基于本体的专利知识发现体系研究
来源:岁月联盟
时间:2010-08-30
1 引言
专利是世界上最大的信息源。全世界专利数量超过3000万件,每年平均有近100万个新的申请。各国每年出版的专利占科技出版物的1/4,但内容包含了世界科技信息的90%~95%[2]。专利信息是蕴含在专利文献中的关于申请专利的发明创造的技术内容、专利保护的范围以及谁拥有专利、专利是否有效等内容的信息。对情报用户来说专利工作的瓶颈正从专利文献的获取转向专利知识的发现[1]。用户所要求的“专业”信息服务不再是简单地检索和物理地获取专利文献,而是帮助他们将知识内容从众多信息对象中挖掘出来,根据其内在特征和价值进行鉴别、关联、重组,帮助他们了解行业技术及衍变趋势、进行专利信息的地域性分析、行业竞争者的分析、行业发明人分析、自身技术能力比较分析,帮助企业的竞争战略决策和专利战略制定。 目前包括在内的各国或国际组织均可提供在线的专利著录项检索服务,但这些仅是用户进行专利情报发现的初衷,如何有效地进行专利情报分析、获取竞争对手信息才是根本目的。人工专利分析因耗时长、精度差、效率低、分析易受主观影响等缺点,在实际工作中受到了极大的限制。2 专利研究背景
目前,从技术角度看,对专利的研究主要分为专利检索技术和专利分析技术。 1)专利检索技术 目前,主流的信息资源管理和检索系统主要利用以下方法:以搜索引擎和专业数据库系统为代表的基于关键词的检索;以主题网关为代表的以元数据为基础的检索;基于数据库字段值和数据模式的模糊匹配检索;以主题词表为基础的概念检索等。由于本体能够很好地描述概念的内涵以及概念与概念之间的关系,具有良好的概念层次结构和对逻辑推理的支持,因而在信息检索,特别是在基于知识的检索中得到了广泛的应用。 2)专利分析技术 专利信息的分析方法包括定量分析、定性分析和权利的分析。目前,上能找到的专利软件分析工具有很多:如Thomson公司的德温特分析家、韩国WinsLAB有限公司的INAS,我国连颖公司开发的PatentGuide,Wisdomain公司的PatentLab-11。中国国家知识产权局组织,知识产权出版社开发的“专利战略分析系统3.0”也于2005年初投入使用。 通过对其中一些软件工具使用,发现:这些工具所提供的分析功能,主要集中在基于定量分析的统计信息的图形化显示。因此企业急需一种专家级、智能化的专利情报发现方案,从基础专利数据入手,提供准确、高效的情报分析。文章拟提出一种基于本体的专利情报发现体系。3 基于本体的专利情报发现体系理论架构
W.N.Borst给出了Ontology的定义 “本体是共享的概念模型的形式化的规范说明”[3]。本体论可以按分类法来组织它包含5个基本的建模元语(Modeling Primitive),这些元语分别为类(classes)、关系(relations)、函数(functions)、公理(axioms)和实例(instances),通常也把类(classes)写成概念(concepts)[5]。 整个体系均以Ontology为模块间的交流平台,保证了模块间标准的通信规则,提高了异构模块媾和的一致性,为推理引擎有效关联外部方法库、模型库提供了保证。以Ontology为核心,借助企业的外部资源以及数据挖掘、推理引擎等智能技术,我们可将该体系包装成一个有关专利资源的知识服务门户,它不仅提供专利的简单查询,还可利用各种预先设定的算法和技术指标为用户提供专利技术分析、行业发展预测、竞争对手追踪等服务。 我们构建的基于本体的专利情报发现体系可以分为三部分用户界面、功能区、资源区(如图1)。用户通过查询界面进行专利查询及需求分析。用户通过客户端输入语言,经过查询分析模块进行句法分析、语法分析、分词系统提取关键字,进行专利的查询和逻辑匹配,最后利用推理引擎、Patent方法库、Patent模型库等最终实现结果的情报发现。以上所有模块都依靠专利本体库协调。专利本体库构建的资源来源于购买的专利数据库、已下载到本地硬盘的专利、Internet网上专利库等。知识工作者利用服务器对本体进行Ontology的编辑、维护和更新。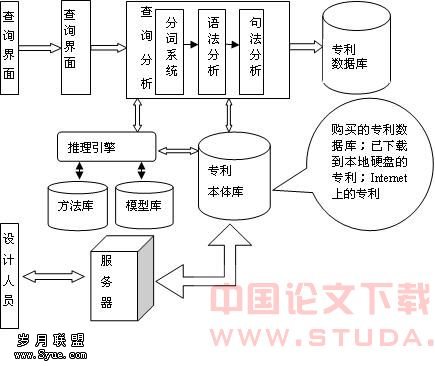 图1 基于本体的专利情报发现体系结构
