Ubuntu11.10下安装Hadoop1.0.0(单机伪分布式)
环境配置:Ubuntu11.10,Hadoop1.0.0

安装ssh
1
apt-get install ssh
安装rsync
1
apt-get install rsync
配置ssh免密码登录
1
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2
cat ~/.ssh/id_dsa.pub >>~/.ssh/authorized_keys
验证是否成功
1
ssh localhost
下载Hadoop1.0.0,JDK
新建linux 终端,建立app目录,Java和Hadoop都将安装在此目录中。
1
mkdir /home/app
接下来,安装Java和Hadoop,Hadoop解压即可。
1
cd /home/app
2
chmod +x jdk-6u30-linux-i586.bin
3
./jdk-6u30-linux-i586.bin
4
5
tar zxf hadoop-1.0.0-bin.tar.gz
配置JDK环境变量
1
vi /etc/profile
增加下面语句到最后
1
export JAVA_HOME=/home/app/jdk1.6.0_30
2
export PATH=$JAVA_HOME/bin:$PATH
3
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
接下来开始配置Hadoop
进入Hadoop目录
1
cd /home/app/hadoop-1.0.0
修改配置文件,指定JDk安装路径
1
vi conf/hadoop-env.sh
1
export JAVA_HOME=/home/app/jdk1.6.0_30
修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS的地址和端口号
1
vi conf/core-site.xml
1
<configuration>
2
<property>
3
<name>fs.default.name</name>
4
<value>hdfs://localhost:9000</value>
5
