缓存同步操作--sys_sync系统调用
sys_sync系统调用被用户空间函数调用,用来将缓存中的数据写入块设备, sys_sync系统调用将buffer、inode和super在缓存中的数据写入设备。sys_sync函数在fs/buffer.c中,现分析如下:
asmlinkage long sys_sync(void)
{
do_sync(1);
return 0;
}
函数do_sync各种数据,开始唤醒pdflush,因为它并行地把所有队列写回设备。函数分析如下:
static void do_sync(unsigned long wait)
{
wakeup_bdflush(0);
sync_inodes(0); /* All mappings, inodes and their blockdevs */
DQUOT_SYNC(NULL);
// 最终调用sb->s_op->write_super(sb)即具体文件系统的函数来实现写超级块
sync_supers(); /* Write the superblocks */
sync_filesystems(0); /* Start syncing the filesystems */
sync_filesystems(wait); /* Waitingly sync the filesystems */
sync_inodes(wait); /* Mappings, inodes and blockdevs, again. */
if (!wait)
printk("Emergency Sync complete/n");
if (unlikely(laptop_mode))
laptop_sync_completion();
}
多个节点同步回写操作函数sync_inodes
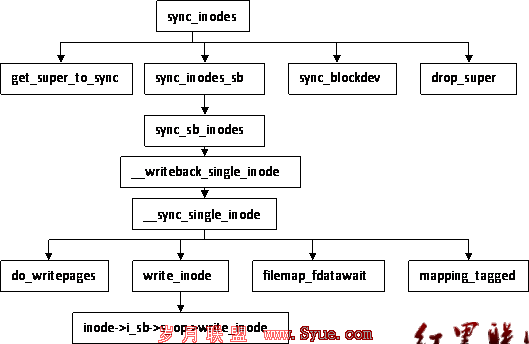
函数sync_inodes调用层次图
函数sync_inodes遍历每个超级块的脏节点链表,把节点写回到块设备,并等待回写操作的完成,写完成后把节点放回到正常的链表中。函数sync_inodes是给系统调用sys_sync用的,函数fsync_dev使用同样的算法。sync函数的精细地方是块设备"超级块"最后被处理。这是因为函数write_inode是典型的文件系统操作函数,它不执行I/O,而是在块设备映射的地址空间把buffer标识为脏。我们所想做的是先执行所有的标识脏的操作,接着,在一次扫描中通过块设备映射地址空间写回所有的节点块。这样附加的(在某种程度上说是冗余的)sync_blockdev函数在这儿调用来确认这个操作真正发生。因为如果我们对明显的脏节点调用函数sync_inodes_sb(wait=1),回写操作将在文件系统的函数write_inode里有时进入堵塞,这种情况下将运行极慢。
函数sync_inodes的调用层次图如上图,函数sync_inodes分析如下(在fs/fs-writeback.c中):
单个节点同步回写操作函数sync_inodes_sb
void sync_inodes(int wait)
{
struct super_block *sb;
set_sb_syncing(0);//设置每个超级块sb->s_syncing = 0
while ((sb = get_super_to_sync()) != NULL) {//得到脏的超级块结构
sync_inodes_sb(sb, 0);
//写与块设备对应的所有脏数据,并等待写操作完成
sync_blockdev(sb->s_bdev);
drop_super(sb);//使用计数减1,即sb->s_count-1
}
if (wait) {
set_sb_syncing(0);
while ((sb = get_super_to_sync()) != NULL) {
sync_inodes_sb(sb, 1);
sync_blockdev(sb->s_bdev);
drop_super(sb);
}
}
}
函数sync_inodes_sb执行回写操作并等待在文件系统的脏节点上。调用者将有两个方式调用这个函数,一个是写,一个是等待写。对于等待写方式来说,WB_SYNC_HOLD标识用来把写的节点停在sb->s_dirty上等待。为了防止函数sys_sync的死锁,将写的页数给了一个限制。限制被加到潜在的脏节点里,因为每个节点写操作能弄脏块设备的页缓存。
函数sync_inodes_sb分析如下(在fs/fs-writeback.c中):
void sync_inodes_sb(struct super_block *sb, int wait)
{
struct writeback_control wbc = {
.sync_mode = wait ? WB_SYNC_ALL : WB_SYNC_HOLD,
};
unsigned long nr_dirty = read_page_state(nr_dirty);//得到脏页数
