Linux高可用性方案之Heartbeat架构
Heartbeat 概述
Heartbeat 是 Linux-HA 工程的一个组件, 1999 年开始到现在,发布了众多版本,是目前开源 Linux-HA 项目最成功的一个例子,在行业内得到了广泛的应用。随着 Linux在关键行业应用的逐渐增多,它必将提供一些原来由 IBM 和 SUN 这样的大型商业公司所提供的服务,这些商业公司所提供的服务都有一个关键特性,就是高可用集群。
高可用集群是指一组通过硬件和软件连接起来的独立计算机,它们在用户面前表现为一个单一系统,在这样的一组计算机系统内部的一个或者多个节点停止工作,服务会从故障节点切换到正常工作的节点上运行,不会引起服务中断。从这个定义可以看出,集群必须检测节点和服务何时失效,何时恢复为可用。这个任务通常由一组被称为“心跳”的代码完成。在 Linux-HA 里这个功能由一个叫做 heartbeat 的程序完成。而对于节点资源的控制,以及配置节点资源的监控状态等工作都交由Pacemaker也就是 CRM 来统一管理与操作。
基本框架
Heartbeat 分 1.x 和 2.x 两个大版本,v2 版本是可以兼容之前 v1 的配置文件的,但从功能的角度来看,v2 要强不少,关于Heartbeat v3版本大家可以认为是v2版本的修订版,主要修复了 Heartbeat v2版本中出现的bug,在v3版本中CRM模块更名为 Pacemaker:
2.x 支持 CRM 管理,资源文件由原来的 haresources 变为 cib.xml;
支持 ocf、lsb、stonith 等格式的 resource agent;
对多资源组进行独立监控,不再需要依赖 mon 或 ldirectord 等第三方脚本;
支持多节点,1.x只支持双节点;
提供 GUI 图形配置和管理工具。
Heartbeat 2.x 基于集群资源管理器(Cluster Resource Manager-CRM)CRM模 式 : 可 以 支 持 最 多 16 个 节 点 , 这 些 模 式 使 用 基 于 XML 的 集 群 信 息 ( Cluster Information Base-CIM)配置。CIB 文件(/var/lib/heartbeat/crm/cib.xml)
会在各个节点间自动复制,可以实现下面的操作:
集群节点配置和监控;
集群资源,包括属性、优先级、组和依赖性的定制;
日志、监控、仲裁和 fence 标准管理;
当服务失败或其中设定的标准满足时,需要执行的动作。
HA集群中的相关术语
节点(node)
运行Heartbeat进程的一个独立主机,称为节点,节点是HA的核心组成部分,每个节点上运行着操作系统和Heartbeat软件服务。在Heartbeat集群中,节点有主次之分,分别称为主节点和备用/备份节点,每个节点拥有惟一的主机名,并且拥有属于自己的一组资源,例如磁盘、文件系统、网络地址和应用服务等。主节点上一般运行着一个或多个应用服务,而备用节点一般处于监控状态。
资源(resource)
资源是一个节点可以控制的实体,并且当节点发生故障时,这些资源能够被其他节点接管。Heartbeat中,可以当做资源的实体有:
磁盘分区、文件系统;
IP地址
应用程序服务,如Oracle,DB2等
NFS文件系统
事件(event)
也就是集群中可能发生的事情,例如节点系统故障、网络连通故障、网卡故障和应用程序故障等。这些事件都会导致节点的资源发生转移,HA的测试也是基于这些事件来进行的。
动作(action)
