语音合成技术及其应用
来源:岁月联盟
时间:2010-08-30
1 引言
由人工通过一定的机器设备产生出语音称为语音合成(Speech Synthesis)。语音合成是人机语音通信的一个重要组成部分。语音合成研究的目的是制造一种会说话的机器,它解决的是如何让机器象人那样说话的问题,使一些以其它方式表示或存储的信息能转换为语音,让人们能通过听觉而方便地获得这些信息。 语音合成从技术方式讲可分为波形编辑合成、参数分析合成以及规则合成等三种。 波形编辑合成,这种合成方式以语句、短语、词或音节为合成单元,这些单元被分别录音后直接进行数字编码,经适当的数据压缩,组成一个合成语音库。重放时,根据待输出的信息,在语料库中取出相应单元的波形数据,串接或编辑在一起,经解码还原出语音。这种合成方式,也叫录音编辑合成,合成单元越大,合成的度越好,系统结构简单,价格低廉,但合成语音的数码率较大,存储量也大,因而合成词汇量有限。 参数分析合成,这种合成方式多以音节、半音节或音素为合成单元。首先,按照语音理论,对所有合成单元的语音进行分析,提取有关语音参数,这些参数经编码后组成一个合成语音库;输出时,根据待合成的语音的信息,从语音库中取出相应的合成参数,经编辑和连接,顺序送入语音合成器。在合成器中,通过合成参数的控制,将语音波形重新还原出来。 规则合成,这种合成方式通过语音学规则来产生目标语音。规则合成系统存储的是较小的语音单位(如音素、双音素、半音节或音节)的声学参数,以及由音素组成音节、再由音节组成词或句子的各种规则。当输入字母符号时,合成系统利用规则自动地将它们转换成连续的语音波形。由于语音中存在协同发音效应,单独存在的元音和辅音与连续发音中的元音和辅音不同,所以,合成规则是在分析每一语音单元出现在不同环境中的协同发音效应后,归纳其而制定的如共振峰频率规则、时长规则、声调和语调规则等。由于语句中的轻重音,还要归纳出语音减缩规则。 现在展开大量研究和实用的是文语转换系统[1](Text-To- Speech System,TTS System),它是一种以文字串为输入的语音合成系统。其输入的是通常的文本字串,系统中的文本分析器首先根据发音字典,将输入的文字串分解为带有属性标记的词及其读音符号,再根据语义规则和语音规则,为每一个词、每一个音节确定重音等级和语句结构及语调,以及各种停顿等。这样文字串就转变为符号代码串。根据前面分析的结果,生成目标语音的韵律特征,采用前面介绍的合成技术的一种或者是几种的结合,合成出输出语音。 本文所讨论的语音合成应用系统就是一种面向TTS应用的语音系统。该系统的设计目标是作为人机交互的一种反馈手段,用于将机中的数据或状态以语音的形式加以输出。该系统的应用背景是作为卫星测试系统的一个子系统用于增强人机交互能力。通过引入语音合成技术,将原本需要测试人员主动观察的数据、状态或指令等内容以语音的形式即时播报出来,相应的测试人员只需被动收听即可,只有在敏感内容出现时才加以主动观察,从而降低测试人员的工作强度,改善工作环境和条件。在这样的应用背景下,对语音合成系统的要求是响应速度快,计算复杂度和存储空间复杂度低,具有良好的可扩展性和合成语音清晰度高、可懂性强,适于术语、符号和单位的发音合成等。基于以上系统需求,我们开发了专门针对科学应用特别是航空航天领域内常见的科学术语、符号、计量单位和数学公式等文本分析模块,以及新型的基于规则和参数的语音合成技术。2 系统结构
图1中给出了本文讨论的语音合成系统的结构框图。 从外部接口上看,该系统的输入为文本输入接口,用户将要发声的文本内容通过此接口送入系统,输入的文本不需特别的格式;输出为音频输出接口,系统将合成的声音以某种编码方式由此输出;此外系统中所有语音信息模型均存储于语音模型库文件中,各种符号、单位标注、单词字母以及词汇的发音等均存储于词库文件中,这些库文件作为语音合成系统的内部输入。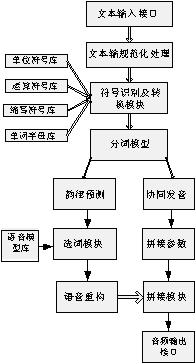
3 声学单元的选择及生成
