linux集群基础知识
集群
集群 通俗地讲就是按照某种组织方式将几台电脑组织起来完成每种特定任务的这样的一种架构。
LB , load balancing 实现负载均衡 在一定程度上能够实现高可用的目的 分摊负载的
HA, High Availability 高可用,实时在线,能够及时响应客户端请求,企业应用要求达到7*24小时 99.999%时间在线,实现组织提供实时服务在线。
HP, High Performance 高性能集群 提供大量超级运算能力的集群
---提供大量复杂的运算,短时间的完成 实例比 如ibm的dna的绘制图谱集群,
scake on 向上扩展 用更好性能的计算机替代差的技术机 也可以使用高可用性。成本高
scale out 向外扩展 比如集群
负载均衡
便捷的扩展性 分摊负载的 lvs实现负载转发的
缺点 :单点故障 一个坏了 导致所有的都down机的
负载均衡也可以提供高可用性能力 便捷的扩展性
高可用集群
作用 保证服务实时在线 高可用性 可是实现故障的转移
rsync 同步 drbd 也可已实现同步 实现共享存储san 存储区域网络输出的块级别网络
高性能集群
要转发节点 前段的转发节点把复杂的任务解剖我n个小任务,而后每一个节点来计算这n个小任务,计算完了在返回前段的转发节点。
LB 复杂均衡集群
lvs :(linux virtual server) linux的虚拟服务器,作用接受用户发来的的请求得,它本事不提供请求得,真正提高 提供节点的叫realservers lvs这种那个以用 只需安装到调度节点上 ,这个转发节点我们也叫虚拟服务器, 四成路由 这种转发机制是透明的 lvs只是节点
工作模式 :三种
lvs提供优点 : for higher throughuput 高吞吐能力
for redundancy 冗余 高可用
for adaptability 使用性
lvs id address name conventions: ip地址的命名机制 表示不同的ip地址
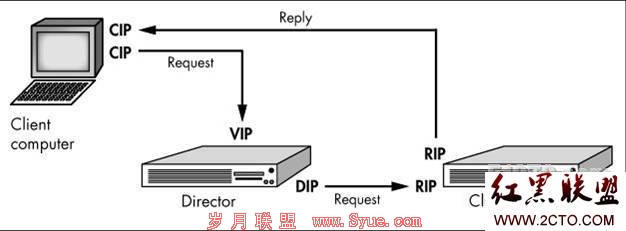
1)virtual id (vip)address : 虚拟ip地址 它并不提供服务 而是转发到后的其他的节点上去
2)read ip (rip) address : 后端真正提高服务的节点上的ip地址
3) director’s ip (dip) address : 转发器 调度器 分发器
4) Clinet computer’s ip(cip)address:客户端得ip地址
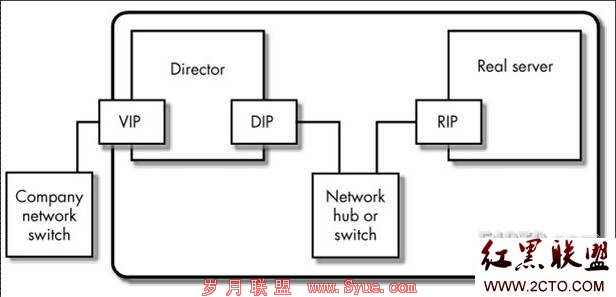
lvs集群的类型
1) lvs-nat 集群节点必须在同一个网段可以是子网站与vlan中,不能跨越ip网段, dip与rip必须在同一个子络中 不能跨越ip网段,rip通常可以是私有地址,所有的rip必须drp为的网关,nat的这种机制可以做端口映射 可以做端口转换 任何操作系统可以做 lvs-nat 单lvs-nat 都有可能作为系统的瓶颈
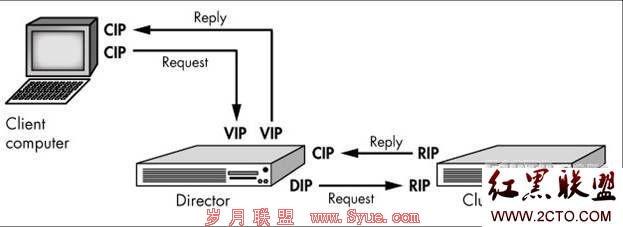
2) lvs-dr 直接路由
1、集群节点
2、rip可以使用公网地址
3、director仅处理用户的发来的请求realservers则不在响应 director仅处理请求 不出来响应
4、网关不能指向dip
5、不支持端口转换
6、大多操作系统都支持realservers
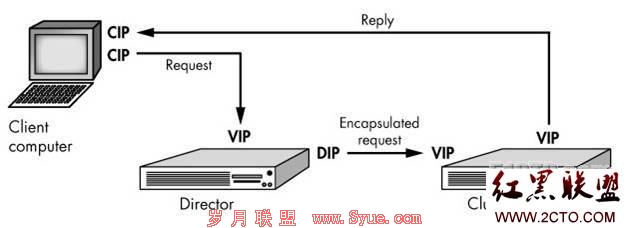
3) lvs-TUN 1、
haproxy :
HA
*heartbeat 书面意思是“心跳” 项目被分裂了
corosync+openais:RHCS
ultramokey
*keepalive
HP
bowerful
分发时所采用的算法
固定调度算法:按照某种既定的算法 不考虑当前的连接状态的
Round-robin(RR)轮调:根据当前请求到达时候,从服务列表中选择一个real server,请求重定向给这台 read server。
Destination hashing (DH)目标散列:是实现将来自同一服务器的请求都被重定向到同一台read server上去.
Source hashing (SH)源地址散列: 将来自同一个用户请求都转发都通过同一个router 和防火墙上
动态算法:通过检查服务器上当前连接的活动状态来重新决定下一把调度方式该如何实现。
lease connection (LC)最少连接 :那一个real server 上的链接数少就将下一个连接请求定向到那台real serever上去。
【算法 连接数=活动链接数*256+非活动链接数】
Weight least-Connection (WLC) 加权最少连接数:
【算法:连接数=(活动连接数*256+非活动连接数)/权重】
Shorterst expected delay (SED)最短期望延迟:不在考虑非活动连接数 活动连接数要加1【算法:连接数=(活动链接数+1)*256/权重】
Nerver queue (NQ)永不排队算法,当新请求过来的时候不仅要取决于SED算法所得到的值,还取决于real server 上是否有活动链接
Locality-Based Least-connection (LBLC)基于本地状态的最少连接。在DH算法的基础上还要考虑服务器上的活动链接数。支持权重
Locality-Bassed least-connection with requliction sscheduling (LBLCR)带复制的基于本地的最少连接 LBLC算法的改进。
作者 “天涯飞鸟”