事件发生时HA的响应方式、动作是由shell脚步控制的,例如,当某个节点发生故障后,备份节点将通过事先设定好的执行脚本进行服务的关闭或启动,进而接管故障节点的资源。
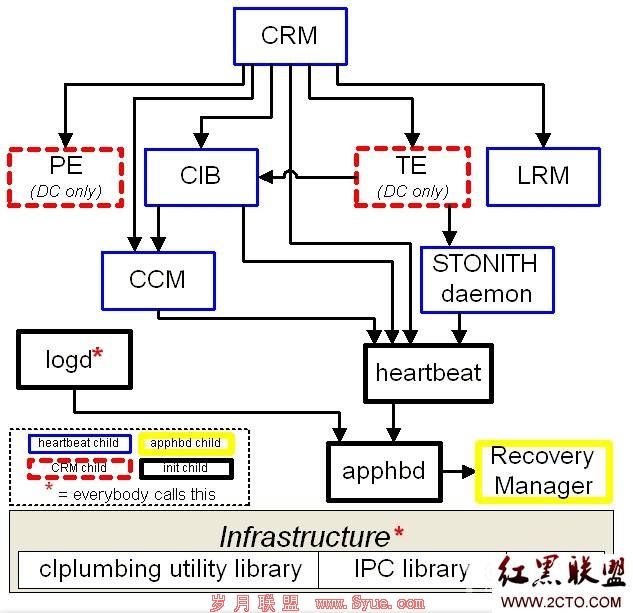
HA 2.x的主要模块
heartbeat模块:
整个Heartbeat软件的通信模块,各个节点之间的任何通信都是通过这个模块完成。这个模块会根据不同类型的通信启动不同的事件handler,当监听到不同类型的通信请求后会分给不同的handler来处理。这个从整个Heartbeat的启动日志中看出来。
CRM:cluster resource manager
从这个名字就可以看出这个模块基本上就是v2的heartbeat的一个指挥中心,整个系统的一个大脑了,他主要负责整个系统的各种资源的当前配置信息,以及各个资源的调度。也就是根据各资源的配置信息,以及当前的运行状况来决定每一个资源(或者资源组)到底该在哪个节点运行。不过这些事情并不是他直接去做的,而是通过调度其他的一些模块来进行。
他通过heartbeat模块来进行节点之间的通信,调度节点之间的工作协调。随时将通过heartbeat模块收集到的各个成员节点的基本信息转交给CCM模块来更新整个集群的membership信息。他指挥LRM(local resource manager)对当前节点的各资源执行各种相应的操作(如start、stop、restart和monitor等等),同时也接收LRM在进行各种操作的反馈信息并作出相应的决策再指挥后续工作。另外CRM模块还负责将各个模块反馈回来的各种信息通过调用设定的日志记录程序记录到日志文件中。
LRM:local resource manager
LRM是整个Heartbeat系统中直接操作所管理的各个资源的一个模块,负责对资源的监控,启动,停止或者重启等操作。这个模块目前好像支持有四种类型的资源代理(resource agent):heartbeat自身的,ocf(open cluster framework),lsb(linux standard base,其实就是linux下标准的init脚本),还有一种就是stonith。stonith这种我还不是太清楚是一个什么类型的。
四种类型的resource agent中的前三种所调用的脚本分别存如下路径:
heartbeat:/etc/ha.d/resource.d/
ocf:/usr/lib/resource.d/heartbeat/
lsb:/etc/init.d/
LRM就是通过调用以上路径下面的各种脚本来实现对资源的各种操作。每一种类型的脚本都可以由用户自定义,只要支持各类型的标准即可。实际上这里的标准就是接受一个标准的调用命令和参数格式,同时返回符合标准的值即可。至于脚本中的各种操作是如何,LRM并不care。
PE:CRM Policy Engine
他主要负责将CRM发过来的一些信息按照配置文件中的各种设置来进行计算,分析。然后将结果信息按照某种固定的格式通过CRM提交给TE(Transition engine)去分析出后续需要采取的相应的action。PE需要计算分析的信息主要是当前有哪些节点,各节点的状况,当前管理有哪些资源,各资源当前在哪一个节点,在各个节点的状态如何等等。
TE:Transition engine
主要工作是分析PE的计算结果,然后根据配置信息转换成后续所需的相应操作。个人感觉PE和TE组合成一个类似于规则引擎实现的功能,而且PE和TE这两个模块只有在处于active的节点被启动。另外PE和TE并不直接通信,而都是通过Heartbeat的指挥中心CRM来传达信息的。
