摘要 该文提出了一种新的决策表连续属性离散化算法.首先使用相对熵来度量条件属性的重要性,并据此对条件属性按照属性重要性从小到大排序,然后按排序后的顺序,考察每个条件属性的所有断点,将冗余的断点去掉,从而将条件属性离散化. 该算法易于理解,简单, 算法的时间复杂性为O(3kn
2)。
关键词 相对熵;互信息;连续属性;离散化;决策表
1 引言 波兰家Pawlak提出的粗糙集(Rough set)理论
[1,2]是一种新型的处理模糊和不确定知识的数学工具,目前已经在人工智能、知识与数据发现、模式识别与分类、故障检测等方面得到了较为成功的应用。 在运用粗糙集理论处理决策表时,要求决策表中的值用离散数据表示.如果某些条件属性或决策属性的值域为连续值(如浮点数),则在处理前必须进行离散化处理,而且即使对于离散数据,有时也需要通过将离散值进行合并(抽象)得到更高抽象层次的离散值
[2]。该文形式化地描述了决策表的离散化问题,利用相对熵定义了属性的重要性度量,提出了基于相对熵的决策表离散化算法,并分析了该算法的时间复杂度,最后用例子说明该算法的离散化过程。
2 基本概念 应用粗糙集理论实现知识获取和数据分析通常是对决策表进行处理,为此首先给出决策表的定义. 定义1. 一个决策表是一个由四元组
T=(U,R,V,f)构成的知识表达系统,其中U是对象的集合,也称为论域.R=C∪D是属性的集合,子集C和D分别被称为条件属性集和决策属性集.
V =
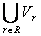
是属性的取值范围构成的集合,其中V
r是属性r的值域.f:U×R→V是信息函数,它指定U中每一个对象各个属性的取值.D≠Φ. 在本文讨论中假设决策属性值为离散值,连续属性变量仅出现在条件属性中,不失一般性,以下仅考虑单个决策属性的决策表。2.1离散化问题的描述 设
T=(U,R,V,f)是一个决策表,其中
U={x
1,x
2,…,x
n}为论域,R=C∪{d},
C ={C1 , C2,…,Ck} 为条件属性集合|C|=k
,{d}为决策属性,设决策种类的个数为r(d)。属性
a的值域
Va =[l a,ra]上的一个断点可记为
(a,c) ,其中
a∈
R,c为实数值。在
Va=[la ,ra]上的任意一个断点集合:
Da ={(a,c1a),(a,c2a),…,(a ,ckaa)}定义了
Va上的一个分类
Pa :
Pa ={[c0a,c1a),[c1a,c2a),…,[ckaa,cka+1a]}la = c0a<c1a<c2a<… < cka +1a= ra Va =[c0a,c1a]∪[c1a,c2a]∪…∪[ckaa,cka+1a] 断点集合
Da将属性a的取值分成ka+1个等价类,这里每一个c
ka就称为一个断点,离散化的目的就是对所有连续属性都找到适宜的断点集, 因此
,任意的
P =
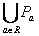
定义了一个新的决策表: T
p=(U,R,V
p,f
p),
f p(xa)=i 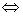 f(xa)∈[cia,ci+1a]
f(xa)∈[cia,ci+1a] 对于
x∈U,
i∈{0,1,2,…,Ka},即经过离散化之后,原来的决策表被新的决策表所代替
,且不同的断点集将同一决策表转换成不同的新决策表。 从粗糙集的观点看
,离散化的实质是在保持决策表分类能力不变
,即条件属性和决策属性相对关系不变的条件下
,寻找合适的分割点集
,对条件属性构成的空间进行划分。评价属性离散化的质量
,主要看分割点的选择和多少
,以及保持信息系统所表达的样本之间的“不可分辨关系”。最优离散化
, 即为决策表寻找最小(最优)
的断点集是一个NP-hard 问题,为此必须寻找某种启发式算法,人们提出了许多启发式算法,可[2,3],该文利用决策属性相对于条件属性的相对熵作为启发式算法。2.2 知识的信息量和相对熵 下面将信息论中信息量和相对熵
[4-6]的概念引入到信息系统中。 定义2
[5,6] 设K=(U,R)是一近似空间,R在U上的划分(等价关系)为
U/IND(R) ={R1,R2,…,Rn}, 知识(属性集合)
R 的信息量(也称为信息熵)定义为:
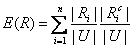
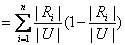 ;
; 其中 =U-R
i,|R
i|/|U|表示等价类R
i在论域U上的可能性(概率),|
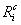
|/|U|表示R
i的余集在论域U上的可能性, 也即不属于R
i的概率。定义3
[6] 设U为论域,K
1=(U,P)和K
2=(U,Q)是关于U的两个知识库,
U/IND(P)= {X1,X2,…,Xn}, U/IND(Q)={Y1,Y2,…,Ym}, 知识(属性集合)
Q相对于知识(属性集合)
P 的相对熵
E(Q|
P)定义为:
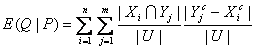