unsigned long nr_unstable = read_page_state(nr_unstable);//不稳定的页数
wbc.nr_to_write = nr_dirty + nr_unstable +
(inodes_stat.nr_inodes - inodes_stat.nr_unused) +
nr_dirty + nr_unstable;
wbc.nr_to_write += wbc.nr_to_write / 2; /* Bit more for luck */
spin_lock(&inode_lock);
sync_sb_inodes(sb, &wbc);
spin_unlock(&inode_lock);
}
函数sync_sb_inodes写回一个超级块的脏节点链表到块设备。根据sync_mode方式的不同,一个回写等待可在没有节点、所有节点或最后的节点上被执行。如果older_than_this非空,那么仅写回比older_than_this早些时候被弄脏的节点。
如果是一个pdlfush线程,就对整个链表使用pdflush的防冲突措施。对于函数sys_sync来说,WB_SYNC_HOLD标识是一个hack,它重绑定inode到sb->s_dirty,以便inode能被在__writeback_single_inode()上的线程定位。
函数sync_sb_inodes应在inode_lock情况下被调用。如果bdi结构非空,表示我们正被请求回写一个特定的队列,这个函数假定块设备超级块的节点被各种队列支持。因而所有的节点被搜索。对其它超级块来说,假定所有的节点被同一队列支持。
被写的节点被停在sb->s_io上,当他们被选择写时,它们被移回到sb->s_dirty上。这样,在写者控制的途中就不会有丢失。并且得到在多个调节线程之间的相当好的平衡:我们不想它们所有的堆积在__wait_on_inode上。
函数sync_sb_inodes分析如下(在fs/fs-writeback.c中):
static void sync_sb_inodes(struct super_block *sb,
struct writeback_control *wbc)
{
const unsigned long start = jiffies; /* livelock avoidance */
if (!wbc->for_kupdate || list_empty(&sb->s_io))
//将s_dirty链表加到s_io链表中,并初始化了s_dirty链表
list_splice_init(&sb->s_dirty, &sb->s_io);
while (!list_empty(&sb->s_io)) {
struct inode *inode = list_entry(sb->s_io.prev,
struct inode, i_list);
struct address_space *mapping = inode->i_mapping;
struct backing_dev_info *bdi = mapping->backing_dev_info;
long pages_skipped;
//内存支持的文件系统,不能用writepage刷新页
if (bdi->memory_backed) {
//将节点inode从i_list中移到s_dirty链表中
list_move(&inode->i_list, &sb->s_dirty);
if (sb == blockdev_superblock) {
//内存支持的块设备脏:ramdisk驱动程序做这,仅跳过这个节点
continue;
}
//内存支持文件系统的节点脏,而不是块设备支持的文件系统的节点脏,
//跳过整个超级块。
break;
}
//没用阻塞在请求队列上,且块设备写操作过多,跳过壅塞的块设备
if (wbc->nonblocking && bdi_write_congested(bdi)) {
wbc->encountered_congestion = 1;
if (sb != blockdev_superblock)//不是块设备的超级块
break; //* Skip a congested fs */
//将inode从i_list队列移到s_dirty队列上
list_move(&inode->i_list, &sb->s_dirty);
continue;
}
if (wbc->bdi && bdi != wbc->bdi) {//块设备有错误的队列
if (sb != blockdev_superblock) //不是块设备的超级块
break; /* fs has the wrong queue */
list_move(&inode->i_list, &sb->s_dirty);
continue;
}
//在sync_sb_inodes函数被调用后,才变成脏节点?
if (time_after(inode->dirtied_when, start))
break;
//节点最近被弄脏的?