图1 基于本体的专利情报发现体系结构4 基于本体的专利知识发现体系实例
4.1 本体构建的技术
构建领域本体的方法有:Uschold、Gruninger&Fox (又称TOVE)、 Meth、 Bernerasetal等。本体构建工具有很多,其中较为常见的主要包括Ontolingua、OntoEdit、Ontosaurus和Protégé等。 本文采用Protégé3.3.1作为建立本体的工具。Protégé是由斯坦福大学的Stanford Medical Informatics开发的一个开放源码的本体编辑器和知识管理平台,它是用Java编写的、基于插件形式的高度可扩展的体系结构。 本文所采用的本体构建过程分为下面7步[7]: (1)确定本体的领域和范围。 (2)考虑重用现有本体。目前网络上已有一些本体库,如DAML本体库。 (3)列出本体中的重要术语。这些术语大致表明建模过程所感兴趣的事物所具有的属性和它们之间的关系等。 (4)定义类和类的支撑。类的继承结构的定义可以采用自顶向下的方法,即从最大的概念开始,然后通过添加子类细化这些概念;也可以采用自底向上的方法;也可采用这两种方法的综合进行定义。 (5)定义属性和关系。仅有类对很多问题都不能给出回答,因此还需要定义概念和概念间的内部联系。 (6)定义属性的限制。包括属性的基数、属性值的类型,以及属性的定义域和值域。 (7)构建实例。需要确定与个体最接近的类,然后添加个体进取作为概念的一个实例,同时要为实例的属性赋值。4.2 构建一个简单的实例本体
 图2专利本体的结构 我们定义电子专利本体,O=(C,R,F,A,I)C代表领域中的概念集合,R代表概念集C之间的关系集合,F表示函数,A表示公理,I代表实例。本文中我们将专利本体分3类:即电子专利类、竞争类 、地区类。图2显示了该专利本体的结构。 在上述分类的基础上,设置对象属性:拥有、属于和部分,并将拥有和属于设为逆反属性;设置数据属性,包括专利号、申请号、申请日期、申请人;在申请人属性下设子属性所属公司。在MP3下位类设置专利号为CN200630153997.0,CN200630153995.1,CN200630153814.5等专利实例;在直接竞争对手下位类设置三星、诺基亚、摩托罗拉、索尼爱立信等。最后,对属性设置相应的定义域和值域,并在实例的属性域中选择相应的取值(如图3所示)。
图2专利本体的结构 我们定义电子专利本体,O=(C,R,F,A,I)C代表领域中的概念集合,R代表概念集C之间的关系集合,F表示函数,A表示公理,I代表实例。本文中我们将专利本体分3类:即电子专利类、竞争类 、地区类。图2显示了该专利本体的结构。 在上述分类的基础上,设置对象属性:拥有、属于和部分,并将拥有和属于设为逆反属性;设置数据属性,包括专利号、申请号、申请日期、申请人;在申请人属性下设子属性所属公司。在MP3下位类设置专利号为CN200630153997.0,CN200630153995.1,CN200630153814.5等专利实例;在直接竞争对手下位类设置三星、诺基亚、摩托罗拉、索尼爱立信等。最后,对属性设置相应的定义域和值域,并在实例的属性域中选择相应的取值(如图3所示)。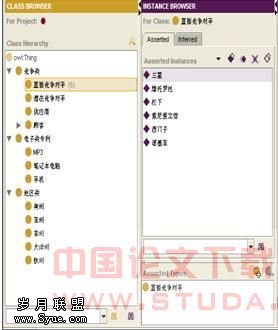 图3 属性域 通过以上步骤我们利用Protégé3.3.1成功的构建了一个简单的专利本体。