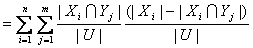
P与Q的互信息定义为:
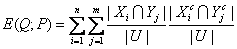
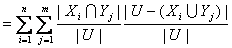
定义中用“相对熵”概念,而不用“条件熵”,完全是式子中已经没有了条件概率的意义.另外,定义中使用余集来表示,纯粹是为了定理的证明时简便,实际计算时不必用余集. 性质1
[6] 设U为论域,K
1=(U,P)和K
2=(U,Q)是关于U的两个知识库,则有:
(1) E(Q)=E(Q;P)+E(Q|P) (2) E(P)=E(P;Q)+E(P|Q) (3) E(Q;P)= E(P;Q)性质2
[6] 设U为论域,K
1=(U,P)和K
2=(U,Q)是关于U的两个知识库,
U/IND(P)= {X1,X2,…,Xn}, U/IND(Q)={Y1,Y2,…,Ym}, D是U上的一个决策(即U上的一个划分).如果
U/IND(P) 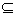 U/IND(Q)
U/IND(Q),则(1)
E(D;P)≥E(D;Q) , (2)E(D|P)≤E(D|Q)2.3 属性重要性度量 Rough集理论认为知识是将对象进行分类的能力,属性的重要性是建立在属性的分类能力上的
, 为了衡量属性的重要性程度
, 可从表中删除这一属性
,再来考察信息系统的分类会产生怎样的变化:如果去掉属性会相应地改变分类
,则说明该属性重要
,反之
,则说明该属性的重要性低。衡量属性重要性程度的方法较多,有代数方法和信息论方法等
[7],本文利用条件属性相对于决策属性的相对熵作为度量方法,有关相对熵的一些性质参见文献[6].定义4
(属性重要性) 设
T =〈
U,
C∪
D,
V,
f 〉是一个决策表
, B C ,则对任意属性
a∈
{C-
B}的相对于决策属性
D的重要性
SGF(a,B,D)定义为:
SGF(a,B,D)=E(D|B)- E(D|B∪{a})当
B =
Φ时
,简记为
SGF(a,D) =
E(D)-
E(D|{a})=E(D;a),则为
a与
D的“互信息”。上述定义表明属性
a∈
C-
B关于属性集
B对决策属性
D的重要性由
B中添加
{a}后所引起的相对熵的变化大小来度量。
SGF(a,B,D)的值愈大,说明属性
a∈
C-
B关于属性集
B 对决策属性
D愈重要。3 决策表连续属性的离散化 在开始之前首先介绍一下断点的概念,断点是将某个数值型属性的值按照由小到大的顺序排序,重复的数值只计一次,两个相邻属性值的均值称为一个断点。在离散化之前需要先生成每个条件属性的断点集。3.1 离散化算法输入:一个决策表T=(U,A∪{d},V, f), 其中U={x
1,x
2,…,x
n},A
={a1 ,a2,…,ak}输出:离散化的决策表。Step1: 初始化候选断点集,令CUT=
{ Ca1,Ca2,…,Cak },其中
Caj为属性
ai的候选断点集Step2: 根据条件属性的重要性由小到大对每个条件属性
ai (i=1,2,… ,k) 进行排序,在值相同的情形下,按条件属性断点个数从多到少进行排序,属性重要性按如下步骤产生:a) 令B=Φ是一链表,用来存储已排过序的属性;b) 对A-B中的每一个属性p,根据定义7计算其重要性
SGF(p,B,D);c) 选择使
SGF(p,B,D)最大的属性(当同时有两个以上的属性达到最大值时,选取断点个数最少的),假设是p,则将p插入到B的头部。如果|A|=|B|,转step;否则,转b);Step3: 对每个属性
aj ∈A 进行下面的过程:Step4: 对属性
aj 中的每一个断点c
j ,考虑它的存在性,把决策表中与c
j 相邻的两个属性值的较小值改为较大值,如果决策表不引起冲突,则
Caj = Caj /{cj} ;否则,把修改过的属性值还原。Step5:此时
CUT={ Ca1,Ca2,…,Cak }即为所求的断点集,同时得到离散化后的决策表。 该算法判定每一个断点存在的必要性,去掉冗余的断点,简化了决策表,易于生成更一般的决策规则.由于离散化过程始终不改变决策表的不可分辩关系,因此算法得到的新决策表仍然是一致的.由于断点的判定是从它所属的条件属性相对于决策属性的相对熵由大到小(也即属性重要性由小到大)的顺序进行的,所以,属性重要性较小的属性的断点被淘汰的概率更大,从而避免了从重要性较大的属性中去掉过多的断点,提高了决策表的分类能力.这个离散化过程同时也是属性约简的过程(如果一个属性的所有断点都被去掉了,就意味着这个属性是冗余的,可以从决策表中去掉)。3.2 算法的时间复杂性(1) 求一个属性的候选断点集,要经过排序和求平均,其时间复杂性为O(n
2) , 所以Step1时间复杂性为O(kn
2) ;(2) 相对熵
E(D|ai),属性重要性
SGF(p,B,D)的时间复杂性为O(kn
2) ,对属性重要性
SGF(p,B,D)进行排序的时间复杂性为klogk , 所以Step2时间复杂性为O(kn
2) ;(3) 把决策表中与c