if (wbc->older_than_this && time_after(inode->dirtied_when,
*wbc->older_than_this))
break;
//另外的 pdflush线程已在刷新这个队列或不能获得设备回写操作
if (current_is_pdflush() && !writeback_acquire(bdi))
break;
BUG_ON(inode->i_state & I_FREEING);
__iget(inode);
pages_skipped = wbc->pages_skipped;//得到不被写的页数
__writeback_single_inode(inode, wbc);//写回一个节点到设备
// WB_SYNC_HOLD表示为sys_sys()正持有在sb_dirty上的节点
if (wbc->sync_mode == WB_SYNC_HOLD) {
inode->dirtied_when = jiffies;
list_move(&inode->i_list, &sb->s_dirty);
}
if (current_is_pdflush()) //当前正在pdflush线程
writeback_release(bdi);//释放了bdi上BDI_pdflush状态位
if (wbc->pages_skipped != pages_skipped) {
//因为buffer锁住,writeback不进行处理,现在跳过这个节点
list_move(&inode->i_list, &sb->s_dirty);
}
spin_unlock(&inode_lock);
iput(inode);
spin_lock(&inode_lock);
if (wbc->nr_to_write <= 0)
break;
}
return; //留下任何没写的节点在s_io链表上
}
函数__writeback_single_inode写回一个节点的脏页到块设备,它在inode_lock下被调用。函数__writeback_single_inode分析如下(在fs/fs-writeback.c中):
static int __writeback_single_inode(struct inode *inode,
struct writeback_control *wbc)
{
//如果不是同步所有的且节点是锁住的,将节点移到s_dirty链表中
if ((wbc->sync_mode != WB_SYNC_ALL) && (inode->i_state & I_LOCK)) {
list_move(&inode->i_list, &inode->i_sb->s_dirty);
return 0;
}
//它是一个数据一致性同步,必须等待
while (inode->i_state & I_LOCK) {
__iget(inode);
spin_unlock(&inode_lock);
__wait_on_inode(inode);
iput(inode);
spin_lock(&inode_lock);
}
return __sync_single_inode(inode, wbc);
}
函数__sync_single_inode写单个节点的脏页和节点数据到硬盘上,如果wait被设备,则在这个节点上等待。整个回写的设计很复杂且脆弱,我们想避免当其它节点再次变脏时特殊节点存在饥饿的现象,防止死锁等。 函数__sync_single_inode分析如下(在fs/fs-writeback.c中):
static int __sync_single_inode(struct inode *inode,
struct writeback_control *wbc)
{
unsigned dirty;
struct address_space *mapping = inode->i_mapping;
struct super_block *sb = inode->i_sb;
int wait = wbc->sync_mode == WB_SYNC_ALL;
int ret;
BUG_ON(inode->i_state & I_LOCK);
//设置I_LOCK, 重设置I_DIRTY标识
dirty = inode->i_state & I_DIRTY;
inode->i_state |= I_LOCK;
inode->i_state &= ~I_DIRTY;
spin_unlock(&inode_lock);
ret = do_writepages(mapping, wbc);//将节点对应的地址空间的数据写回设备
//如果仅I_DIRTY_PAGES 被设置就不写节点到块设备
if (dirty & (I_DIRTY_SYNC | I_DIRTY_DATASYNC)) {
int err = write_inode(inode, wait);//写回节点到设备
if (ret == 0)
ret = err;
}
//遍历所给地址空间的回写页的链表,等待他们所有的脏页写完
if (wait) {
int err = filemap_fdatawait(mapping);
if (ret == 0)
ret = err;
}
spin_lock(&inode_lock);
inode->i_state &= ~I_LOCK;
if (!(inode->i_state & I_FREEING)) {
//节点非脏且mapping中的页有PAGECACHE_TAG_DIRTY标识
if (!(inode->i_state & I_DIRTY) &&
mapping_tagged(mapping, PAGECACHE_TAG_DIRTY)) {
