基于增量SVM的可继续学习微钙化点检测算法
来源:岁月联盟
时间:2010-08-30
1 引言
目前的乳腺癌计算机辅助诊断算法中,基于支持向量机SVM的微钙化点检测算法因为取得了较高的检出率、更低的假阳性并且形成的分类器具有更好的泛化能力[1~3],而受到了广泛的重视。人们相继提出了各种改进方法来进一步提高微钙化点检测的检出率,降低检测结果中的假阳性,以及提高检测效率。但是在诊断的过程中,由于乳腺癌病例样本个体差异性比较大,会不断出现新的病例样本,传统的方法在处理这类问题时,抛弃了的训练结果,对新样本集进行重复训练,这种方法由于样本数较多,求解二次优化使得训练算法很复杂、耗时长,影响了乳腺癌计算机辅助诊断算法的在线更新。 Syed[4]最早提出了基于支持向量机的增量学习算法。增量学习的主要任务就是利用历史训练结果尽量避免样本的重复训练,得到比较准确的分类结果,并且训练规模不太大,得到了广泛的应用[5-7]。针对乳腺癌的计算机辅助诊断中存在的新样本不断出现这一问题,本文首次提出将增量学习的思想引入微钙化点检测中,来实现对分类器的更新,以达到在线更新优化分类器的目的,缩短了软件优化的时间。2 支持向量机
SVM是基于统计学习理论的机器学习技术。在人脸识别、语音识别、手写数字识别和文本检测等问题中已经得到了广泛的应用,并且算法精度超过了传统的神经算法。在线性可分情况下,SVM算法从最优分类面而来。下面分别对线性和非线性的情况分别进行讨论。 设训练样本为 (xi,yi),i=1,…,n,x∈Rd,y∈{-1,+1}为类别标记,求解下面的二次规划问题: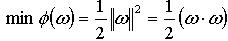 (1)
(1)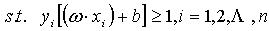 (2)得到最优分类面为超平面
(2)得到最优分类面为超平面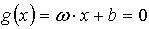 (3)利用Lagrange优化方法将上述问题转化为其对偶问题进行求解。依据优化理论的Kuhn-Tucker定理求解,得到最优分类函数为
(3)利用Lagrange优化方法将上述问题转化为其对偶问题进行求解。依据优化理论的Kuhn-Tucker定理求解,得到最优分类函数为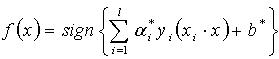 (4) 在线性不可分的情况下,在条件(2)中增加一个松驰项 。即折衷考虑最少错分样本和最大分类间隔,原问题转化为:
(4) 在线性不可分的情况下,在条件(2)中增加一个松驰项 。即折衷考虑最少错分样本和最大分类间隔,原问题转化为: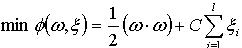 (5)
(5)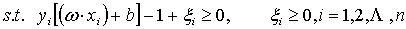 (6) 其中C>0是一个预先设定的常数,用来控制错分样本的惩罚程度。该问题的求解与线性可分情形下完全相同,只是需要条件
(6) 其中C>0是一个预先设定的常数,用来控制错分样本的惩罚程度。该问题的求解与线性可分情形下完全相同,只是需要条件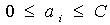 (7) 解决非线性可分的样本的分类问题正是SVM算法的一个优势。利用核函数引入隐非线性变换,将输入映射到高维特征空间,从而转化为线性可分问题。此时响应的分类函数变为
(7) 解决非线性可分的样本的分类问题正是SVM算法的一个优势。利用核函数引入隐非线性变换,将输入映射到高维特征空间,从而转化为线性可分问题。此时响应的分类函数变为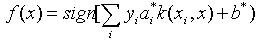 (8)这就是SVM。
(8)这就是SVM。3 增量SVM算法
当出现新的样本时,要形成新的分类器,最直接的方法就是对它们中的所有样本进行学习,这种方法是支持向量机的经典学习方法,该方法会增加运算时间和存储空间。经典的学习方法忽视了支持向量机的一个重要性质,支持向量机训练所得的决策函数仅与支持向量有关,即支持向量机在全体样本上训练和在支持向量集上训练得到的决策函数相同,历史训练的结果在经典的支持向量机学习方法完全不起作用。支持向量虽然在样本集中占很小的一部分但却完全反映了最优分类器的特征,在原样本集中支持向量集完全代表了历史样本的学习能力和泛化能力,它们在增量学习后成为支持向量的概率是相当大的,在增量样本集中错分向量对分量结果的影响最大,这些样本很可能成为支持向量,还有与最优分类器临近的,即使被正确分类的样本也有可能成为支持向量,这些向量处于间隔平面和最优超平面之间,它们主要影响支持向量机的泛化能力,当然,其它的样本也可能成为支持向量,但概率要比上述向量小得多。可继续学习的微钙化点检测算法步骤。 (1) 由原训练样本集训练得到分类器 ; (2) 对新样本其是否满足KKT条件,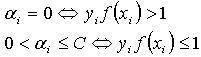 (9)若新样本满足KKT条件,则说明新样本能够被正确分类,则新样本不是支持向量;若新样本不满足KKT条件,则说明该样本有可能是支持向量; (3) 将不满足KKT条件的新样本与原分类器的支持向量一起构成新的训练样本集,重新训练得到新的分类函数。从而获得分类器的更新。
