS 的数据源建立联邦数据库。当与 WebSphere Information Integrator 相结合时, Connect 可以提供对其他数据源的透明访问,例如 、Microsoft SQL Server、Sybase、IMS、VSAM 和大批其他的数据源。当 Connect 与 WebSphere Information Integrator 相结合时,上面的图可以增强到如下面的图 3 所示:
图 3. Connect 与 WebSphere Information Integrator 相结合时的联邦数据库功能,可用于更广泛的关系数据库访问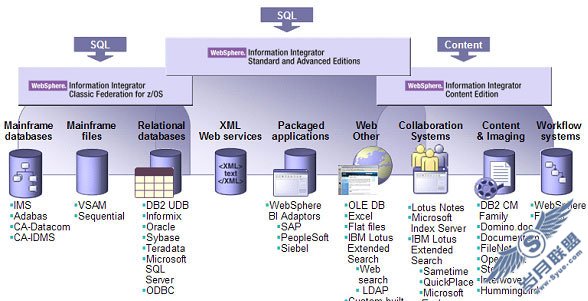
实际上,在这个场景中,该功能的完整形象看上去应该是这样的:
图 4. Connect 与 WebSphere Information Integrator 相结合时的联邦数据库功能提供了对任何数据的访问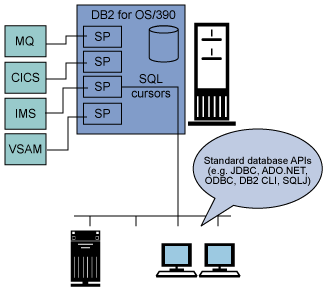
Connect 在其联邦核心中内建了一个智能的优化器。这意味着当您从一个 数据库选择很多数据时(如果您正在使用 WebSphere Information Integrator),优化器知道启发法、索引、基数和 数据存储的总体分布情况,并能够重写查询,以获得更好的访问方式。
UDB 凭借其自治的、强大的优化技术而成名已久,这种技术能提供对数据的快速访问:这些优点并没有随联邦功能而消失。相反,它们被内建在 Connect 的联邦优化器中。因此,当 Connect 充当联邦层时,它可以执行谓词叠加(push-down)或消除分支树(branch-tree),从而加快数据访问。 Connect 会判断是将谓词叠加到本地存储,还是带回完整的结果集并在本地应用结果集更有意义。取决于数据存储的并发特征或业务需求, Connect 甚至可以在这些外部数据源上创建一个温(warm)数据缓存,以便不需要牵涉到异构数据库。
深入分析联邦的能力超出了本文的范围,但要记住的最重要的一点是, 对于一名开发人员,在他自己的 IDE 中,只需一种 API,可以使用来自任何地方的各种数据 。在当今市场中,这些特征是无与伦比的,它们代表了一种伸手可及的专用 API 访问或“即购即换”方法学的解决方案,在今天这样注重成本的氛围下,这种方法学几乎被摒弃。最低限度是, Connect 是这些效率的一个起点,通过一个动态的选项,可以在需要的时候添加越来越多的数据源。
存储过程和统一数据访问
与其他作为竞争对手的数据库供应商提供的存储过程相比, 服务器中的存储过程在功能上有其独特之处。 存储过程中的代码可以重写,重写方式与应用程序其他部分几乎相同(例如,程序员或应用程序 DBA 可以使用自己喜欢的编程语言 ―― Java、COBOL、.NET 或 C ―― 并可以在数据库服务器平台上调用那种语言中可用的任何 API)。例如, 程序员可以(用 COBOL)编写一个调用 CICS 事务的存储过程,并将该存储过程部署到 for z/OS。因为调用存储过程的应用程序完全独立于存储过程实现的细节,因此调用者应用程序完全不知道它们在执行存储过程的时候,会引起对 CICS 资源的访问,也不知道这个存储过程是用 COBOL (这种语言对于程序员或 DBA 来说可能并不熟悉)编写的。
使用存储过程来访问数据的这种技术可以在 家族的所有服务器上使用。然而,这种技术最常用于 for z/OS 服务器,因为在那里非常需要一种统一的基于 SQL 的访问方式,来访问非关系大型主机数据(例如 VSAM/IMS 数据库)以及 CICS 和 IMS 事务程序形式的大型库存管理业务逻辑。另一种流行的技术是使用 WebSphere MQSeries® 中的消息队列来创建存储过程,这种存储过程通过消息传递来开始其他上的事务或业务逻辑。下面的图 5 展示了 Connect 之类产品提供的一些功能以及 家族对存储过程的支持。
图 5. Connect 借助于存储过程的数据访问功能

提供对非关系大型主机数据的统一的、基于 API 的标准访问模式,这样做的优点数不胜数。这种利用 存储过程的方法不仅简化了 Windows、Linux 和 UNIX 程序员的工作,而且使他们完全不必知道数据和程序逻辑的性质以及它们的位置。程序员完全没必要接受 CICS、IMS、VSAM 和其他大型主机技术方面的培训 ―― 但即使是最基层的程序员(每个人都知道如何调用存储过程)也能以一种良好架构的、可控制的(可控制的这个词很关键)方式来充分利用这些。例如,很多应用程序编程人员都擅长 Visual Basic.NET,但是他们可能完全没听说过 CICS。通过使用存储过程的方法,Visual Basic.NET 开发人员同样可以开发一个 CICS 应用程序,而只需使用与访问所有关系数据所用的相同的接口和方法。这可以大大节省应用程序开发的时间和开发人员的成本,因为可以使用更标准化的数据访问 API(例如 JDBC 和 ADO.NET)。