为使合成语音具有较高的清晰度、可懂度以及自然度,通常采取基于波形的语音合成技术。波形拼接语音合成中的合成单元是从原始自然语音中切分出来的,保留了自然语音的一些韵律特征。根据自然语言的语音和韵律规律,存储适当的语音基元,使这些单元在确定的存贮容量下具有最大的语音和韵律覆盖率。合成时经过声学单元选择、波形拼接、平滑处理等步骤后输出语音。通过精心设计语料库,并根据语音和韵律规则从音库中挑出最适合的声学单元,使系统输出高质量的语音。 常见的语音单元候选可以有词组、音节、音素和双音素等。就词组而言,无论是中文还是西方语系,都和确定的语义相对应,因此使用词组作为声学单元可以比较容易的解决合成语音的可懂度问题[2],但是由于词组的类别非常多,而且在不同韵律环境下有着明显不同的表现,这样会造成所需的声学单元趋向于无穷大。所谓音节,一般都是由元音和辅音构成的,元音是音节的主干部分[3]。以汉语为代表的一些东方语系,音节数目较少,而且音节基本上是“辅音-元音”结构,但是对于一些西方语言,音节数目较多,结构比较复杂,而且使用它并不但不能避免大多数协同发音的影响,而且会引起音库容量的急剧增大。音素是最小发音单位,可以使语料库设计时的灵活性好,但由于音素受相邻语音环境的协同发音影响很大,对这些影响考虑的不合理时,就会造成音库在语音和韵律上的不平衡。另外在挑选单元时,由于音素的声学变体很多,所选择的样本不合适时,会导致相邻音素间存在基频和共振峰上不连续,需要采用谱平滑法进行处理,这必然会降低合成音质。 综合上述对音节、词组、音素的分析可以知道,它们各有优缺点,因此在构造波形拼接所需要的语料库时,可以结合不同类型样本的优缺点,例如对于自然语流中经常出现的一些协同发音强的音素、音节组合,在通过波形拼接形成目标语音时,应该尽量避免在这些协同发音影响大的音素组合之间进行拼接,否则单元挑选的稍有不合适,就会造成听觉上的难以接受。所以在构造实用合成系统时所采取的声学单元的类型和长度都将是不固定的[4]。 在选择声学单元构造语音库时,通常利用某种损失度函数来描述具有相同大小语音库的合成能力。一个典型的损失度函数可以表达为: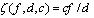 (1) 其中f为当前声学单元的词频,d为声学单元的预测时长,c为该单元中所包含的音素之间协同发音的大小[4]。在不考虑韵律条件下,构造由声学单元组成的语音库时,应使由(1)表示的损失度函在该语音库上的取值最小为目标。 用于拼接的声学单元通常由连续语流中切分获得。通过检索含有大量航天、通信、机以及卫星领域内关键字的,并通过对这些文献进行文本处理,将文献切分成词和句。通过对词汇的统计可以得到词频信息,并在词频信息的指导下挑选由文献获得的句子,使得选出的句子对高频词具有较好的覆盖,这些挑选出来的句子成为稍后需要录制的脚本。 挑选合适的播音员,对照脚本进行合理朗读,并且录音。将录音所得的语音波形数据按脚本以及声学单元的划分进行切分,通常对于汉语可以切分为词、字(CV结构)而通常需要切分到词以及少量音素或双音素,从而构成发声单元库。对切分得到的声学单元按其在原句子中的位置(前中后)以及前后相连的字词进行标注。这些标注信息对选词模块的判决提供依据。
(1) 其中f为当前声学单元的词频,d为声学单元的预测时长,c为该单元中所包含的音素之间协同发音的大小[4]。在不考虑韵律条件下,构造由声学单元组成的语音库时,应使由(1)表示的损失度函在该语音库上的取值最小为目标。 用于拼接的声学单元通常由连续语流中切分获得。通过检索含有大量航天、通信、机以及卫星领域内关键字的,并通过对这些文献进行文本处理,将文献切分成词和句。通过对词汇的统计可以得到词频信息,并在词频信息的指导下挑选由文献获得的句子,使得选出的句子对高频词具有较好的覆盖,这些挑选出来的句子成为稍后需要录制的脚本。 挑选合适的播音员,对照脚本进行合理朗读,并且录音。将录音所得的语音波形数据按脚本以及声学单元的划分进行切分,通常对于汉语可以切分为词、字(CV结构)而通常需要切分到词以及少量音素或双音素,从而构成发声单元库。对切分得到的声学单元按其在原句子中的位置(前中后)以及前后相连的字词进行标注。这些标注信息对选词模块的判决提供依据。4 韵律的生成