//我们不写回所有的页,nfs_writepages()有时没做任何事却运行。
//重新把节点设置为脏,节点还在sb->s_io链表中
if (wbc->for_kupdate) {
//对kupdate函数,我们留节点在sb_dirty的头部,
//以便在队列变成不壅塞时它得到更多写机会,
inode->i_state |= I_DIRTY_PAGES;
list_move_tail(&inode->i_list, &sb->s_dirty);
} else {
//完全重把节点设置成脏,以便在这个超级块上其它节点得到回写机会。
//否则,一个文件的较重的写操作将会把其它所有的文件的回写操作挂起
inode->i_state |= I_DIRTY_PAGES;
inode->dirtied_when = jiffies;
list_move(&inode->i_list, &sb->s_dirty);//移到s_dirty链表上
}
} else if (inode->i_state & I_DIRTY) {
//当正回写这些页时,有人重把节点设置成脏
list_move(&inode->i_list, &sb->s_dirty);
} else if (atomic_read(&inode->i_count)) {
//节点中干净的,在使用的
list_move(&inode->i_list, &inode_in_use);
} else {
//节点中干净的,没使用的
list_move(&inode->i_list, &inode_unused);
inodes_stat.nr_unused++;
}
}
wake_up_inode(inode);//唤醒节点上的等待队列
return ret;
}
节点地址空间数据回写操作函数do_writepages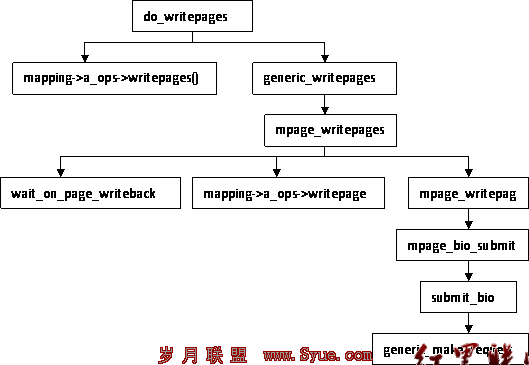
函数do_writepages调用层次图函数do_writepages写回地址空间mapping中的数据到设备,函数do_writepages调用层次图如上图,函数分析如下(在mm/page-writeback.c中):
int do_writepages(struct address_space *mapping,
struct writeback_control *wbc)
{
if (wbc->nr_to_write <= 0)
return 0;
if (mapping->a_ops->writepages)//使用指定的函数
return mapping->a_ops->writepages(mapping, wbc);
return generic_writepages(mapping, wbc);//使用通用函数
}
函数mpage_writepages遍历所给地址空间的脏页链表并把它们所有的写回块设备。其参数为:
mapping: 要写的地址空间结构
wbc: 回写所有页的信息结构,从wbc->nr_to_write 减去已写的页数
get_block: 文件系统的块映射函数指针,如果这是NULL,那么使用 a_ops->writepage,否则使用direct-to-BIO。
函数mpage_writepages是一个库函数,它利用地址空间结构里操作函数writepages()。如果一页已在I/O,使用generic_writepages()跳过它,即使它是脏的。对于内存清理的回写操作来说这是理想的行为,但它对调用如fsync()来进行数据一致性同步来说是不正确的。fsync()和msync()需要保证脏数据得到针对它们已开始的新I/O,所有的这些脏数据在调用时必须已准备好。如果wbc->sync_mode是WB_SYNC_ALL,那么函数mpage_writepages被调用来进行数据一致性回写,并且它必须等待正存在的I/O完成。
函数mpage_writepages分析如下(在fs/mpage.c中):
int mpage_writepages(struct address_space *mapping,
struct writeback_control *wbc, get_block_t get_block)
{
struct backing_dev_info *bdi = mapping->backing_dev_info;
struct bio *bio = NULL;
sector_t last_block_in_bio = 0;
int ret = 0;
int done = 0;
int (*writepage)(struct page *page, struct writeback_control *wbc);
//在许多地方,把多个页放在一起成一束来进行操作是有效的,
//pagevec是这样的多页的容器结构。
struct pagevec pvec;
int nr_pages;
pgoff_t index;
pgoff_t end = -1; /* Inclusive */
int scanned = 0;
int is_range = 0;
//块设备I/O是壅塞的
if (wbc->nonblocking && bdi_write_congested(bdi)) {
wbc->encountered_congestion = 1;
return 0;
}
writepage = NULL;
if (get_block == NULL)
writepage = mapping->a_ops->writepage;
//初始化pagevec结构pvec
pagevec_init(&pvec, 0);
//没有正在运行的回写同步,不需要等待
if (wbc->sync_mode == WB_SYNC_NONE) {
