Linux高可用性方案之Heartbeat的CRM节点得分计算
crm资源得分概述
在V2的Heartbeat中,为了将资源的监控和切换结合起来,同时支持多节点集群,Heartbeat提供了一种积分策略来控制各个资源在集群中各节点之间的切换策略。通过该积分机制,计算出各节点的的总分数, 得分最高者将成为active状态来管理某个(或某组)资源。
如果在CIB的配置文件中不做出任何配置的话,那么每一个资源的初始分数(resource-stickiness)都会是默认的0,而且每一个资源在每次失败之后所减掉的分数(resource-failure-stickiness)也是0。如此的话,一个资源不论他失败多少次,heartbeat都只是执行restart操作,不会进行节点切换。一般来说,resource-stickiness的值都是正数,resource-failure-stickiness的值都是负数。另外还有一个特殊值那就是正无穷大(INFINITY)和负无穷大 (-INFINITY)。如果节点的分数为负分,那么不管什么情况发生,该节点都不会接管资源(冷备节点)。随着资源的各种状态的发生,在各节点上面的分数就会发生变化,随着分数的变化,一旦某节点的分数大于当前运行该资源的节点的分数之后,heartbeat就会做出切换动作,现在运行该资源的节点将释 放资源,分数高出的节点将接管该资源。
资源得分配置
在CIB的配置中,可以给每个资源定义一个分数,通过resource-stickiness来设置,同样也可以设置一个失败后丢失的分数,通过resource-failure-stickiness来设置。如下:
<primitive id=”mysql_db” class=”ocf” type=”mysql” provider=”heartbeat”>
<meta_attributes id=”mysql_db_meta_attr”>
<attributes>
<nvpair name=”resource_stickiness” id=”mysql_db_meta_attr_1″ value=”100″/>
<nvpair name=”resource_failure_stickiness” id=”mysql_db_meta_attr_2″ value=”-100″/>
</attributes>
</meta_attributes>
…
<primitive />
上面的配置就是给mysql_db这个resource配置了两个分数,成功运行的时候所得到的分数(resource_stickiness)和 运行失败会丢失的分数(resource_failure_stickiness),两项分数值一样多,成功则得100分,失败则-100分。
除了可以通过给每个资源单独设置两项的分数之外,也可以将所有的resource设置成相同的分数,如下:
<configuration>
<crm_config>
<cluster_property_set id=”cib-bootstrap-options”>
<attributes>
…
<nvpair id=”default-resource-failure-stickiness” name=”default-resource-failure-stickiness” value=”-100″/>
<nvpair id=”default-resource-stickiness” name=”default-resource-stickiness” value=”100″/>
…
</attributes>
</cluster_property_set>
</crm_config>
在这个配置中,就是给所有资源设置了两个默认的分数,省去单独每个资源都设置的麻烦。当然,如果在设置了这个default分数之后,同时也给部分或者全部资源也设置了这两个分数的话,将取单独设置的各个资源设置的分数而不取默认分数。
除了资源的分数之外,节点自身同样也有分数。节点分数可以如下设置:
<constraints>
<rsc_location id=”rsc_location_group_mysql” rsc=”group_mysql”>
<rule id=”mysql1_group_mysql” score=”200″>
<expression id=”mysql1_group_mysql_expr” attribute=”#uname” operation=”eq” value=”mysql1″/>
</rule>
<rule id=”mysql2_group_mysql” score=”150″>
<expression id=”mysql2_group_mysql_expr” attribute=”#uname” operation=”eq” value=”mysql2″/>
</rule>
</rsc_location>
</constraints>
注意这里节点分数的设置是放在configuration配置项里面的constraints配置项下的,通过rule来设置。这里是通过节点主机 名来匹配的(实际上heartbeat的很多配置中对主机名都是很敏感的)。这里的value值就是节点的主机名,rule里面的score就是一个节点的分数。
节点分数计算规则
在CRM的配置当中,节点通过如下规则计算得分
Score= node+resource+failcount*failure
当HB发现NODE资源无法获取或发生切换时,会减去之前赋给该NODE的"成功分:default-resource-stickiness"
当HB发生NODE资源失败时,会给该NODE加上"失败分:default-resource-failure-stickiness"
当HB的资源成功在NODE上START,那么会给该NODE加上"成功分:default-resource-stickiness"
单资源组单资源的得分计算
通过上面的配置,我们可以作出如下计算:
a、在最开始,两边同时启动heartbeat的话,两边都没有开始运行这个resource,resource本身没有分数,那么仅仅计算节点的分数:
mysql1的分数:node+resource+failcount*failure=200+0+(0*(-100))=200
mysql2的分数:node+resource+failcount*failure=150+0+(0*(-100))=150
heartbeat会做出选择在mysql1上面运行mysql_db这个资源,然后mysql1的分数发生变化了,因为有资源自身的分数加入了:
mysql1的分数:node+resource+failcount*failure=200+100+(0*(-100))=300
mysql2的分数:node+resource+failcount*failure=150+0+(0*(-100))=150
b、过了一段时间,heartbeat的monitor发现mysql_db这个资源crash(或者其他问题)了,分数马上会发生变化,如下:
mysql1的分数:node+resource+failcount*failure=200+100+(1*(-100))=200
mysql2的分数:node+resource+failcount*failure=150+0+(0*(-100))=150
heartbeat发现mysql1节点的分数还是比mysql2的高,那么资源不发生迁移,将执行restart类操作。
c、继续运行一段时间发现又有问题(或者是b后面restart没有起来)了,分数又发生变化了:
mysql1的分数:node+resource+failcount*failure=200+100+(2*(-100))=100
mysql2的分数:node+resource+failcount*failure=150+0+(0*(-100))=150
这时候heartbeat发现mysql2节点比mysql1节点的分数高了,资源将发生迁移切换,mysql1释mysql_db相关资源,mysql2接管相关资源,并在mysql2上运行mysql_db这个资源。这时候,节点的分数又会发生变化如下:
mysql1的分数:node+resource+failcount*failure- resource =200+100+(2*(-100))-100=0
mysql2的分数:node+resource+failcount*failure=150+100+(0*(-100))=250
这时候如果在mysql2上面三次出现问题,那么mysql2的分数将变成-50,又比mysql1少了,资源将迁移回mysql1,mysql1 的分数将变成100,而mysql2的分数将变成-150,因为又少了资源所有者的那100分。到这里,mysql2节点的分数已经是负数了。 heartbeat还有一个规则,就是资源永远都不会迁移到一个分数分数是负数的节点上面去。也就是说从这以后,mysql1节点上面不管 mysql_db这个资源失败多少次,不管这个资源出现什么问题,都不会迁移回mysql2节点了。一个节点的分数会在该节点的heartbeat重启之 后被重置为初始状态。或者通过相关命令来对集群中某个节点的某个资源或者资源组来重置或者查看其failcount,如下:
#crm_failcount -G -U mysql1 -r mysql_db #将查看mysql1节点上面的mysql_db这个资源的failcount
#crm_failcount -D -U mysql1 -r mysql_db #将重置mysql1节点上面的mysql_db这个资源的failcount
当然,在实际应用中,我们一般都是将某一些互相关联的资源放到一起组成一个资源组,一旦资源组中某资源有问题的时候,需要迁移整个资源组的资源。这个和上面针对单个资源的情况实际上没有太多区别,只需要将上面mysql_db的设置换到资源组即可,如下:
<group id=”group-mysql”>
<meta_attributes id=”group-mysql_meta_attr”>
<attributes>
<nvpair id=”group-mysql_meta_attr-1″ name=”resource_stickiness” value=”100″/>
<nvpair id=”group-mysql_meta_attr-1″ name=”resource_failure_stickiness” value=”-100″/>
</attributes>
</meta_attributes>
<primitive>
...
</primitive>
...
</group>
这样,在该资源组中任何一个资源出现问题之后,都会被认为该资源组有问题,当分数低于其他节点出现切换的时候就是整个资源组的切换。
另外,对于INFINITY和-INFINITY这两个值,实际上主要用途就是为了控制永远不切换和只要失败必须切换用的。因为代表的意思就是拥有正无穷大的分数和失败就到负无穷大,主要用来满足极端规则的简单配置项。
总的来说,一项资源(或者资源组)在一个节点运行迁移到另一个节点之前,可以失败的次数的计算公式可以如下表示:
(nodeA score - nodeB score + stickiness)/abs(failure stickiness),即为A节点分数减去B节点分数,再加上资源运行分数后得到的总分数,除以资源失败分数的绝对值。
多资源组单资源的得分计算
上述的积分计算只适用域资源组内只有一个资源且只有一个资源组的情况下面的表格列举了,每个资源组里存在一个资源的积分计算过程
default-resource-stickiness=100 default-resource-failure-stickiness=-101
mysql4.ipaddr.score=350 mysql3.ipaddr.score=400
mysql4.mysql.score=350 mysql3.mysql.score=400
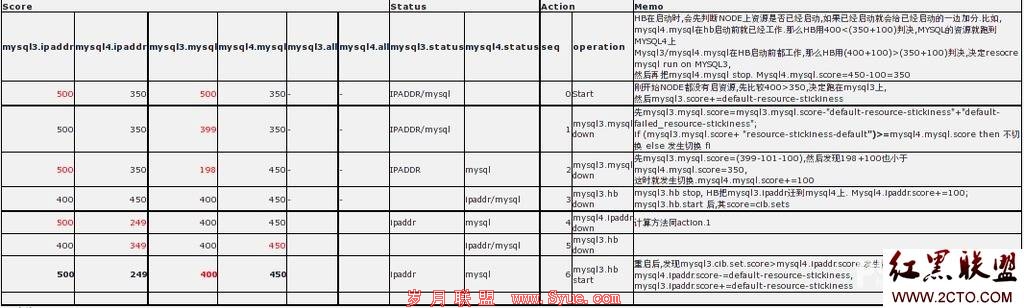
可以看出,资源组内的资源得分计算是相对独立的,但是资源是否切换依旧依据资源组与资源组之间的分数总和进行判断。
多资源组多资源的得分计算
资源要切换不再以单个资源的分数来比较. 而是以该资源组的N个资源SCORE之和,我们下面称它为