韵律的声学参数一般包括基频、时长、能量,对于一个TTS系统,韵律生成和控制是十分重要的。韵律参数对于控制合成语音的节奏、语气语调、情感等具有重要意义,而对汉谱普通话,基频是和声调直接相关的物理参数。汉语的构成原则可归结如下:由音素构成声母或韵母,韵母带上声调后成为调母,由单个调母或由声母与调母拼接成为音节。汉语有阴平、阳平、上声、去声、轻声5个调,1200多个有调音节。一个音节就是一个字的音,即音节字。由音节字构成词,最后再由词构成句子[5]。 基于规则的韵律生成。通过对汉语语音学和语言学的研究一些通用的韵律规则,利用这些先验知识,可以建立一个基于规则的韵律生成系统。通常规则系统包括两个方面:一是通用规则,比如四个调的基本形状,上声连接的变调规则,时长变化,语气语调的音高变化等;二是目标说话人的特定韵律规则,比如个人的基本调高、调域、语速和停顿等。此外在连续语流中,每个字的发音是会相互影响的,连续语流中一个字的发音的声调与这个字单独发音时的声调会有所不同,在合成的连续语流中,只有具有这种声调变化才能使合成的语音具有较好的可懂度,否则将只会是单字语音的生硬连接。汉语普通话语句中的变调以二字词的变调最为主,因为二字词所占比例约为74.3%。它的调型基本上是两个原调型的相连的序列,但受连读影响使前后两调或缩短、或变低。 基于机器学习的韵律生成。虽然目前已经得到了许多关于韵律的规则,但这些规则对于形成非常贴近的韵律还相差很远。为能够发觉隐藏而且难以描述的韵律规则通常利用机器学习的方法来实现韵律的生成。常用的算法模型有隐马尔可夫模型(HMM)、人工神经(ANN)、支持向量机(SVM)以及决策树等[5][6]。 基于参数化模型的韵律生成。基于机器学习的韵律模型提取一些人工无法分析的细则,大人降低人工参与分析的工作量,但这种方法同时也存在如下问题:首先,一般的学习算法都要求比较多的数据资源,特别是属性特征比较多的时候;其次,如果己有数据资源分布不均匀,将造成训练的整体偏差,影响分析结果;再次,专家知识没有很好的结合利用进来,是一种信息浪费;第四,训练模型没有和语言特征和人的感知挂钩,无法进行转移和调整。基频和时长是影响人的韵律听感的直接声学参数,两者都是随时间变化和环境变化的。参数模型利用先验知识,先分析基频时长和语言特征、人的听感的关系,对此关系建摸,提取基频时长和语言特征及人的听感直接相关的参数。这样的模型有效利用了专家知识,就可以用不多的数据训练出文本语言特征和参数的关系,同时通过调整模型参数就可以达到改变听感的韵律特征的目的[7]。 Fujisaki模型是一种广泛使用的基频参数化模型[8][9],它主要通过模拟人的发音机理来预测基频的变化。Fujisaki认为基频的改变主要有两个原因:韵律短语边界(Phrase) 的影响和音节调(Accent)的影响。基频曲线的产生是按照声带振动的机理,以Phrase和Accent作为预测系统的输入,以基频曲线作为系统的输入,其中以脉冲信号的形式产生Phrase形状,以阶梯函数产生Accent形状。在该模型下基频曲线可以表示为: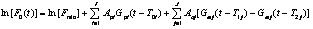 (2) 其中函数Gpi(t)以及Gaj(t)的表达式分别为:
(2) 其中函数Gpi(t)以及Gaj(t)的表达式分别为: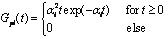 (3)
(3) 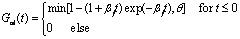 (4) 在表达式(2)、(3)及(4)中各参数含义如表1中所示。表1 Fujisaki韵律模型参数
(4) 在表达式(2)、(3)及(4)中各参数含义如表1中所示。表1 Fujisaki韵律模型参数| Fmin | 基频最小值 | αi | 第i个Phrase命令控制系数 |
| I | Phrase元素数量 | βj | 第j个Accent命令控制系数 |
| J | Accent元素数量 | θ | Accent命令最大值参数 |
| T0i | 第i个Phrase命令的时间标记 | Api | 第i个Phrase命令幅度 |
| T1j | 第j个Accent命令开始时间 | Aaj | 第j个Accent命令幅度 |
| T2j | 第j个Accent命令结束时间 |