FP-Growth关联算法应用研究
来源:岁月联盟
时间:2010-08-30
1 引言
关联规则(Association Rules)挖掘是数据挖掘研究领域的一个重要研究方向,它由美国IBM Almaden Research Center 的Rakesh A-Grawal等人于1993年首先提出,是描述数据库中数据项之间存在的一些潜在关系的规则。 设I = {I1,I2,…,Im}是项的集合,D = {T1,T2,…,Tn}是一个事务数据库,其中每个事务T是项的集合,使得T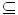 I。每个事务有一个标识符,称为TID。如果I的一个子集X满足XT,则称事务T包含项目集X。一个关联规则就是形如X=Y的蕴涵式,XI、YI、X∩Y=
I。每个事务有一个标识符,称为TID。如果I的一个子集X满足XT,则称事务T包含项目集X。一个关联规则就是形如X=Y的蕴涵式,XI、YI、X∩Y= 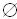 。 规则X Y在交易数据库中的支持度(support)就是交易集中包含X和Y的交易数与所有交易数之比,记为support (X Y),即support(X Y)=┃{T:X∪Y T,T D}┃/┃D┃。 规则X=Y在交易数据库中的置信度(confidence)是指包含X和Y的交易数与包含X的交易数之比,记为confidence(X=Y),即confidence(X=Y)= ┃{T:X∪Y T,T∈D}┃/┃{T:X T, T ∈D }┃。 支持度和置信度是描述关联规则的两个重要概念,前者用于衡量关联规则在整个数据集中的统计重要性,后者用于衡量关联规则的可信程度。一般来说,只有支持率和置信度均较高的关联规则才可能是用户感兴趣、有用的关联规则。 关联规则的挖掘是一个两步的过程: (1)找出所有的频繁项集:根据定义,这些项集出现的频繁性至少等于预定义的最小支持度计数。 (2)由频繁项集产生强关联规则:根据定义,这些规则必须满足最小支持度和最小置信度。 在以上两个步骤中,第二步较容易,挖掘关联规则的总体性能由第一步决定。
。 规则X Y在交易数据库中的支持度(support)就是交易集中包含X和Y的交易数与所有交易数之比,记为support (X Y),即support(X Y)=┃{T:X∪Y T,T D}┃/┃D┃。 规则X=Y在交易数据库中的置信度(confidence)是指包含X和Y的交易数与包含X的交易数之比,记为confidence(X=Y),即confidence(X=Y)= ┃{T:X∪Y T,T∈D}┃/┃{T:X T, T ∈D }┃。 支持度和置信度是描述关联规则的两个重要概念,前者用于衡量关联规则在整个数据集中的统计重要性,后者用于衡量关联规则的可信程度。一般来说,只有支持率和置信度均较高的关联规则才可能是用户感兴趣、有用的关联规则。 关联规则的挖掘是一个两步的过程: (1)找出所有的频繁项集:根据定义,这些项集出现的频繁性至少等于预定义的最小支持度计数。 (2)由频繁项集产生强关联规则:根据定义,这些规则必须满足最小支持度和最小置信度。 在以上两个步骤中,第二步较容易,挖掘关联规则的总体性能由第一步决定。分析
针对经典关联Apriori算法的固有缺陷,产生了候选挖掘频繁项集的方法—FP-Growth算法。FP-Growth算法采用分而治之的策略,在经过第一遍扫描之后,把数据库中的频繁项集压缩到一棵频繁模式树(FP-Tree),同时依然保留其中的关联信息,随后再将FP-Tree分化成一些条件数据库,每个条件数据关联一个频繁项,然后再分别对这些条件库进行挖掘。FP-Growth算法将发现长频繁模式的问题转换为递归地发现一些短模式,然后连接后缀。它使用最不频繁的项作为后缀,提供了好的选择性。FP-Growth算法核心思想如下所示: 输入:事务数据库D;最小支持度阈值min_sup。 输出:频繁模式的完全集。 方法: (1)构造FP-Tree。 ①扫描事务数据库D一次。收集频繁项的集合F和它们的支持度。对F按支持度降序排序,结果为频繁项表L。 ②创建FP-Tree的根节点,以“NULL”标记它。对于D中每个事务Trans,执行:选择Trans的频繁项,并按照L中的次序排序。设排序后的频繁项表为[p|P],其中p是第一个元素,而P是剩余元素的表。调用insert_tree([p|P],T)。