j相邻的两个属性值的较小值改为较大值,检验决策表是否引起冲突的时间复杂性为O(n
2),所以完成Step3、Step4的时间复杂性为O(kn
2)。因此,整个算法的时间复杂性为O(3kn
2)。3.3举例设原始决策表如表1所示,其中,决策属性A={a,b},条件属性D={d}.显然有:
U/{d}={{1,4,6,7,8},{2,3,5}}={Y
1,Y
2};
U/{a}={{1},{2},{3,6},{4,5},{7,8}}={X
1,X
2,X
3,X
4,X
5};
U/{b}={{1,5},{2},{3,7,8},{4,6}}={Z
1,Z
2,Z
3,Z
4};计算属性重要性,开始B=Φ,
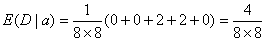
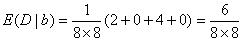
所以
SGF(a,D)=E(D)-E(D|a)>E(D)-E(D|b)=SGF(b,D)对决策表1,其候选断点集为:
Ca={0.8,1.1,1.4,1.8,3};
Cb={0.9,2,4}由上面的计算知
SGF(b,D)<SGF(a,D),所以从属性b开始:首先考虑断点0.9,它有相邻属性值为0.8和1,把属性值0.8改为1后,不引起决策表的冲突,则断点0.9是多余的;接着考虑断点2,它的相邻属性值为1和3;当把1改为3时,实例4和5将会冲突,这说明断点2是保持决策表的不分明关系所必须具有的断点,故应该保留;最后考虑断点4, 它的相邻属性值为3和5, 把属性值3改为5后,不引起决策表的冲突,则断点4是多余的;得到的决策表为表2 表1 原始决策表 表2 属性b离散化后的决策表
| U | a | b | D |
| 1 | 0.6 | 3 | 1 |
| 2 | 1 | 0.8 | 0 |
| 3 | 1.2 | 5 | 0 |
| 4 | 1.6 | 1 | 1 |
| 5 | 1.6 | 3 | 0 |
| 6 | 1.2 | 1 | 1 |
| 7 | 2 | 5 | 1 |
| 8 | 4 | 5 | 1 |
| U | a | b | D |
| 1 | 0.6 | 5 | 1 |
| 2 | 1 | 1 | 0 |
| 3 | 1.2 | 5 | 0 |
| 4 | 1.6 | 1 | 1 |
| 5 | 1.6 | 5 | 0 |
| 6 | 1.2 | 1 | 1 |
| 7 | 2 | 5 | 1 |
| 8 | 4 | 5 | 1 |
同样对属性a的断点
Ca={0.9,1.15,1.35,1.5,2.2}进行判断,得决策表为表3,最终得到的决策表为表4。表3 属性a离散化后的决策表 表4 最终的决策表
| U | a | b | D |
| 1 | 1 | 5 | 1 |
| 2 | 1 | 1 | 0 |
| 3 | 1.6 | 5 | 0 |
| 4 | 1.6 | 1 | 1 |
| 5 | 1.6 | 5 | 0 |
| 6 | 1.6 | 1 | 1 |
| 7 | 4 | 5 | 1 |
| 8 | 4 | 5 | 1 |
| U | a | b | D |
| 1 | 0 | 1 | 1 |
| 2 | 0 | 0 | 0 |
| 3 | 1 | 1 | 0 |
| 4 | 1 | 0 | 1 |
| 5 | 1 | 1 | 0 |
| 6 | 1 | 0 | 1 |
| 7 | 2 | 1 | 1 |
| 8 | 2 | 1 | 1 |
4 结束语提出的基于相对熵的离散化算法可在离散化数据的同时约简冗余的属性,而且保持决策表的一致性不变。数值离散化以后对属性表的所有数据作属性约简和值约减操作,最终获得简化的决策表,决策表的每一条记录就是一个决策规则.该算法易于理解,计算简单。:[1]Pawlak Z. Rough set theoretical aspects of reasoning about date[M] . Poland : Warsaw , 1991[2]王国胤.Rough 集理论与知识获取[M].西安:西安大学出版社,2001.24-31,51.[3]林仁炳,王基一.连续属性离散化算法的时间复杂性分析[J].计算机与化,2005,9: 40-42[4]林镇飚,桂现才.粗糙集理论中决策表属性约简的信息量表示[J].广西师范
学院学报, 2005,22(2): 35-38[5]梁吉业,曲开社,徐宗本.信息系统的属性约简[J].系统工程理论与实践,2001,21(12): 76-80.[6]JiYe Liang, Chin K.S, ChuangYin Dang,et al. A new mothod for measuring uncertainty and fuzziness in rough set theory. International Journal of General System. 2002,31(4):33-342[7]王国胤,于洪,杨大春.基于条件信息熵的决策表约简[J].计算机学报,2002,25(7):759- 766[8]桂现才,彭宏.决策表属性约简及其条件信息量表示[J].计算机工程与应用,2006,(待发表)