基于网页结构挖掘算法研究
来源:岁月联盟
时间:2010-08-30
1 数据挖掘
Web作为目前Internet的主要信息发布渠道,包含了丰富的、动态的超链接信息,这为数据挖掘提供了丰富的资源。现有的知识发现(KDD)的方法和技术已不能满足人们从Web中获取知识的需要。许多时候人们苦于在巨大的世界中不容易找到自己感兴趣的、权威的内容。所以人们迫切需要找到这样的工具,能够从WEB上快速地、有效地发现资源,发现隐含的性的内容,提高在WEB上检索信息、利用信息的效率。数据挖掘便应运而生。数据挖掘通常有内容挖掘、使用挖掘和结构挖掘三种类型。本文主要研究结构挖掘。Web结构挖掘是指通过分析不同网页之间的超链结构,发现许多蕴涵在Web内容之外的对我们有潜在价值的模式和知识的过程。2 结构挖掘
WWW没有数据库那样严格统一的语义模式,但也不像平面文件那样完全没有结构,从信息结构的角度来看,WWW上的资源有三种类型:结构化资源、半结构化资源和无结构化资源,它的语义隐含在语法结构之中。忽略掉Web页面上的文本和其它内容,只考虑页面间的超链,WWW可以被看作是以Web页面为节点、页面之间超链为有向边所构成的网状结构的有向图,把Web看成是一个巨大的有向图G =(V,E),结点v∈V代表一个Web页面,有向边(p,q)∈E代表从结点p指向结点q的超链接。结构挖掘就是要在这样的网络有向图中进行超链分析。通过分析超链可以获悉网站的受欢迎程度及与其它网站的关系,而且,通过网页之间的链接还能够快速了解一个网站的内部结构。WWW是一个超文本文档信息系统,而超链是表示信息的一个重要方式,所以挖掘超链的语义结构十分必要和有意义。 在WWW上网页内部的超链用HTML、XML表示成树形结构,文档表示成URL中的目录路径结构,站点之间通过超链同其它相关联的站点或页面相链接。相关主题的站点和页面之间一般都存在大量的链接,通过这种链接方式相聚集。但主题相同的所有站点或页面不一定会围绕一个中心(Hub) 相聚集,也就是说一个主题会存在多个聚集中心。一个网站如果链接了许多权威网站,那么它就是一个中心网站(Hub);如果一个网站被许多中心网站链接,那么它就是一个权威网站(Authority),如图1、图2所示。很多网站管理和设计人员通常愿意链接可信度高的网站。因而一个网站的可信度可以根据它所链接的网站的权威程度来衡量,同时它会推荐给用户许多好的权威网站,对其它网站的权威性起到了一定程度的增强作用。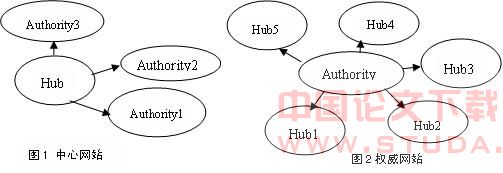
3 Web结构挖掘的算法
利用超链进行挖掘的两个典型的算法是:PageRank算法及HITS算法。本文主要介绍HITS算法,并针对HITS算法的不足之处提出一种改进的方法。采用这种改进算法,可以从任意页面集中计算出具有最大Authority权值和Hub权值的页面。3.1 HITS 算法
HITS(Hyperlink Induced Topic Search) 是Web结构挖掘的一个基本算法。此算法建立在下面几个定义之上: ①Hubs页,指的是一个指向权威页的超链接集合的Web页; ②Authorities页,指的是被许多Hubs页指向的权威的Web 页; ③以及由这两个定义所衍生出来的一个Web 页的Authority权重(由网页的out-link 决定) 和 Hub 权重(由网页的in-link 决定)。 其算法步骤如下: 1) 根据用户查询请求,首先用一个现有的商业搜索引擎进行查询,取其部分查询结果(约200个左右)作为算法的根集,记为 Rδ. 2) 将 Rδ 进行扩充,对Rδ中每一个结点,将所有指向该结点或该结点所指向的网页补充进来,形成基集,记为 Sδ. 3) 计算Sδ中每一个网页的Authority权重和Hub权重,这是一个递归过程. 先将网页 p的Authority权重记为 ap ,Hub 权重记为hp,为 Sδ中所有网页赋初值:ap (0)←1,hp (0)←1;再通过以下迭代公式对 ap 和 hp 进行反复修正,直至结果收敛:I操作: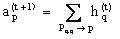 O操作:
O操作: 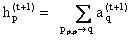 这里 q←p 的含义是存在一个由 q 指向 p 的超链接。 设
这里 q←p 的含义是存在一个由 q 指向 p 的超链接。 设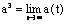 且
且 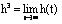 ,a ( t) 、h ( t) 迭代的初始向量为[1,…, 1] T, 则a3 、h3 分别收敛为矩阵 XTX、XXT主特征向量。因此,页面i 的Authority权重为ai3,Hub权重为hi3。具有较大的a3 和 h3 的页面就是Authorities 页和 Hubs 页。 基于HITS算法的系统包括Clever、Google 也基于同样的原理。这些系统由于纳入了 Web链接和文本内容信息,查询效果明显优于基于词类索引引擎产生的结果,如 AltaVista , 和基于人工的本体论生成的结果,如Yahoo!。
,a ( t) 、h ( t) 迭代的初始向量为[1,…, 1] T, 则a3 、h3 分别收敛为矩阵 XTX、XXT主特征向量。因此,页面i 的Authority权重为ai3,Hub权重为hi3。具有较大的a3 和 h3 的页面就是Authorities 页和 Hubs 页。 基于HITS算法的系统包括Clever、Google 也基于同样的原理。这些系统由于纳入了 Web链接和文本内容信息,查询效果明显优于基于词类索引引擎产生的结果,如 AltaVista , 和基于人工的本体论生成的结果,如Yahoo!。