基于说话人聚类的说话人自适应
来源:岁月联盟
时间:2010-08-30
1 引言
近年来,语音识别[1]技术已经日趋成熟,尤其对于特定人的语音识别十分准确。大量实验结果表明,在训练数据都很充分而且各方面的条件都相同时,特定人(Speaker Dependent,SD)识别系统的性能通常好于非特定人(Speaker Independent,SI)系统。然而,当某个特定人的训练数据受限时,由于缺少可靠估计模型所需要的足够多的数据,SD 系统的这种优越性就不能得到保证。说话人自适应就是在一个针对原说话人充分训练的SD 系统中,或是一个对许多说话者充分训练的SI 系统中加入少量新说话人的训练语音数据,通过一定的算法使新老数据结合,从而使系统的识别率接近于对新说话人经过充分训练的SD 系统的水平。 基于说话人聚类的说话人自适应是说话人自适应技术的一种[2],就是将原有的训练数据按照一定的算法聚类,识别时选取待识别语音所属类别的模板进行匹配,可以扩大适用人群,提高系统性能。 2 主要自适应算法 说话人聚类是直接根据说话人的某种特性(或者根据某种度量),将训练集中的说话人根据其语音特性分成若干个子集,每一个子集内的说话人都具有某种度量意义下的相似性,然后专门为每个子集训练声学模型,从而得到一组离散度和混叠度较小的说话人聚类(Speaker Clustering, SC)模型;测试时,先判断待测试的语音属于哪一个说话人子集,然后用这个子集的声学模型来进行测试[3]。 应用较为广泛的是基于说话人特性的和基于模型距离的聚类方法:说话人特性包括说话人的性别、年龄、口音等。这种方法利用先验的说话人的特性,在满足模型训练量的条件下,将说话人分到更小的子集合中。一个最常用的例子就是按性别将说话人进行分类。这种方法通常需要先验知识,也就通常离不开人工干预。的说话人聚类方法直接根据不同说话人对应的声学模型间的距离来进行聚类。首先根据某种模型距离度量方法,建立模型间的距离矩阵,然后完成基于距离矩阵的聚类,其中的关键是声学模型间距离的度量方法。 高斯混合模型(Gaussian Mixture Model, GMM)是基于模型距离说话人聚类常用的模型,GMM的概率密度分布函数是由 个高斯概率密度函数加权求和而得到的,如式(1)所示: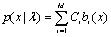 (1) 其中
(1) 其中 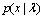 是观测值x 在某个GMM模型下的概率密度函数。x 是 k 维的随机向量,
是观测值x 在某个GMM模型下的概率密度函数。x 是 k 维的随机向量,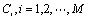 是高斯混元的权值。
是高斯混元的权值。 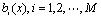 是第 i个单高斯分布概率密度函数,如(2)式:
是第 i个单高斯分布概率密度函数,如(2)式: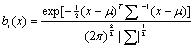 (2) 对高斯混合模型而言,模型距离的定义最终可以归入分布间的距离衡量。其中常用的有如下几种: 欧式距离(Euclidean Distance):
(2) 对高斯混合模型而言,模型距离的定义最终可以归入分布间的距离衡量。其中常用的有如下几种: 欧式距离(Euclidean Distance):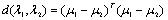 (3) 马氏距离(Mahalanobis Distance)
(3) 马氏距离(Mahalanobis Distance)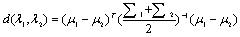 (4) 巴特查里亚距离(Bhattacharyya Distance)
(4) 巴特查里亚距离(Bhattacharyya Distance)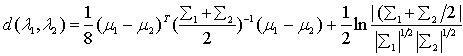 (5) 其中,
(5) 其中, 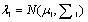 ,
, 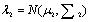 表示两个多维高斯分布,
表示两个多维高斯分布, 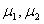 为两个分布的均值向量,
为两个分布的均值向量, 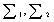 表示两个分布的协方差矩阵。 最大似然线性回归法(Maximum Likelihood Linear Regression, MLLR)是一种基于变换的方法,它采用一组变换描述从初始模型到说话人自适应(Speaker Adaptation, SA)后模型的变换关系,另外MLLR还能对不同的信道及附加噪声有一定补偿作用。一般认为不同说话人之间的差异主要表现在均值矢量上,式(6)为均值转换的估计式。
表示两个分布的协方差矩阵。 最大似然线性回归法(Maximum Likelihood Linear Regression, MLLR)是一种基于变换的方法,它采用一组变换描述从初始模型到说话人自适应(Speaker Adaptation, SA)后模型的变换关系,另外MLLR还能对不同的信道及附加噪声有一定补偿作用。一般认为不同说话人之间的差异主要表现在均值矢量上,式(6)为均值转换的估计式。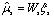 (6) 其中