CIB:cluster information base
CIB在系统中充当的是当前集群中各资源原始配置以及之后动态变化了的状态,统计信息收集分发中心,是一个不断更新的信息库。当他收集到任何资源的变化,以及节点统计信息的变化后,都会集成整合到一起组成当前集群最新的信息,并分发到集群各个节点。分发动作并不是自己和各个节点通信,同样也是通过heartbeat模块来做的。
CIB收集整理并汇总出来的信息是以一个xml格式保存起来的。实际上Heartbeat v2的资源配置文件也就是从haresources迁移到了一个叫cib.xml文件里面。该文件实际上就是CIB的信息库文件。在运行过程中,CIB可能会常读取并修改该文件的内容,以保证信息的更新。
CCM:consensus cluster membership
CCM的最主要工作就是管理集群中各个节点的成员以及各成员之间的关系。他让集群中各个节点有效的组织称一个整体,保持着稳定的连接。heartbeat模块所担当的只是一个通信工具,而CCM是通过这个通信工具来将各个成员连接到一起成为一个整体。
LOGD:logging daemon(non-blocking)
一个无阻塞的日志记录程序,主要负责接收CRM从各个其他模块所收集的相关信息,然后记录到指定额度日志文件中。当logd接收到日志信息后会立刻返回给CRM反馈。并不是一定要等到将所有信息记录到文件后再返回,日志信息的记录实际上是一个异步的操作。
APPHBD:application heartbeat daemon
apphbd模块实际上是给各个模块中可能需要用到的计时用的服务,是通过watchdog来实现的。这个模块具体的细节我还不是太清楚。
RMD:recovery manager daemon
主要功能是进程恢复管理,接受从apphbd所通知的某个(或者某些)进程异常退出或者失败或者hang住后的恢复请求。RMD在接受到请求后会作出restart(如果需要可能会有kill)操作。
下图是各个模块的逻辑组合:
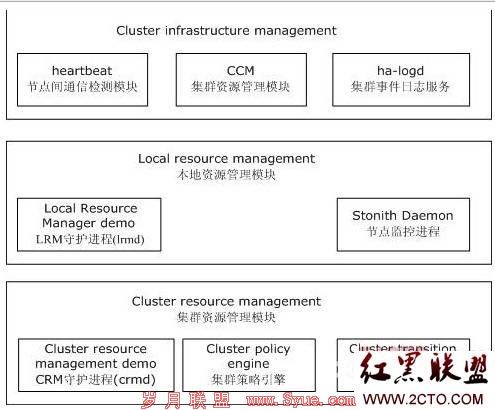
Heartbeat的数据传输流程
1、所有通讯都从 heartbeat 层开始,并且集群中的成员间的通讯也会通过该层。此外,当某个节点断开或恢复时,该层也会提供连通性信息的标记;
2、这些连通性的改变会被送到 membership 层(CCM),该层会在集群中向邻居发送数据包,并指出哪些节点是在当前该层里面的,哪些不是的;
3、一旦它确认新的会员身份,那么 CCM 会通知其他的客户端改变它们自己的会员身份信息。CRM 和 CIB 是 CCM 的两个最重要的客户端。
4、当它从 CCM 接收到一个新的会员信息时,CIB 会从最新的会员信息中进行更新,并通知它下面的客户端一同更新;
5、当 CRM 注意到 CIB 已经更新,它会通知 PE(policy engine)
6、接着,PE 查看 CIB 文件中 status 部分的内容,看看哪些是由 CIB 的 status 部分带过来的(根据配置部分的默认策略)需要进行的工作;
7、PE 会使用这些信息,并连同策略一起创建一个直接的动作图,然后交给 CRM 处理;
8、CRM 把这些动作交给 TE,它会执行这些工作;
9、TE(通过 CRM)让各个 LRM 运行指定的动作;
10、每个动作完成或超时,TE 都会捕获它们的返回值(状态)
11、TE 会持续让 LRM 依照动作图给出的顺序执行相关的操作;当所有的动作完成后,TE会向 CRM 返回报告信息,整个集群各节点更新完毕。
流程图如下
作者“CzmMiao的博客生活”