</property>
6
</configuration>
修改Hadoop中HDFS的配置,配置的备份方式默认为3,因为安装的是单机版,所以需要改为1
1
vi conf/hdfs-site.xml
1
<configuration>
2
<property>
3
<name>dfs.replication</name>
4
<value>1</value>
5
</property>
6
</configuration>
修改Hadoop中MapReduce的配置文件,配置的是JobTracker的地址和端口
1
vi conf/mapred-site.xml
1
<configuration>
2
<property>
3
<name>mapred.job.tracker</name>
4
<value>localhost:9001</value>
5
</property>
6
</configuration>
接下来,启动Hadoop,在启动之前,需要格式化Hadoop的文件系统HDFS,进入Hadoop文件夹,输入下面命令
1
bin/hadoop namenode -format
然后启动Hadoop,输入命令
1
bin/start-all.sh
这个命令为所有服务全部启动。
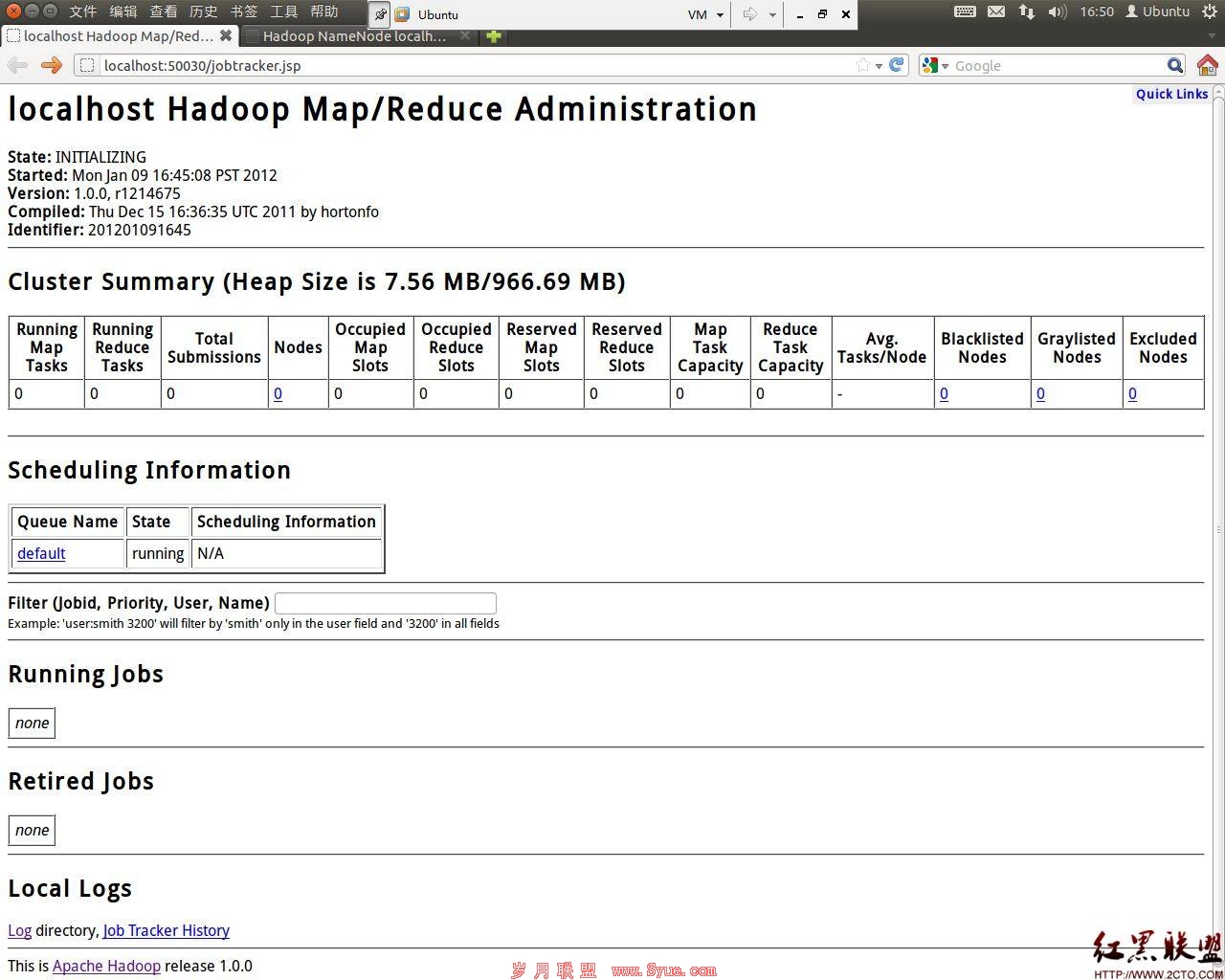
最后,验证Hadoop是否安装成功。打开浏览器,分别输入一下网址:
http://localhost:50030 (MapReduce的Web页面)
http://lcoalhost:50070 (HDfS的web页面)
如果都能查看,说明安装成功。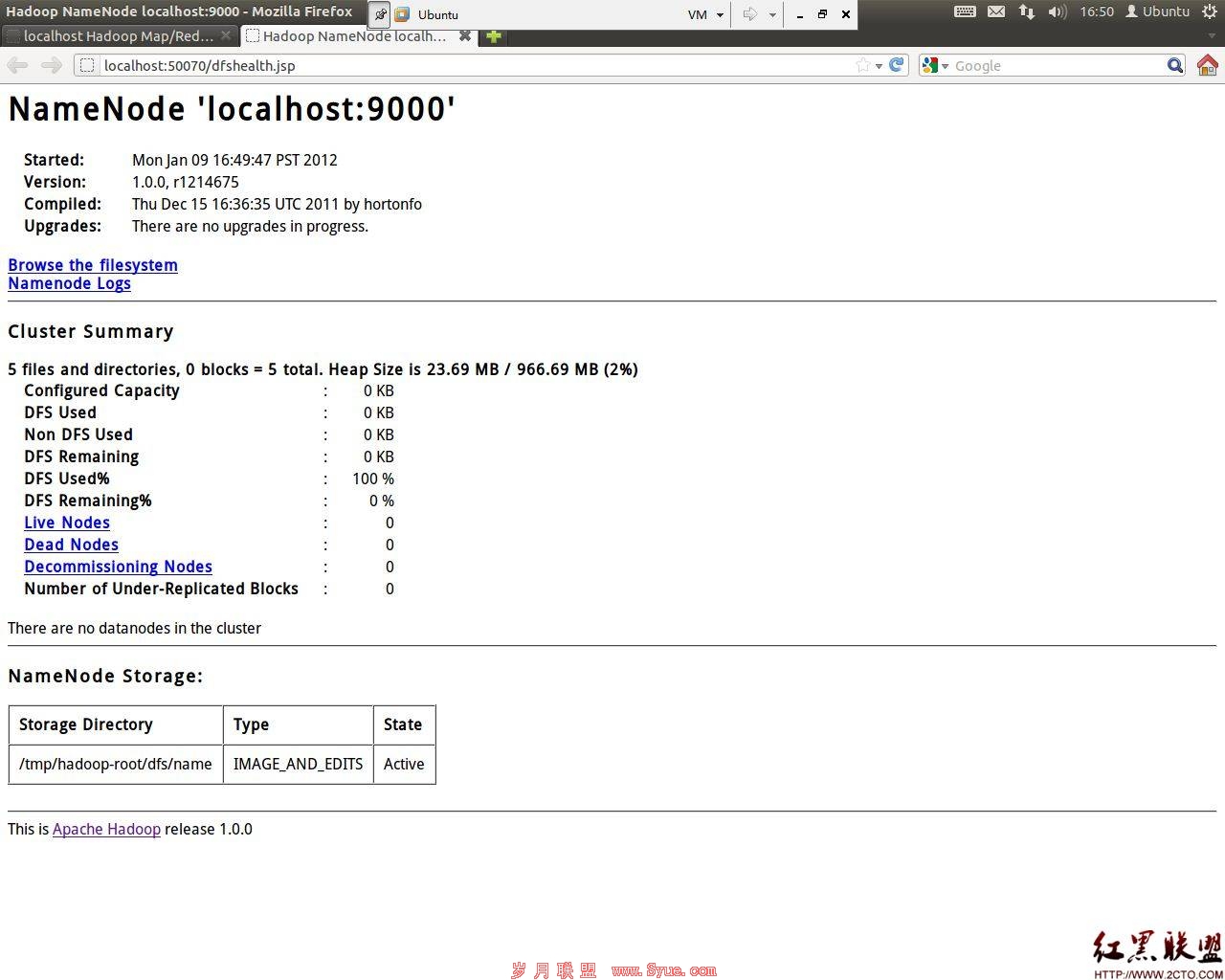
Hadoop分别从三个角度将主机划分为两种角色:
第一,划分为master和slave,即主人与奴隶 。
。
第二,从HDFS的角度,将主机划分为namenode和datanode(在分布式文件系统中,目录的管理很重要,管理目录的就相当于主人,而namenode就是目录管理者)。
第三,从MapReduce的角度,将主机划分为JobTracker和TaskTracker(一个job经常被划分为多个task,从这个角度不难理解它们之间的关系)。