index = mapping->writeback_index; //从上次的偏移页序号开始
} else {
index = 0; //需要整个文件的扫描,从0页序号开始
scanned = 1;
}
if (wbc->start || wbc->end) {//计算开始与结束的页序号
index = wbc->start >> PAGE_CACHE_SHIFT;
end = wbc->end >> PAGE_CACHE_SHIFT;
is_range = 1;
scanned = 1;
}
retry:
while (!done && (index <= end) &&
//计算脏页数nr_pages,把脏页放在pvec中
(nr_pages = pagevec_lookup_tag(&pvec, mapping, &index,
PAGECACHE_TAG_DIRTY,
min(end - index, (pgoff_t)PAGEVEC_SIZE-1) + 1))) {
unsigned i;
scanned = 1;
for (i = 0; i < nr_pages; i++) {
struct page *page = pvec.pages[i];//得到脏页
//在这个地方,我们不持有mapping->tree_lock锁和页本身的锁:这页可能被剪除或无效(改变page->mapping到NULL),或者甚至从交换空间欺骗地回到tmpfs文件映射中。
lock_page(page);
if (unlikely(page->mapping != mapping)) {//页的地址空间不对
unlock_page(page);
continue;
}
if (unlikely(is_range) && page->index > end) {//所有的页已完成
done = 1;
unlock_page(page);
continue;
}
if (wbc->sync_mode != WB_SYNC_NONE)//正在同步操作
wait_on_page_writeback(page);
//页在回写或不是以前的脏页
if (PageWriteback(page) ||
!clear_page_dirty_for_io(page)) {
unlock_page(page);
continue;
}
if (writepage) {
ret = (*writepage)(page, wbc);
if (ret) {//返回有错误,设置到mapping->flags
if (ret == -ENOSPC)
set_bit(AS_ENOSPC,
&mapping->flags);
else
set_bit(AS_EIO,
&mapping->flags);
}
} else {
bio = mpage_writepage(bio, page, get_block,
&last_block_in_bio, &ret, wbc);
}
if (ret || (--(wbc->nr_to_write) <= 0))
done = 1;
if (wbc->nonblocking && bdi_write_congested(bdi)) {
wbc->encountered_congestion = 1;
done = 1;
}
}
pagevec_release(&pvec);
cond_resched();//进行调度
}
if (!scanned && !done) {
//命中最后一页,有更多的工作要做:折回到文件的开始
scanned = 1;
index = 0;
goto retry;
}
if (!is_range)
mapping->writeback_index = index;
if (bio)
mpage_bio_submit(WRITE, bio);
return ret;
}
如果页上有buffer那么这些buffer将被用来获得硬盘映射。我们仅支持整个已被映射且脏的页,还有特殊的情况:在文件结尾没被映射的页。如果页没有buffers那么页在这儿被映射。如果所有的块被发现是连续的,那么页能直接进入BIO,否则,回到mapping的writepage()函数。 函数mpage_writepage设计的目标是能估计还有多少页需要被写,这样它能智能地分配合适大小的BIO。但现在仅支持分配全部尺寸(16页)的BIO。
static struct bio *mpage_writepage(struct bio *bio, struct page *page,
get_block_t get_block, sector_t *last_block_in_bio,
int *ret, struct writeback_control *wbc)
{
struct address_space *mapping = page->mapping;
struct inode *inode = page->mapping->host;
const unsigned blkbits = inode->i_blkbits;
unsigned long end_index;
//每页的块数 www.2cto.com
const unsigned blocks_per_page = PAGE_CACHE_SIZE >> blkbits;
sector_t last_block;
sector_t block_in_file;
sector_t blocks[MAX_BUF_PER_PAGE];
unsigned page_block;
unsigned first_unmapped = blocks_per_page;
struct block_device *bdev = NULL;
int boundary = 0;