图3 属性域 通过以上步骤我们利用Protégé3.3.1成功的构建了一个简单的专利本体。5 专利知识查询系统
用户对于用户的查询个体及所要查询的个体信息感兴趣。比如:用户查询中专利号为CN200630153997.0专利所属公司,用户除了对所属公司是哪个公司感兴趣外,也希望获得这家公司的相关信息。这是基于用户的这一查询偏好,作者提出了下面的算法,算法返回直接信息的同时还进行了相应的扩展查询。5.1 系统结构
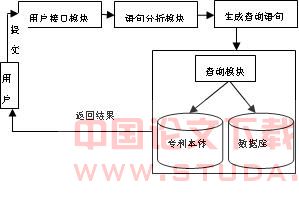
图4 专利知识查询系统
用户接口主要负责与用户进行交互,比如提供查询界面,显示结果界面等。动态匹配阶段主要负责接收用户所提交的查询信息并结合本体分析查询信息词之间的语义关系,对相关查询信息词进行动态绑定,形成sparql查询语句。知识库检索部分主要负责完成sparql查询语句的执行。信息检索部分负责完成相关扩展查询,从而提供给用户丰富的相关信息。5.2 用户查询模式分析
知识库中的每条知识由一个Statement组成,多个Statement整个知识库,其中每个Statement又是由三部分组成:S(rdf:subject)、P(rdf:predicate)、O(rdf:object)。以下关于用户查询模式的分析S:Statement中的Subject,P:Statement中的Predict,O:Statement中的Object,Q:一个查询语句,I:个体(Individual)。查询模式可分为以下几种具体情形: ① Q(I):对单独某个个体的所有相关信息进行查询。 例句:专利号为CN200630153997.0的专利的相关信息? ② Q(I1,I2………In):对多个个体的所有相关信息进行查询。 例句:笔记本电脑类专利的相关信息? ③ Q(I,P):对某个个体的某一个属性进行查询。 例句:专利号为CN200630153997.0的专利名称? ④ Q(I1,P1,P2…..P n):对某个个体的多个属性进行查询。 例句:专利号为CN200630153997.0的专利名称、发明人、申请人、申请日期、申请号。 ⑤ Q((I1,P1,P2…..Pn),(I2,P1,P2….Pn)):对多个个体的多个属性进行查询。 例句:专利号为CN200630153997.0的专利名称、申请人、申请日期以及申请人所在公司的成立日期,公司近期发布的消息。 ⑥ Q((I1,P1,P2…..Pn),I2):对某个个体的多个属性查询的同时对另一个个体的所有相关信息进行查询。 例句:专利号为CN200630153997.0的专利名称、申请人、申请日期以及申请人所在公司的相关信息。 ⑦ Q(P,O):对具有某个属性值的个体进行查询。 例句:IBM公司申请的专利有哪些? ⑧ Q(P):对某个属性进行查询。 例句:申请人 ⑨ Q(P1,P2……Pn):对多个属性进行查询。 例句:申请人 申请日期 发布消息 分析:在上述9种情形中,对于前三种情形的查询,目前的搜索引擎一般都达到令人满意的效果。但是对于Q(I1,P1,P2…..Pn)、Q((I1,P1,P2…..Pn)、Q(I2,P1,P2….Pn))、Q((I1,P1,P2…..Pn),I2)、Q(P,O)这四种情形的查询,使用现有的搜索引擎一般要进行多次查询,这样反复的过程对用户来讲并不理想,下面的算法正是针对这种缺陷。5.3 动态匹配算法过程