该过程执行过程如下:如果T有子女N使得N.item-name= p.item-name,则N的计数增加1,否则创建一个新节点N,将其计数设置为1,链接到它的父节点T,并且通过节点链结构将其链接到具有相同item-name的节点。如果P非空,递归地调用insert_tree(P,N)。 (2)通过调用FP-Growth(FP-Tree,null)实现FP-Tree的挖掘。该过程实现如下: Procedure FP-Growth(Tree,α) ①if Tree 含单个路径P then ②for 路径P中节点的每个组合(记作β) ③产生模式β∪α,其支持度support = β中节点的最小支持度; ④else for each αi在Tree的头部{ ⑤产生一个模式β = αi∪α,其支持度support =αi. support; ⑥构造β的条件模式基,然后构造β的条件FP-Treeβ; ⑦if Treeβ≠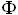 then ⑧调用FP-Growth(Treeβ,β);} 对FP-Tree方法的性能研究表明:对于挖掘长和短的频繁模式,它都是有效和可伸缩的,并且比Apriori方法快了1个数量级。
then ⑧调用FP-Growth(Treeβ,β);} 对FP-Tree方法的性能研究表明:对于挖掘长和短的频繁模式,它都是有效和可伸缩的,并且比Apriori方法快了1个数量级。4 应用实现
本文主要是将FP-Growth算法应用到我校学生成绩数据库中,在学生成绩聚类的基础上对学生成绩的聚类簇与学生的内外部因素进行关联分析。4.1 关联分析目标
目前我校面对的教务处学生成绩数据库是一个多维的关系数据库,我们急切需要从这些海量数据中发现潜在的有用信息来帮助教学部门掌握更多的学生信息。基于此,根据学生的成绩信息对学生聚类,这些聚类信息反映了学生学习成绩的升降起伏等学习情况,结合学生的聚类信息与学生因素调查表信息,采用关联挖掘技术分析每一类学生的学生成绩与其内外部因素间的关联信息,进而分析得到影响学生学习的因素。4.2 算法实现
定义频繁节点结构,用以构造频繁一次项的降序排列typedef struct ItemCode //Sort Item{ int Count; //频繁度 int Position; //排序位置 ItemCode *Next; //下一个节点的地址 CString Data; //节点值}ItemCode;ItemCode * GetItem(CString TableName, int Support, int Number, int CluNum); //由数据库得到未排序频繁一项集节点链,并返回首节点;void GetSortItem(ItemCode * pHeadItem); //对频繁一项集排序;void CreateFPTree(CString TableName, CTreeCtrl & TempTree, CTreeCtrl & TreeCopy, bool Sort, int Number, int CluNum); //按照频繁项排序建立FP-Tree;void GetFPItem(CTreeCtrl & TempTree,CListBox & LBox, int Support, int Number, int CluNum); //按Support的支持度对TempTree的FP-Tree进行关联分析,得到频繁项显示在LBox;void SaveResultToDB(); //保存频繁项集结果到数据库;void ComputeAssociate(int Number, int CluNum); //关联结果的相关分析值;void ShowInChart(CActiveFrmChart & Chart, int Number, int CluNum, int Index); //将挖掘结果显示在Chart中;4.3 挖掘结果
为了深入了解学生所处的内外部因素对学生成绩的影响,将分别对每个簇的学生所处的内外部因素进行关联挖掘,以获取每个簇学生所处内外部因素间的关联关系,分别对每个簇学生的内外部因素采用FP-Growth改进算法进行关联挖掘,因为支持度计数是与问题域相关的,用户可选择不同的支持度计数实验,我们在这里支持度计数选取为5。 部分簇构造FP-Tree如图1所示,因篇幅有限,只列举有代表意义的关联项。