sector_t boundary_block = 0;
struct block_device *boundary_bdev = NULL;
int length;
struct buffer_head map_bh;
loff_t i_size = i_size_read(inode);
if (page_has_buffers(page)) {//如果页上有buffer
struct buffer_head *head = page_buffers(page);
struct buffer_head *bh = head;
//如果所有的buffer是映射且是脏的
page_block = 0;
do {
BUG_ON(buffer_locked(bh));
if (!buffer_mapped(bh)) {//buffer是非映射的
//非映射的脏buffer是由函数__set_page_dirty_buffers 映射数据创建
if (buffer_dirty(bh))//脏buffer
goto confused;
if (first_unmapped == blocks_per_page)
first_unmapped = page_block;
continue;
}
if (first_unmapped != blocks_per_page)
goto confused; /* hole -> non-hole */
//buffer非脏或非更新的
if (!buffer_dirty(bh) || !buffer_uptodate(bh))
goto confused;
if (page_block) {
if (bh->b_blocknr != blocks[page_block-1] + 1)
goto confused;
}
blocks[page_block++] = bh->b_blocknr;
boundary = buffer_boundary(bh);
if (boundary) {
boundary_block = bh->b_blocknr;
boundary_bdev = bh->b_bdev;
}
bdev = bh->b_bdev;
} while ((bh = bh->b_this_page) != head);
if (first_unmapped)
goto page_is_mapped;
/*页有buffer,但所有的buffer没被映射,这些页被在内存空洞上的pagein或读创建,这些空洞被函数block_read_full_page处理,如果address_space也用mpage_readpages,那么这种情况很少发生。*/
goto confused;
}
//页没有buffers,映射它到硬盘
BUG_ON(!PageUptodate(page));
//计算文件中页序号对应的块序号
block_in_file = page->index << (PAGE_CACHE_SHIFT - blkbits);
last_block = (i_size - 1) >> blkbits;
map_bh.b_page = page;
for (page_block = 0; page_block < blocks_per_page; ) {
map_bh.b_state = 0;
if (get_block(inode, block_in_file, &map_bh, 1))
goto confused;
if (buffer_new(&map_bh))//如果buffer是新的
//找到块号对应的buffer,清除脏标识并等待
unmap_underlying_metadata(map_bh.b_bdev,
map_bh.b_blocknr);
if (buffer_boundary(&map_bh)) {
boundary_block = map_bh.b_blocknr;
boundary_bdev = map_bh.b_bdev;
}
if (page_block) {
if (map_bh.b_blocknr != blocks[page_block-1] + 1)
goto confused;
}
blocks[page_block++] = map_bh.b_blocknr;
boundary = buffer_boundary(&map_bh);
bdev = map_bh.b_bdev;
if (block_in_file == last_block)
break;
block_in_file++;
}
BUG_ON(page_block == 0);
first_unmapped = page_block;
page_is_mapped:
end_index = i_size >> PAGE_CACHE_SHIFT;
if (page->index >= end_index) {
/*如果页跨过i_size,它在每writepage函数上一定会被赋0值,因为这页可能被映射。 一个文件映射多页,如果文件没有多页的大小,则当映射时剩下的空间是0,并且写这块区域时,它不能被写入到文件中去。*/
unsigned offset = i_size & (PAGE_CACHE_SIZE - 1);
char *kaddr;
if (page->index > end_index || !offset)
goto confused;
kaddr = kmap_atomic(page, KM_USER0);
memset(kaddr + offset, 0, PAGE_CACHE_SIZE - offset);//设置为0
flush_dcache_page(page);
kunmap_atomic(kaddr, KM_USER0);
}