下面将结合例句1:“专利号为CN200630153997.0的专利的专利名称、申请人、申请号、申请日期以及申请人所在公司的成立日期,公司近期发布的消息”。 算法过程分析如下: 输入:用户输入查询语句。 输出:用户所查询的直接结果及扩展查询结果。 算法描述: Step1:语句分析阶段。 接收用户提交的查询,结合专利本体进行分析,过滤掉不属于本体资源的词汇。对于例句1,将过滤掉“的”、“以及”、“的”、“和”等字眼。 Step2:分组阶段 结合本体对于Step1已经过滤的多个查询关键词进行分组处理,最终将这多个关键词分为类组、对象属性组、数据属性组以及个体组。 对于例句1来讲,通过过滤阶段将形成如下四组: 类组:{笔记本电脑、mp3} 对象属性组:{专利名称、申请人} 数据属性组:{成立日期、申请号、申请日期} 个体组:{专利号为CN200630153997.0的专利、申请人所在公司} Step3:匹配封装阶段。 该阶段主要是结合本体对于上述四个分组进行处理。这一阶段又分为以下两个子阶段: 构造属性三元组阶段 以对象属性组为例,首先逐一获取数组中每个对象属性的定义域和值域,然后由每个属性的定义域、属性、值域这三个资源封装到对象属性Statement数组中,再按相同的方式处理数据属性组,形成数据属性Statement数组。 个体-属性匹配阶段 分别用个体所属的类与对象属性Statement数组和数据属性Statement数组中的每个属性的定义域和值域进行匹配,如果该个体符合某个属性的定义域或者值域,或者该个体所属类是某个属性的定义域的子类,就将该个体-属性对封装到两个数组定义域Match和值域Match中。其中,定义域Match数组中是能与某个属性的定义域相匹配的个体,值域Match数组是与某个属性的值域相匹配的个体。 Step4:查询语句构造阶段。 该阶段主要是结合Step3已经匹配封装好的数组对每一属性、个体对逐一进行sparql查询语句的构造。 Step5:执行查询阶段。 输入个体的扩展查询 主要负责对用户提交的个体进行查询,返回个体的相关信息以及相关链接。 查询个体的扩展查询 主要负责对返回结果中的个体进行处理,如果知识库中有对该个体的进一步描述信息,将对该个体进行扩展查询。5.4 改善基于本体的专利知识查询服务
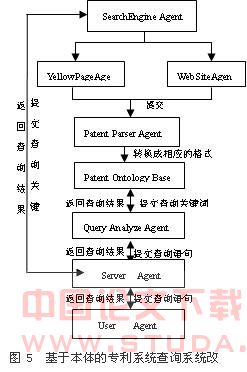
专利知识内容繁多,而且每天不断更新,这就需要我们不断地扩充本体专利库,以获得用户想要的信息。在这里我们利用本体和Web挖掘技术改善本体查询服务。获得新的专利信息,可以通过世界专利网(www.sjzlw.com),也可以通过综合网站,比如黄页。 作者构建了Patent Digger系统来改善基于本体的专利知识查询服务(图5)。此系统由3部分组成,包括用户交互、数据处理与分析、挖掘等模块,各模块由若干个Agent组成。Server Agent独立于各模块,负责协调各模块间Agent的工作。用户交互模块由User Agent负责与专利查询用户交互。数据处理与分析模块由Patent Ontology Base 和Query Analyze Agent构成,其中Patent Ontology Base负责管理扩展的本体库,将搜集到的专利信息根据本体的模式转换成相应的格式存入Patent Ontology Base。Query Analyze Agent分析提交的用户查询语句,并与Patent Ontology Base中的信息进行逻辑匹配。网络挖掘模块中,为查找指定网页的Spider,Search Engine Agent负责连接搜索引擎,Yellow Page Agent 和Web Site Agent分别以后台方式和在线方式进行挖掘。Patent Parser Agent负责文本内容挖掘,结合专利本体提取网上的专利信息。