(9)若新样本满足KKT条件,则说明新样本能够被正确分类,则新样本不是支持向量;若新样本不满足KKT条件,则说明该样本有可能是支持向量; (3) 将不满足KKT条件的新样本与原分类器的支持向量一起构成新的训练样本集,重新训练得到新的分类函数。从而获得分类器的更新。4 基于增量SVM的可继续学习微钙化点检测算法及实验结果
可继续学习微钙化点检测算法原理如图1所示。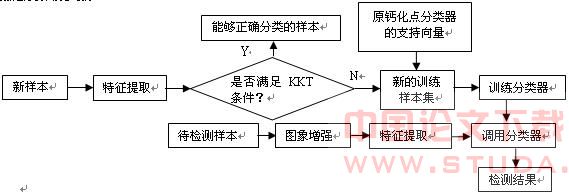
图1 可继续学习微钙化点检测算法原理框图
为了验证提出的算法,本文取360(+1类和-1类样本各180)例样本作为原有样本,另取10例作为新样本,取另外30例作为测试样本集,并同传统的将新样本加进原训练样本集重新训练的方法进行比较。实验结果如表1、表2所示。可见,本文提出的算法与传统方法具有相当的检出率,但大大缩减了训练时间。表1 训练算法比较
| 方法 | 项目 | ||
| 样本集样本数 | 支持向量个数 | 训练时间/s | |
| 传统方法 | 360+10 | 36 | 123 |
| 本文方法 | 35+10 | 36 | 27 |
| 方法 | 样本 | |||||
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 病例实际钙化点个数 | 20 | 34 | 26 | 33 | 7 | 22 |
| 传统方法 | 19 | 31 | 24 | 31 | 7 | 21 |
| 本文方法 | 20 | 33 | 25 | 32 | 7 | 22 |
5 结论
乳腺癌病例的个体差异比较大,这就导致乳腺癌的计算机辅助诊断中新样本不断出现,分类器需要不断更新,传统的方法是抛弃原来的训练结果,重新构造训练样本集,这样造成训练任务大,时间长,本文依据支持向量机分类器由支持向量决定分类函数这一特点,引入增量学习的思想,充分利用支持向量机原来的训练结果,将支持向量集与不满足KKT条件的新样本构成训练样本集,以及对更新分类器有作用的样本,大大减少了训练样本集的样本数,从而降低了训练算法的难度,减少了训练时间。实验结果表明,该算法保证了较高的检测精度,同时实现了分类器的适时更新和微钙化点的在线检测。[1] Dong Jian-xiong,zak,Ching Y. Suen.Fast SVM Training Algorithm with Decomposition on Very Large Data Sets[J]. IEEE transactions on pattern analysis machine intelligence,2005,27(4):603-618[2] 万柏坤,王瑞平,朱欣,等.SVM算法及其在乳腺X片微钙化点自动检测中的应用[J].学报,2004,32(4):587 -590[3] Liyang Wei,Yongyi Yang,M.Nishikawa Robert,et al. A Study on Several Machine-Learning Methods for Classification of Malignant and Benign Clustered Microcalcifi- cations[J]. IEEE Trans. on Medical Imaging,2005,24(3):371-380 [4] SyedN,LiuH,SungK.Incremental learning with support vector machines[A]. Proceedings of the Workshop on Support Vector Machines at the International Joint Conference of Artificial Intelligence(IJCAI-99)[C]. Stockholm,SwedenMorgan Kaufmann,1999.876-892[5] 赵宇,奚宏生,王子磊,杨坚.基于在线 SVM 的多用户检测算法及仿真.系统仿真学报[J],2006,18(1):50-53[6] 孙晋文,肖建国.基于SVM文本分类中的关键词学习研究[J]. ,2006,11[7] 朱云涛,尹怡欣,杜军平.SVM增量算法及在信息分类中的应用.,2007,3下一篇:基于纹理特征的图像分类识别