(6) 其中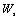 是混合成份s的转移矩阵,
是混合成份s的转移矩阵, 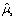 是自适应后的均值后的均值向量,
是自适应后的均值后的均值向量, 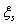 是混合成分s的扩展均值向量,其定义如下:
是混合成分s的扩展均值向量,其定义如下: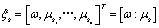 (7)
(7)3 模型间的差别度量
可以将一个GMM的参数看作一组语音特征,考察这组特征在另一个GMM中的输出概率。用输出概率来衡量两个模型间的距离[4]。 其方法如下:把GMMA的M个混元的均值向量当作M个观测向量,这M个观测矢量在GMMB下的概率。类似地,计算GMMB的M个混元的均值向量在GMMA下的概率。定义GMMA和GMMB的单边加权似然度为: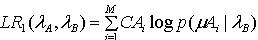 (8) 其中,CAi 表示GMMA第 i 个混元的权值, μAi表示第 i 个混元的均值向量,
(8) 其中,CAi 表示GMMA第 i 个混元的权值, μAi表示第 i 个混元的均值向量,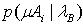 表示GMMA第 i 个混元的均值向量在GMMB下的概率,同理可得GMMB和GMMA的单边加权似然度 :
表示GMMA第 i 个混元的均值向量在GMMB下的概率,同理可得GMMB和GMMA的单边加权似然度 :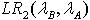 考虑到对称的因素,本文进一步定义GMMA和GMMB的加权交叉似然比为:
考虑到对称的因素,本文进一步定义GMMA和GMMB的加权交叉似然比为: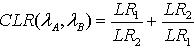 (9)
(9)选择好聚类测度后,一般采用自底向上的方法对备选说话人GMM进行聚类,合并的过程为选择距离最小的两个进行合并,直到得到需要的类数为止。
实验基于汉语大词汇量连续语音识别系统, 在声学层上进行。语音特征参数采用梅尔频标倒谱参数(Mel-frequency cepstrum coefficient, MFCC),共16维。声学模型建立有调的三元音子模型, 识别时测试每句话的汉字识别正确性。 实验系统所用到的训练语音库是中科院训练语音库, 其中女性说话人有 148位,每位100句话;相应的测试语音库分别包含女说话人20位, 每个说话人都是20句测试语音。测试语音库都同其对应的训练语音库是环境匹配的,这样可以排除因为环境差别带来的自适应性能提升, 更加准确地反映说话人聚类的算法效果。全部实验的自适应训练和测试语音长度约为2到3s, 实验以这148位说话人语音训练的SI模型作为基线系统。 实验的基本流程为:首先,对训练语音库中的所有说话人训练出一个基于HMM的SI整体模型,再对库中每位说话人进行单个的GMM模型训练,然后用训练出的所有GMM模型进行说话人聚类,利用聚类后的语料重新训练每一类的GMM模型。对这些新说话人的自适应语音数据作相似性判决,从中选出与每个新说话人最为近似的参考类,最后根据这些参考类的语音特征运用一定的自适应算法对SI模型的部分参数进行修正,合成出新说话人的自适应模型。实验流程如图1所示。
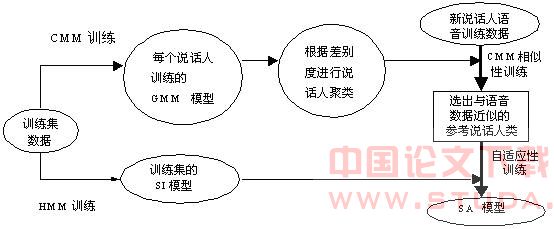
图1 基于差别度量的的说话人自适应(SA)系统实现流程图
表1 参考类别数量对识别的影响
| 汉字正识率% | SI | 3类 | 5类 | 7类 | 9类 | SD |
| PC—1 | 40.43 | 50.86 | 52.43 | 56.98 | 46.24 | 58.46 |
| PC—2 | 44.43 | 54.86 | 50.27 | 57.48 | 51.14 | 60.87 |
| PC—3 | 42.35 | 48.86 | 50.96 | 52.37 | 48.56 | 58.43 |
| PC—4 | 46.78 | 50.86 | 53.29 | 56.99 | 51.36 | 59.77 |
| PC—5 | 41.29 | 50.89 | 52.76 | 55.98 | 46.74 | 59.23 |
| PC—6 | 41.66 | 47.76 | 51.49 | 52.98 | 46.14 | 61.23 |
实验一:对于不同的测试说话人,考察似然判决选出的参考类数量对最后识别结果的影响,PC-1等分别表示不同的测试说话人,自适应语料都为三句。实验结果如表1所示。 从表1中可以看出,随着参考说话人数量的增加,对于不同的测试说话人,其识别性能都有明显提高。但也可以发现,当参考说话人数量超过7类时,其识别性能反而有所下降。其原因是:随着参考类的增加,说话人之间的差别也会明显增加,这种差别有可能抵消根据相似性选择出来的类之间对于特定的测试说话人的近似性。表2 新说话人自适应数据量的不同对识别效果的影响
| 汉字正识率% | 3句 | 5句 | 10句 |
| PC—1 | 56.98 | 57.45 | 57.64 |
| PC—2 | 57.48 | 57.43 | 58.02 |
| PC—3 | 52.37 | 53.44 | 53.67 |
| PC—4 | 56.99 | 57.56 | 57.74 |
| PC—5 | 55.98 | 56.23 | 56.43 |
| PC—6 | 52.98 | 53.43 | 53.60 |