基于SVM输出概率建模的微钙化点检测算法
来源:岁月联盟
时间:2010-08-30
1 引言
支持向量机作为一种有效地学习机器在医学图像处理中得到了广泛的应用[1][2]。但是当训练样本中含有噪声与野值样本时,由支持向量机方法训练得到的分类面不是真正的最优分类面;传统的支持向量机方法在决定样本的分类类别时,只考虑两个极端情况,即属于某一类的概率为 1,或者不属于某一类的概率为 1。而医学图像在成像过程中,由于热、电燥声、磁场的不均匀性、射频线圈、局部体效应等诸多因素的影响,使医学图像中不同组织与结构之间存在混迭现象,不同区域之间难以有清晰的边界,导致一些样本不能准确地确定其类别。 在解决样本分类的不确定性时,一般对分类结果采用概率的方式输出。针对医学图像不同区域之间难以有清晰的边界,因此,分割任务常常要处理某些带有不确定性的问题,如包含几种解剖结构的混合体素的识别,以概率形式提供的信息更能接近于事物的真实情况,概率输出在医学图像分类中得到了广泛的应用[3-4]。在漫长的进化过程中,在不同的环境下,人与人之间有相当大的差别,人体解剖组织结构和形状非常地复杂,得到的训练样本仅仅是整个系统中的一个很小的子集,而其它绝大部分个体仍然处于“隐藏”状态,必须依赖概率建模来确定它们。由于个体差异性导致乳腺癌患者的乳腺X线图片具有很大不确定性,本文提出将概率输出的思想引入到微钙化点检测中,可以充分考虑新病例样本的不确定性。2 支持向量机
SVM是基于统计学习理论的机器学习技术。在人脸识别、语音识别、手写数字识别和文本检测等问题中已经得到了广泛的应用,并且算法精度超过了传统的神经算法。在线性可分情况下,SVM算法从最优分类面而来。下面分别对线性和非线性的情况进行讨论。 设训练样本为 (xi,yi),i=1,…,n,x∈Rd,y∈{-1,+1}为类别标记,求解下面的二次规划问题: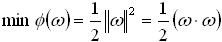 (1)
(1) 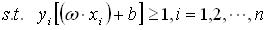 (2) 得到最优分类面为超平面:
(2) 得到最优分类面为超平面: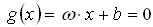 (3) 利用Lagrange优化方法将上述问题转化为其对偶问题进行求解。依据优化理论的Kuhn-Tucker定理求解,得到最优分类函数为:
(3) 利用Lagrange优化方法将上述问题转化为其对偶问题进行求解。依据优化理论的Kuhn-Tucker定理求解,得到最优分类函数为: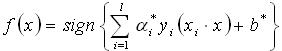 (4) 在线性不可分的情况下,在条件(2)中增加一个松弛项
(4) 在线性不可分的情况下,在条件(2)中增加一个松弛项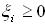 。即折衷考虑最少错分样本和最大分类间隔,原问题转化为:
。即折衷考虑最少错分样本和最大分类间隔,原问题转化为: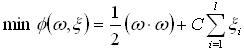 (5)
(5)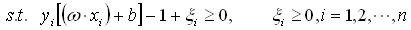 (6) 其中C >0是一个预先设定的常数,用来控制错分样本的惩罚程度。该问题的求解与线性可分情形下完全相同,只是需要条件:
(6) 其中C >0是一个预先设定的常数,用来控制错分样本的惩罚程度。该问题的求解与线性可分情形下完全相同,只是需要条件: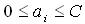 (7) 解决非线性可分的样本的分类问题正是SVM算法的一个优势。利用核函数引入隐非线性变换,将输入映射到高维特征空间,从而转化为线性可分问题。此时响应的分类函数变为:
(7) 解决非线性可分的样本的分类问题正是SVM算法的一个优势。利用核函数引入隐非线性变换,将输入映射到高维特征空间,从而转化为线性可分问题。此时响应的分类函数变为: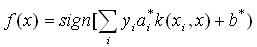 (8) 这就是SVM。
(8) 这就是SVM。3 输出概率建模
[5]提出了一种输出概率建模方法,本文提出将输出的后验概率作为衡量样本属于所分类别的可能性大小。由上述SVM的基本理论可知,支持向量机的标准输出为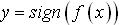 ,其中
,其中 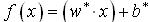 。在计算过程中需要对样本进行归一化,即对于离分类面最近的样本点(支持向量)满足:
。在计算过程中需要对样本进行归一化,即对于离分类面最近的样本点(支持向量)满足: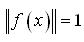 (9) 显然在分类面上的样本点,
(9) 显然在分类面上的样本点,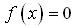 (10) 对于其它样本点,
(10) 对于其它样本点,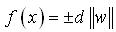 (11) 上式中d表示样本点x到分类面之间的距离,正负号表示该样本点在分类面的两侧,则任意样本点x到分类面之间的距离为:
(11) 上式中d表示样本点x到分类面之间的距离,正负号表示该样本点在分类面的两侧,则任意样本点x到分类面之间的距离为: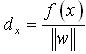 (12) 支持向量到分类面之间的距离为:
(12) 支持向量到分类面之间的距离为: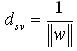 (13) 从支持向量机的分类超平面的几何角度看,可以通过样本与最优分类面之间的远近来定量地评价二类分类问题中样本属于所在类程度的大小。由式(12)、(13)可以看出,f(x)是dx 与dsv 的比率,可以通过支持向量机方法的标准输出f(x)来度量样本的后验概率。因此,在对支持向量机方法的概率建模时,可以通过支持向量方法的标准输出f(x)建立与参数拟合模型之间的关系。 通过支持向量机方法的标准输出f(x)建立与参数拟合模型直接的关系后,需要确定参数拟合模型。本文采用[6]中使用 Sigmoid 函数来作为直接拟合后验概率的参数拟合模型。在两类分类问题中,采用 Sigmoid 函数给出支持向量机的概率输出形式为:
(13) 从支持向量机的分类超平面的几何角度看,可以通过样本与最优分类面之间的远近来定量地评价二类分类问题中样本属于所在类程度的大小。由式(12)、(13)可以看出,f(x)是dx 与dsv 的比率,可以通过支持向量机方法的标准输出f(x)来度量样本的后验概率。因此,在对支持向量机方法的概率建模时,可以通过支持向量方法的标准输出f(x)建立与参数拟合模型之间的关系。 通过支持向量机方法的标准输出f(x)建立与参数拟合模型直接的关系后,需要确定参数拟合模型。本文采用[6]中使用 Sigmoid 函数来作为直接拟合后验概率的参数拟合模型。在两类分类问题中,采用 Sigmoid 函数给出支持向量机的概率输出形式为: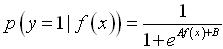 (14)
(14)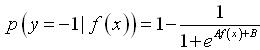 (15) 其中,参数 A 与 B 控制 Sigmoid 函数的形态,f(x)为支持向量机中样本x的输出值。
(15) 其中,参数 A 与 B 控制 Sigmoid 函数的形态,f(x)为支持向量机中样本x的输出值。4 基于输出概率建模的SVM微钙化点检测算法及实验结果
基于概率输出SVM的为钙化点检测算法原理框图如图1所示。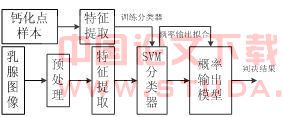 图1 基于概率输出SVM的为钙化点检测算法原理框图 为了验证提出的算法,本文取360(+1类和-1类样本各180)例样本作为原有样本,另取10例作为测试样本集,并同传统的SVM方法进行比较。实验结果如表1所示。可见,本文提出的算法与传统方法相比具有相对较高的检出率和假阳性(非钙化点被误判为钙化点的比率)。
图1 基于概率输出SVM的为钙化点检测算法原理框图 为了验证提出的算法,本文取360(+1类和-1类样本各180)例样本作为原有样本,另取10例作为测试样本集,并同传统的SVM方法进行比较。实验结果如表1所示。可见,本文提出的算法与传统方法相比具有相对较高的检出率和假阳性(非钙化点被误判为钙化点的比率)。表1 10例样本的检测结果比较
| 方法 | 样本 | |||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| 病例实际钙化点个数 | 7 | 11 | 5 | 34 | 8 | 22 | 3 | 13 | 17 | 14 |
| 传统SVM方法 | 8 | 10 | 6 | 36 | 11 | 21 | 5 | 15 | 20 | 17 |
| 本文方法 | 7 | 11 | 5 | 33 | 9 | 22 | 5 | 12 | 18 | 16 |
表2 检出率与假阳性比较
| 传统SVM方法 | 本文方法 | |
| 检出率(%) | 96.4 | 97.1 |
| 假阳性(%) | 25.1 | 21.2 |