//这页将去BIO,我们先送这页到BIO
if (bio && *last_block_in_bio != blocks[0] - 1)
bio = mpage_bio_submit(WRITE, bio);//提交BIO
alloc_new:
if (bio == NULL) {//分配新的BIO
bio = mpage_alloc(bdev, blocks[0] << (blkbits - 9),
bio_get_nr_vecs(bdev), GFP_NOFS|__GFP_HIGH);
if (bio == NULL)
goto confused;
}
/*在标识buffer为clean之前必须尝试加页到bio,当混乱坏路径(OOM)发现所有的bh标识干净时(它将不写任何东西),它将非常混乱。*/
length = first_unmapped << blkbits;
if (bio_add_page(bio, page, length, 0) < length) {//加页到bio
bio = mpage_bio_submit(WRITE, bio);//提交bio
goto alloc_new;
}
//我们有自己的BIO,因此我们现在能标识buffer为干净的,
//确信仅设置我们将写的buffer。
if (page_has_buffers(page)) {//页上有buffer
struct buffer_head *head = page_buffers(page);
struct buffer_head *bh = head;
unsigned buffer_counter = 0;
do {
if (buffer_counter++ == first_unmapped)
break;
clear_buffer_dirty(bh);//清除脏标识
bh = bh->b_this_page;
} while (bh != head);
//如果页不是更新的或同时发生的readpage不能与bh一起串行化,并且在我们达到platter之前它将读取硬盘时,我们不能删除bh
if (buffer_heads_over_limit && PageUptodate(page))
try_to_free_buffers(page);//释放buffer
}
BUG_ON(PageWriteback(page));
set_page_writeback(page);//设置页状态标识PG_writeback
unlock_page(page);
if (boundary || (first_unmapped != blocks_per_page)) {
bio = mpage_bio_submit(WRITE, bio);
if (boundary_block) {//边界块
//调用ll_rw_block函数写块对应的buffer到设备
write_boundary_block(boundary_bdev,
boundary_block, 1 << blkbits);
}
} else {
*last_block_in_bio = blocks[blocks_per_page - 1];
}
goto out;
confused:
if (bio)
bio = mpage_bio_submit(WRITE, bio);
*ret = page->mapping->a_ops->writepage(page, wbc);
//调用者有一个节点上的引用,这样mapping是稳定的
if (*ret) {
if (*ret == -ENOSPC)
set_bit(AS_ENOSPC, &mapping->flags);
else
set_bit(AS_EIO, &mapping->flags);
}
out:
return bio;
}
函数mpage_bio_submit赋上回调函数,提交读写操作,函数分析如下(在fs/mpage.c中):
struct bio *mpage_bio_submit(int rw, struct bio *bio)
{
bio->bi_end_io = mpage_end_io_read;//赋上读完后函数,用来进行页标识处理
if (rw == WRITE)
bio->bi_end_io = mpage_end_io_write;//赋上写完后处理函数
submit_bio(rw, bio);//提交操作
return NULL;
}
函数submit_bio 提交块I/O读写操作,函数分析如下(在drives/block/ll_rw_block.c中):
void submit_bio(int rw, struct bio *bio)
{
int count = bio_sectors(bio);
BIO_BUG_ON(!bio->bi_size);
BIO_BUG_ON(!bio->bi_io_vec);
bio->bi_rw = rw;
if (rw & WRITE)
mod_page_state(pgpgout, count);
else
mod_page_state(pgpgin, count);
…
/*这个函数是文件系统与块设备驱动程序的接口,它向块设备驱动程序提交块I/O操作,从这里开始进行驱动层,在块设备驱动程序中分析这一函数。*/
generic_make_request(bio);
}
块设备节点映射的数据同步回写函数sync_blockdev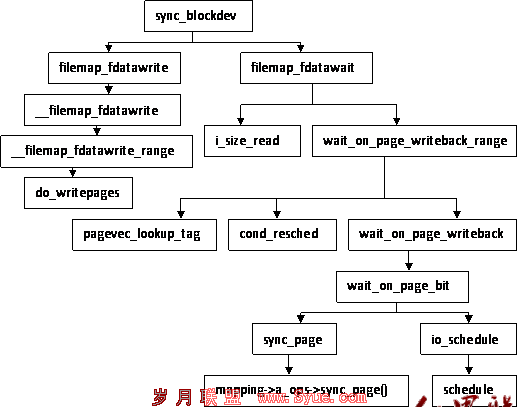
函数sync_blockdev的调用层次图
函数sync_blockdev通过块设备的设备节点的地址空间,回写并等待所有的与一个块设备相关的脏数据写回到设备上。函数sync_blockdev的调用层次图如上图。
