一种P2P数据库的实现机制
来源:岁月联盟
时间:2010-08-30
1 引言
Peer-to-Peer(P2P)环境下的数据管理和共享是数据库领域的研究热点,焦点问题集中在如何使得P2P支持复杂语义数据管理功能,提供数据资源复制、索引和精确的资源定位机制。 基于P2P数据管理系统PeerDB[3],UC Berkeley大学的PIER[5],Edutella[7],Pizaa[2],这些系统不同程度实现了数据共享。PeerDB基于关键字模式映射很难做到准确性,需要过多人为管理; PIER引入名称空间(Name Space)对数据进行索引,但仅仅支持关键字精确匹配查询。Edutella利用超节点描述其辖域子节点共享资源,超节点容易成为瓶颈,不利于系统的扩展。 本文以结构化DHT P2P 网络Chord[1]作为分布式平台,探讨一种广域网环境下P2P数据库的实现机制。首先,对数据使用规则进行分割,并复制到网络中去,提高系统的可靠性和处理的并行性;为避免Hash对数据语义的破坏,利用元数据对副本进行标识、索引;最后,把这些索引元数据组成一种分层索引机制使得数据请求节点可以高效地进行资源定位。体系结构
传统分布式数据库在局域网环境下,提供全局视图使得用户可以透明地访问数据库,局部数据源之间有较高的耦合度。但是P2P数据库是基于动态广域网,并且不存在中心控制节点,要在这样的环境中提供全局视图是不现实的。P2P 数据库系统不存在全局视图,但是,提供一组映射规则和索引机制实现数据定位和数据访问。 P2P数据库是局部数据库LDB,P2P网络及协调规则三者的统一体<LDB,P2P,Coordination>,其中LDB管理局部数据,包括共享数据部分和私有数据部分;P2P网络提供Peers间的通信、路由及数据传递;协调规则由一组映射组成,协调各LDB合作为用户的请求提供数据服务。 P2P 数据库系统体系结构(如图1所示)包括四层:应用层、数据管理层、P2P网络层和局部数据库层。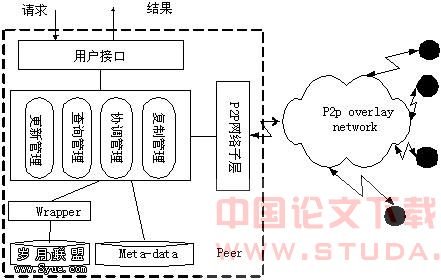 图1 P2P数据库体系结构
图1 P2P数据库体系结构3 一种P2P资源定位机制
本文主要使用数据复制和分层索引机制来保证高效的实现资源定位,并且避免了Hash对数据语义的破坏,使系统有效地保持数据语义间的联系。首先,对数据使用规则进行分割,并复制到网络中去,提高系统的可靠性和处理的并行性;为避免Hash对数据语义的破坏,利用元数据对副本进行标识、索引;最后,把这些索引元数据组成一种分层索引机制使得数据请求节点可以高效的进行资源定位。 首先把关系表进行分割,然后把这些关系表子集及其标识信息(作为元数据)复制到节点中去。基于关系子集的复制粒度,同时使用标识其定位信息,既可以保持关系表的整体性,又可以快速实现资源快速定位。系统中数据复制的粒度为关系表,或关系表的子集,具体过程如下: ①对关系R的分割要使用一些规则集合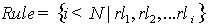 ,可以使用某一条规则把R分割为
,可以使用某一条规则把R分割为 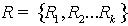 ; ②对每一个子集Ri使用
; ②对每一个子集Ri使用 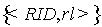 进行标识; ③把副本
进行标识; ③把副本 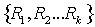 及其定位元数据复制到网络中; ④关系表
及其定位元数据复制到网络中; ④关系表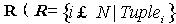 是其元组集合),对R利用规则集合
是其元组集合),对R利用规则集合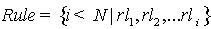 进行分割后得到一系列子集{R1,R2,…RK} (k<N)。 依据Chord路由算法,每一个节点peer可以直接与其指针表指向的节点直接通信,本文把这些节点称作该节点的Link_Peer (Link_Peer={peer,LP1,LP2,...LPm}),需要注意的是Link_Peer是包括该节点peer的。对节点peer的数据R,其副本{R1,R2,…RK}只能分布到Link_Peer上,对于特定的副本分布到Link_Peer的哪个节点上,没有特定的规定,他们的机会是均等的,可以认为是随机的。
进行分割后得到一系列子集{R1,R2,…RK} (k<N)。 依据Chord路由算法,每一个节点peer可以直接与其指针表指向的节点直接通信,本文把这些节点称作该节点的Link_Peer (Link_Peer={peer,LP1,LP2,...LPm}),需要注意的是Link_Peer是包括该节点peer的。对节点peer的数据R,其副本{R1,R2,…RK}只能分布到Link_Peer上,对于特定的副本分布到Link_Peer的哪个节点上,没有特定的规定,他们的机会是均等的,可以认为是随机的。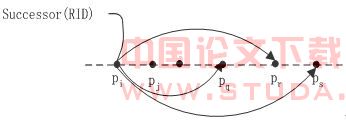 图2 元数据放置策略 LDB,RID和rl形成了一个层次状的域名空间(rl决定的数据挝RID标识的数据LDB)。这样实际上形成了一个分层索引机制,为资源定位提供了方便。