自然,存储过程本身需要开发和部署。这些存储过程通常是由熟悉这些大型主机技术的大型主机编程人员和 DBA 构建的。为了进一步简化构建存储过程的任务,IBM 提供了 CICS 和 IMS 事务的源代码样本(这些源代码可以不作修改地用于生产)。特别地,对于 CICS,IBM 提供了一个样本存储过程(名为 DSNACICS),它有助于大大简化通过 Connect 访问分布式应用程序或基于 Web 的应用程序中的 CICS 事务的过程。此外,有一个用户出口(名为 DSNACICX)为 DBA 提供了一种机制来抽象 CICS 接口的知识,并检查或覆盖由这些程序员提供的参数,以便取得更好的控制。
您可以通过阅读 Connect documentation 来了解更多关于 CICS 和 Connect 的知识。其中还提供了用于 IMS 的一个类似的存储过程,即 DSNAIMS 。本篇文章发表于
至此,您可能想知道,这种使用存储过程访问非 数据的方法是否适用于只读类型的操作,或者是否能用于现实中的事务。答案是,对这些数据源的访问是原子性的,通过 z/OS Resource Recovery Service (RRS) 功能可以保证数据完整性。例如,一个存储过程可以更新某些 UDB 数据,并执行 CICS 事务,如果这些操作中任何一个失败,则整个事务将回滚。因此,在使用存储过程来更新非 数据和执行非 事务时,数据完整性是完全有保障的。
对于运行在 Linux、UNIX 和 Windows 上的应用程序,还有其他方法可以访问大型主机数据和事务。为什么使用 Connect 和 存储过程,这是一个经常问到的问题。我们认为以下几条是这种方法的主要优点:
- Connect 和存储过程解决方案不需要单独的驱动程序或者到这些非 大型主机数据源的单独连接。
- 使用 存储过程的方法由 来保证非 大型主机数据源中数据的完整性,而不是将此任务委托给应用程序。这样一来,应用程序看到的就是一个统一的数据视图,而不必执行它自己的连接、过滤、排序等任务。
- 使用 存储过程的方法可以提供一种良好管理的、可控制的可用于数据访问的环境 ―― 这在大型主机领域中是必需的。对非 数据的访问完全由存储过程提供,只需通过授权对存储过程的访问,便可以授权或拒绝个人对数据的访问。大多数大型主机运营者都不大愿意接受借助用于 IMS 的 ODBC 驱动程序从 Microsoft Excel 到生产 IMS 数据库之类的即席(ad hoc)访问。此外,存储过程是在 Workload Managed (WLM) 地址空间中运行的,这样可以对资源消耗进行很好的控制和管理。
使用 SQL 函数提供异构型分布数据的统一视图
大多数程序员都熟悉数据库提供的 SQL 函数,这些 SQL 函数用于执行字符串处理,进行运算和统计计算,甚至计算地图上的位置。 附带了多达数百个内建函数。除此以外, 服务器还允许程序员创建他们自己的函数 ―― s用户定义函数(User Defined Functions, UDF) ―― 以补充产品中原有的函数。由于 Connect 服务器实际上建立在 UDB 数据库服务器基础之上,因此它也允许客户创建他们自己的函数。然而,因为 Connect 本身不存放数据,所以这些函数通常需要从其他数据源访问数据,并使这些数据作为联邦数据库的一部分提供出来。为了简化用户定义函数的创建, Connect 为四种类型的函数提供了内建的加速器:
- 用于使用 OLE DB API 连接到数据源的函数
- 用于连接到存储在文件中的 XML( 之外)的函数
- 用于连接到业界标准的 Web 服务的函数
- 用于通过 MQSeries 消息队列获得数据的函数
所有这些函数都有一个共同点:当被调用时,每个函数都返回一个结果集,这个结果集看上去像一个 表(这正是我们将其称作表函数的原因)。就像其他的内建函数一样,表函数也可以在 SQL SELECT 语句中使用。另外,这些函数还常用于定义视图,让应用程序使用视图,而不是直接使用函数。
OLE DB 是 Microsoft 的一种技术,它被嵌入在 Windows 操作中。OLE DB 的目标(就像它之前的 ODBC 的目标)是提供对各种关系和非关系数据源的透明的访问。在 Connect 的上下文中,只要有可用的 OLE DB 驱动程序(其实更恰当的名称是 provider,但由于很多人使用 driver 这个术语,因此我们在这里同时使用了这两个术语),用户编写的 UDF 便可以使用 OLE DB 接口访问任何数据源。幸运的是,对于大多数数据源(关系的和非关系的),都有可用的 OLE DB 提供程序(provider)。例如, Microsoft Data Access Components (MDAC) 提供了用于 Microsoft Access、SQL Server、文本文件和 Excel 电子表格等常见数据源的 OLE DB 驱动程序。如前所述,由于大多数供应商都为他们各自的数据源提供了 OLE DB 驱动程序,因此还有很多其他的拥有 OLE DB 驱动程序的数据源。 Connect 为 提供了 OLE DB 驱动程序 ―― 但通过内建的联邦支持提供了比 OLE DB UDF 更好的访问 数据源的方案。下面的图 6 提供了使用 OLE DB UDF 访问 OLE DB 数据源的一个例子:
图 6. 使用 Connect 中的 OLE DB 函数来访问数据
实际上,不需要编写任何代码便可以创建前面图中的 UDF(它将存储在 Microsoft Access 数据库中的数据暴露成一个视图)。它是如此的简单,所以一旦和 Development Center (我们在本系列的应用程序开发部分将会加以阐述)相结合的话,就只需要点几下鼠标了。详细的说明超出了本文的范围 ―― 但是您可以查阅 developerWorks 来了解更多信息。
OLE DB 访问很伟大(也是很必要的),但如今大多数数据并不是规规矩矩地就放在行和列之中(当我们大肆谈论关系数据库时,这一事实有时候竟被遗忘了)。虽然非关系数据的范围过于广泛,但是有必要至少简要地谈谈 Connect 和两种最流行的数据媒介:XML 和消息队列。
如前所述, Connect 包括内建的 XML 支持,并且可以访问存储在 数据库和文件中的 XML。为了访问存储在 以外的 XML 数据,您可以在 Connect 联邦数据库中创建一个 UDF。该函数将从一个文件中读取 XML 文档,然后以结构化数据输出的形式返回内容。
Connect 服务器上的 XML 函数可以辅助开发那样的 UDF。例如,db2xml.XMLVarcharFromFile、db2xml.XMLCLOBFromFile 和 db2xml.Content 这些函数都可以用于在一个 UDF 中把 XML 数据从文件读到内存。就像 OLE DB UDF 返回的数据一样,由从文件读 XML 的 UDF 返回的数据可以通过直接调用这些 UDF 来访问,或者也可以通过定义使用这些函数来实现(materialize)的视图来访问 ―― 而且,还有一个向导来帮助创建这些函数!
对存储在 for z/OS 中的 XML 的数据访问可以使用用于 for z/OS 的 XML Extender 或更常见的 SQL API 的扩展,即 SQL/XML (SQLx) 来完成。不管使用哪种方法, Connect 都可以拆分和组合 XML,根据 DTD 或 XML Schema 文档验证其合法性,使用 XSLT 引擎对其进行转换,等等。图 7 展示了一个例子,该例子使用 Connect 内建的 SQLx 函数访问 UDB for z/OS 数据库中的数据,并将语句的输出放到 XML 文件。
图 7. 使用 Connect 中的 XML 功能来处理 XML 数据 - 有多种方法可以做这件事。

当您想与其他集成数据或业务流程时,消息队列是另一个强大的工具,它可以与 Connect 一起使用。WebSphere MQSeries 目前是这个领域的市场领头羊,而 Connect 可用于使这些队列的应用达到顶峰,它可以用于写这些队列(表数据或 XML 数据),或者从中取数据并销毁它们。这种功能是独立的,与在关于存储过程的小节中描述的从大型主机上的存储过程中读和写队列不同。
对 WebSphere MQSeries 的处理是通过从 SQL 调用的 UDF 来完成。所以 Connect 使那些不知道如何编写基于 MQSeries 的应用程序的开发人员能够像对待关系表那样处理这些队列中的数据。
例如,为了执行对一个表的 select 操作并将该表的内容发布到一个 WebSphere MQSeries 消息队列,可以使用以下语句:
|
为了将队列中的内容插入到一个表中,可以输入以下命令:
|
下面的图 8 展示了这些类型的操作:
图 8. 使用 Connect 中的 WebSphere MQSeries 功能来处理数据
我们对 UDF 和 Connect 技术的讨论,以及给出的一些例子,都与读数据有关。我们展示了如何使用 OLE 接口等来读 XML 文件、消息队列和其他数据源中的数据。然而,需要指出的是,虽然读操作看上去更常用一点,但 SQL 函数还可以用于写出数据,不过使用存储过程进行更新操作是一种更自然的编程范例。
结束语
在这个关于 Connect 的系列的本部分中,我们希望您清楚地看到 Connect 服务器是一个多么强大的数据访问平台。如今有非常多的各种各样的数据源,有了 Connect 及其相关产品,您就可以充分利用您的投资,并有效地访问这些数据,而不必再次做那些培训、安装、架构等工作。
至此我们已经看到, Connect 是用于到大型主机数据库的应用程序连接的高度优化的、集成的通信子。除此以外,它还是超越 for z/OS 的一个数据访问平台 ―― 您的数据也许不在关系 数据库中。