函数sync_blockdev分析如下(在fs/buffer.c中):
int sync_blockdev(struct block_device *bdev)
{
int ret = 0;
if (bdev) {
int err;
//写回块设备节点映射的脏页数据
ret = filemap_fdatawrite(bdev->bd_inode->i_mapping);
err = filemap_fdatawait(bdev->bd_inode->i_mapping);
if (!ret)
ret = err;
}
return ret;
}
函数filemap_fdatawait遍历所给地址空间回写页的链表并等待在他们上面,其中参数mapping表示等待的地址空间结构。函数filemap_fdatawait分析如下(在/mm/filemap.c中):
int filemap_fdatawait(struct address_space *mapping)
{
loff_t i_size = i_size_read(mapping->host);
if (i_size == 0)
return 0;
return wait_on_page_writeback_range(mapping, 0,
(i_size - 1) >> PAGE_CACHE_SHIFT);
}
函数wait_on_page_writeback_range等待对从start到end的页完成回写操作。函数分析如下(在/mm/filemap.c中):
static int wait_on_page_writeback_range(struct address_space *mapping,
pgoff_t start, pgoff_t end)
{
struct pagevec pvec;
int nr_pages;
int ret = 0;
pgoff_t index;
if (end < start)
return 0;
pagevec_init(&pvec, 0);
index = start;
while ((index <= end) &&
//查找有回写标识PAGECACHE_TAG_WRITEBACK的页数
(nr_pages = pagevec_lookup_tag(&pvec, mapping, &index,
PAGECACHE_TAG_WRITEBACK,
min(end - index, (pgoff_t)PAGEVEC_SIZE-1) + 1)) != 0) {
unsigned i;
for (i = 0; i < nr_pages; i++) {
struct page *page = pvec.pages[i];
/* until radix tree lookup accepts end_index */
if (page->index > end)
continue;
//等待一页回写完成
wait_on_page_writeback(page);
if (PageError(page))
ret = -EIO;
}
pagevec_release(&pvec);
cond_resched();//调度
}
//检查明显的写错误
if (test_and_clear_bit(AS_ENOSPC, &mapping->flags))
ret = -ENOSPC;
if (test_and_clear_bit(AS_EIO, &mapping->flags))
ret = -EIO;
return ret;
}
函数wait_on_page_writeback等待一页完成回写动作,函数分析如下(在include/linux/pagemap.h中):
static inline void wait_on_page_writeback(struct page *page)
{
if (PageWriteback(page))//页上有回写标识
wait_on_page_bit(page, PG_writeback);
}
函数wait_on_page_bit分析如下(在mm/filemap.c中):
void fastcall wait_on_page_bit(struct page *page, int bit_nr)
{
//得到在页上等待队列
wait_queue_head_t *waitqueue = page_waitqueue(page);
DEFINE_PAGE_WAIT(wait, page, bit_nr);//得到页等待队列结构wait
do {
//设置当前进程状态,将wait.wait加到页等待队列waitqueue中
prepare_to_wait(waitqueue, &wait.wait, TASK_UNINTERRUPTIBLE);
if (test_bit(bit_nr, &page->flags)) {//测试标识
sync_page(page);
io_schedule(); //在需要调度时调度
}
} while (test_bit(bit_nr, &page->flags));
finish_wait(waitqueue, &wait.wait);
}
static inline int sync_page(struct page *page)
{
struct address_space *mapping;
smp_mb();//
mapping = page_mapping(page);//得到页对应的地址空间
//调用地址空间结构对应的页同步函数
if (mapping && mapping->a_ops && mapping->a_ops->sync_page)
return mapping->a_ops->sync_page(page);
return 0;
}
摘自 FenG71