NodeX.all.score=mysqlX.resource1.score+ .... + mysqlX.resourceN.score
1.当HB发现NodeX上的资源失败或发生切换时,会减去之前赋给该NODE的"成功分:N*default-resource-stickiness",
NodeX.resourceY.score -= N * default-resource-stickiness
NodeX.all.score = NodeX.resource1.score + ...... + NodeX.resource2.score
2.当HB发生NodeX资源失败时,会给该NODE加上"失败分:default-resource-failure-stickiness"
NodeX.resourceY.score += default-resource-failure-stickiness
NodeX.all.score = NodeX.resource1.score + ...... + NodeX.resource2.score
3.当HB的资源成功在NODE上START,那么会给该NodeX加上"成功分:N*default-resource-stickiness"
NodeX.resourceY.score += N * default-resource-stickiness
NodeX.all.score = NodeX.resource1.score + ...... + NodeX.resource2.score
例1
default-resource-stickiness=100 default-resource-failure-stickiness=-100
mysql4.ipaddr.score=150 mysql3.ipaddr.score=200
mysql4.mysql.score=350 mysql3.mysql.score=400

例2
default-resource-stickiness=0 default-resource-failure-stickiness=-100
mysql4.ipaddr.score=375 mysql3.ipaddr.score=400
mysql4.mysql.score=775 mysql3.mysql.score=800
这样配,只要任何一个资源DOWN,那么资源就往对方切换。可以一直回来切换.直到分数为负数。但是,如果一台机器重启了,那么重启后会接管资源,因为他的SCORE比较高。

例3
default-resource-stickiness=5 default-resource-failure-stickiness=-23
mysql4.ipaddr.score=99 mysql3.ipaddr.score=100
mysql4.mysql.score=99 mysql3.mysql.score=100
这样的配置,如果每次在切换后,把失败NODE的HB重启,或者分数置到CIB.SET. 那么,可以一直来回切换.不然: 第一次,只要有任何一个资源失败,就发生切换. 第二次,需要有两次资源失败,才会发生切换.

配置了colocation的资源得分
在cib.xml文件中进行如下配置
<configuration>
...
<constraints>
...
<rsc_colocation id="colocation1" to="IPaddr_10_2_225_225" from="mysql" score="INFINITY" symmetrical="true">
</rsc_colocation> </constraints>
</configuration>
资源要切换不再以单个资源的分数来比较. 而是以该NODE的N个资源SCORE之和,再乘N,我们下面称它为
NodeX.all.score= (mysqlX.resource1.score+ .... + mysqlX.resourceN.score) *N
1)当HB发生NodeX资源失败时,会给该NODE
NodeX.resourceN.score += default-resource-failure-stickiness
NodeX.resourceN.score -= default-resource-stickiness
NodeX.resourceN.score += default-resource-stickiness
NodeX.all.score = (NodeX.resource1.score + ...... + NodeX.resourceN.score)* N
然后多个NODE之间比较NodeX.all.score
2)当HB发现NodeX上资源发生切换到"NodeY" 时,会减去之前赋给该NODE的"成功分:default-resource-stickiness",
NodeX.resource[1..N].score -= default-resource-stickiness
NodeY.resource[1..N].score += default-resource-stickiness
NodeX.all.score = NodeX.resource1.score + ...... + NodeX.resourceN.score
NodeY.all.score = NodeY.resource1.score + ...... + NodeY.resourceN.score
例:
<rsc_colocation id="colocation1" from="IPaddr_10_2_225_225" to="mysql" score="INFINITY" symmetrical="true">
default-resource-stickiness=5 default-resource-failure-stickiness=-1 5
mysql4.ipaddr.score=100 mysql3.ipaddr.score=100
mysql4.mysql.score=100 mysql3.mysql.score=10 1

作者“CzmMiao的博客生活”