图2 元数据放置策略 LDB,RID和rl形成了一个层次状的域名空间(rl决定的数据挝RID标识的数据LDB)。这样实际上形成了一个分层索引机制,为资源定位提供了方便。3.2 资源定位
根据用户数据请求,资源定位为该请求服务定位到存储相关副本的节点,由该节点执行局部操作。由3.1节可知,数据副本定位元数据放置到Successor(RID)节点上,同一关系表有相同的RID,那么关系表R的所有副本定位元数据均存储在Successor(RID)节点上。某一特定数据请求操作具有空间局部性,这种元数据放置策略使得只需在某几个节点搜索定位元数据即可定位到存储有相关资源的节点。数据请求往往根据某些条件请求特定的数据资源,数据请求条件与关系表副本标识(副本分割规则)进行比较,以近一步缩小符合条件的副本范围,求解符合请求条件的副本。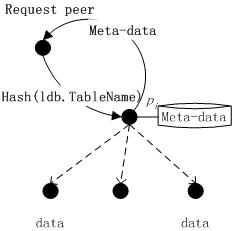 图3 资源定位 在DHT P2P中利用3.1节所述的索引机制,资源定位过程如图3所示。首先,根据关系表名出Hash(LDB.TableName)=RID,RID是分层索引的关系表标识;随后,根据P2P网络路由算法,定位到Successor(RID)节点,该节点存储了关系表LDB.TableName的定位元数据;最后,数据请求条件和关系表子集标识(也就是副本分割条件和副本标识)相比较,返回相关副本的定位元数据<LDB,RID,rl,NodeID,IP>,数据请求节点利用这些元数据可以直接定位到存储了相关副本的节点。 下面以查询处理和DHT Chord路由算法为例,说明该资源定位过程假设查询语句如下:Select a1,a2,a3 from LDB.R Where Cond1 or Cond2 在此查询语句中,需要确定LDB.R表示的副本所在的节点。步骤如下: ①Hash(LDB.R)=RID(这里我们假如等于Successor(RID) =pi); ②根据Chord路由算法定位到节点pi,节点pi存放了定位LDB.R副本所需元数据; ③查询条件Cond和分割规则rule进行比较,假如cond∩rule≠Φ,那么把该rule 对应的<LDB,RID,rl,NodeID,IP>传递给查询发起节点p;cond∩rule≠Φ说明关系表副本按cond进行分割,并且分割后形成的副本R={R1,R2,…RK}可以重构R,即 ; ④否则,把所有的副本对应的<LDB,RID,rl,NodeID,IP>传递给查询发起节点p。cond∩rule≠Φ表示关系表没有预先按cond进行分割,因此所有副本都可能和查询处理相关。在这种情况下,可以考虑使用3.1节数据复制方法进行处理。 数据资源定位实质是对Successor(RID)后继节点的元数据集进行搜索、匹配,并把搜索结果返回请求节点的过程。 本文描述了一种P2P分布式环境下的数据库的实现机制。利用数据分割和数据复制,把节点负载分散,达到系统负载均衡和提高可用性,建立一种分层索引机制使得数据请求节点可以高效的资源定位,支持复杂的查询机制。P2P分布式环境下的数据库的实现机制弥补了DHT P2P网络在管理复杂数据上的缺陷。[1] I. Stoica,R. Morris,D. Karger,M. F. Kaashoek,and H. Balakrishnan; Chord: A scalable peer-to-peer lookup service for internet applications; in Proc. SIGCOMM,San Diego,CA,Aug. 2001,pp. 149-160[2] I. Tatarinov,Z. G. Ives,J.Madhavan,A. Halevy; The Piazza Peer Data Management; ACM SIGMOD Record,Volume 32,Issue 3,September 2003,pages 47-5[3] W. Siong; Ng Beng; Chin Ooi; PeerDB: A P2P-based System for Distributed Data Sharing,Proceedings of the 19th International Conference on Data Engineering (ICDE’03) 1063-6382/03 17.00 © 2003 IEEE[4] L.G.ALEX SUNG,A Survey of Data Management in Peer- to-Peer Systems,Web Data Management,Winter 2005,Pages 1-50[5] R.H.Joseph,Querying the Internet with PIER,Proceedings of the 29th VLDB Conference,Berlin,Germany,2003[6] Roscoe,S. Shenker,I. Stoica,A. R. Yumerefendi;The Architecture of PIER: an Internet-Scale Query Processor;Proceedings of the 2005 CIDR Conference[7] W. Nejdl,B. Wolf,Changtao Qu,EDUTELLA: A P2P Networking Infrastructure Based on RDF,ACM 1581134495/ 02/0005[8] 凌 波,陆志国,黄维雄,钱卫宁,周傲英. PeerIS:基于Peer-to-Peer的信息检索系统. 2004软件学报,l.15,No.9
图3 资源定位 在DHT P2P中利用3.1节所述的索引机制,资源定位过程如图3所示。首先,根据关系表名出Hash(LDB.TableName)=RID,RID是分层索引的关系表标识;随后,根据P2P网络路由算法,定位到Successor(RID)节点,该节点存储了关系表LDB.TableName的定位元数据;最后,数据请求条件和关系表子集标识(也就是副本分割条件和副本标识)相比较,返回相关副本的定位元数据<LDB,RID,rl,NodeID,IP>,数据请求节点利用这些元数据可以直接定位到存储了相关副本的节点。 下面以查询处理和DHT Chord路由算法为例,说明该资源定位过程假设查询语句如下:Select a1,a2,a3 from LDB.R Where Cond1 or Cond2 在此查询语句中,需要确定LDB.R表示的副本所在的节点。步骤如下: ①Hash(LDB.R)=RID(这里我们假如等于Successor(RID) =pi); ②根据Chord路由算法定位到节点pi,节点pi存放了定位LDB.R副本所需元数据; ③查询条件Cond和分割规则rule进行比较,假如cond∩rule≠Φ,那么把该rule 对应的<LDB,RID,rl,NodeID,IP>传递给查询发起节点p;cond∩rule≠Φ说明关系表副本按cond进行分割,并且分割后形成的副本R={R1,R2,…RK}可以重构R,即 ; ④否则,把所有的副本对应的<LDB,RID,rl,NodeID,IP>传递给查询发起节点p。cond∩rule≠Φ表示关系表没有预先按cond进行分割,因此所有副本都可能和查询处理相关。在这种情况下,可以考虑使用3.1节数据复制方法进行处理。 数据资源定位实质是对Successor(RID)后继节点的元数据集进行搜索、匹配,并把搜索结果返回请求节点的过程。 本文描述了一种P2P分布式环境下的数据库的实现机制。利用数据分割和数据复制,把节点负载分散,达到系统负载均衡和提高可用性,建立一种分层索引机制使得数据请求节点可以高效的资源定位,支持复杂的查询机制。P2P分布式环境下的数据库的实现机制弥补了DHT P2P网络在管理复杂数据上的缺陷。[1] I. Stoica,R. Morris,D. Karger,M. F. Kaashoek,and H. Balakrishnan; Chord: A scalable peer-to-peer lookup service for internet applications; in Proc. SIGCOMM,San Diego,CA,Aug. 2001,pp. 149-160[2] I. Tatarinov,Z. G. Ives,J.Madhavan,A. Halevy; The Piazza Peer Data Management; ACM SIGMOD Record,Volume 32,Issue 3,September 2003,pages 47-5[3] W. Siong; Ng Beng; Chin Ooi; PeerDB: A P2P-based System for Distributed Data Sharing,Proceedings of the 19th International Conference on Data Engineering (ICDE’03) 1063-6382/03 17.00 © 2003 IEEE[4] L.G.ALEX SUNG,A Survey of Data Management in Peer- to-Peer Systems,Web Data Management,Winter 2005,Pages 1-50[5] R.H.Joseph,Querying the Internet with PIER,Proceedings of the 29th VLDB Conference,Berlin,Germany,2003[6] Roscoe,S. Shenker,I. Stoica,A. R. Yumerefendi;The Architecture of PIER: an Internet-Scale Query Processor;Proceedings of the 2005 CIDR Conference[7] W. Nejdl,B. Wolf,Changtao Qu,EDUTELLA: A P2P Networking Infrastructure Based on RDF,ACM 1581134495/ 02/0005[8] 凌 波,陆志国,黄维雄,钱卫宁,周傲英. PeerIS:基于Peer-to-Peer的信息检索系统. 2004软件学报,l.15,No.9
上一篇:基于纹理特征的图像分类识别