关联规则挖掘技术在人寿保险行业中的应用
来源:岁月联盟
时间:2010-08-30
1 引言
近年来,数据密集型的保险行业经过多年的运营,也已经积累了海量的数据,这些数据是公司的重要财富。要从这些大量数据中获取能给公司带来无限商机的有价值信息,急需更高效的数据处理方法和技术。此时数据挖掘技术显示出了它特有的优越性。12 关联规则挖掘技术
数据挖掘(Data Mining)是一个利用各种分析技术和工具从大量数据中提取有用知识的过程。它是一门交叉学科,把人们对数据的应用从低层次的简单查询,提升到从数据中挖掘知识,提供决策支持。它包含很多技术与方法,其中关联规则挖掘是一项非常重要的技术,是数据挖掘的一个主要研究方向。迄今为止,关联规则挖掘已经被应用到很多领域,例如零售业、市场营销、医学等,为各个领域的决策支持提高了一个有效的手段。 关联规则挖掘是由R.A grawal等人提出来的,关联规则是描述数据库中数据项之间某种潜在关系的规则[1],它的基本概念为:设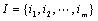 为数据项集合,设D为与任务相关的数据集合,也就是一个交易数据库,其中的每个交易T是一个数据项子集,即
为数据项集合,设D为与任务相关的数据集合,也就是一个交易数据库,其中的每个交易T是一个数据项子集,即 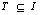 ;每个交易均包含一个识别编号TID。设A为一个数据项集合,当且仅当
;每个交易均包含一个识别编号TID。设A为一个数据项集合,当且仅当 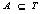 时就称交易T包含A。一个关联规则就是具有“
时就称交易T包含A。一个关联规则就是具有“ 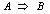 ”形式的蕴含式;其中有
”形式的蕴含式;其中有 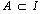 ,
, 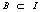 且
且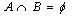 。规则
。规则 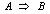 在交易数据集D中成立,具有支持度s,其中s是D中交易包含
在交易数据集D中成立,具有支持度s,其中s是D中交易包含 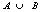 (即A和B二者)的百分比,这是概率P() 。如果D中包含A的事务同时也包含B的百分比是c,则规则
(即A和B二者)的百分比,这是概率P() 。如果D中包含A的事务同时也包含B的百分比是c,则规则 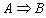
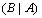 。即Support P()= P () ,Confidence P ()=p()。 满足最小支持度阈值和最小置信度阈值的关联规则就称为强规则。这两个阈值均在0%到100%之间。挖掘关联规则主要包含以下二个步骤[2]: (1)发现所有的频繁项集,根据定义,这些项集的支持度至少应等于(预先设置的)最小支持度阈值; (2)根据所获得的频繁项集,产生相应的强关联规则。根据定义这些规则必须满足最小支持度阈值和最小置信度阈值。
。即Support P()= P () ,Confidence P ()=p()。 满足最小支持度阈值和最小置信度阈值的关联规则就称为强规则。这两个阈值均在0%到100%之间。挖掘关联规则主要包含以下二个步骤[2]: (1)发现所有的频繁项集,根据定义,这些项集的支持度至少应等于(预先设置的)最小支持度阈值; (2)根据所获得的频繁项集,产生相应的强关联规则。根据定义这些规则必须满足最小支持度阈值和最小置信度阈值。3 关联规则挖掘技术在人寿保险行业中的应用
人寿保险行业在日常的经营过程中,经常会遇到这样一些问题:如何能更好的理解客户,挽留有价值的投保人,对不同行业的人、不同年龄段的人、处于不同社会阶层的人的保险金额度该如何确定。这些问题都是影响公司运营的重要因素。为了更好的掌握投保人的特点及合理的制定保险金额度,可以利用关联规则挖掘来发现投保人与索赔的关系,分析具有什么特征的投保人曾经向保险公司索赔过。3.1 关联规则挖掘的基础数据
为了研究投保人与索赔的关系,我们从某城市一家人寿保险公司的历史保单数据库中提取出相关数据,把其整合到关系表中进行关联规则挖掘。下面的表1为整合之后的信息。3.2 基于概化的数据预处理
为了更好的进行关联规则挖掘,要对表1中的基础信息进行基于概化的数据预处理,具体的概化处理方法为: ① 用符号A描述年龄,把年龄进行分段概化为:A1(£25岁),A2(25-35岁),A3(35-45岁),A4(³45岁)。 ② 用符号B描述性别,B1表示“女”,B2表示“男”。 ③ 用符号C描述健康状况,C1表示良好,C2表示一般,C3表示较差。 ④ 用符号D表示工作单位,工作单位为外资的表示为D1,非外资企业的表示为D2。 ⑤ 用符号E表示工资档次,分别概化为:E1(高),E2(较高),E3(中),E4(低)。 ⑥ 用符号F表示投保人是否曾向保险公司索赔过,F1表示曾经索赔过,F2表示未曾索赔过。根据上述方法对表1中的数据进行概化的结果如表2所示:表1 基础数据
| 编号 | 年龄 | 性别 | 健康状况 | 工作单位 | 工资档次 | 是否曾索赔 |
| 001 | 47 | 男 | 一般 | 摩碧聂斯电装有限公司 | 高 | 是 |
| 002 | 36 | 女 | 良好 | 新世纪学校 | 中 | 否 |
| 003 | 29 | 女 | 良好 | 府新大厦 | 较高 | 否 |
| 004 | 49 | 男 | 较差 | 昌美达 | 低 | 是 |
| 005 | 41 | 男 | 一般 | 新阳光 | 高 | 否 |
| 006 | 50 | 男 | 良好 | 志高缝纫 | 中 | 是 |
| 007 | 24 | 男 | 良好 | 《摩托车》杂志社 | 中 | 否 |
| 008 | 45 | 女 | 一般 | 蒲项不锈钢 | 低 | 是 |
| 009 | 23 | 女 | 良好 | 雅倩美发中心 | 较高 | 否 |
| 010 | 46 | 男 | 较差 | 易和基业 | 较高 | 是 |
| 编号 | 年龄 | 性别 | 健康状况 | 工作单位 | 工资档次 | 是否曾索赔 |
| 001 | A4 | B2 | C2 | D1 | E1 | F1 |
| 002 | A3 | B1 | C1 | D2 | E3 | F2 |
| 003 | A2 | B1 | C1 | D2 | E2 | F2 |
| 004 | A4 | B2 | C3 | D1 | E4 | F1 |
| 005 | A3 | B2 | C2 | D2 | E1 | F2 |
| 006 | A4 | B2 | C1 | D1 | E3 | F1 |
| 007 | A1 | B2 | C1 | D2 | E3 | F2 |
| 008 | A4 | B1 | C2 | D1 | E4 | F1 |
| 009 | A1 | B1 | C1 | D2 | E2 | F2 |
| 010 | A4 | B2 | C3 | D1 | E2 | F1 |
3.3 关联规则挖掘过程
由关联规则的概念和表2的概化结果,可得出项目集合为{A1,A2,A3,A4,B1,B2,C1,C2,C3,D1,D2,E1,E2,E3,E4,F1,F2},我们目的是要分析投保人的各方面情况和索赔情况之间内在的关联规则。假设关联规则的支持度至少为40%,置信度至少为80%。进行关联规则挖掘过程如下: (1)首先利用基于事物压缩的Apriori算法找出频繁项集如图1所示。 (2)找出支持度至少为40%而且置信度至少为80%的强关联规则。由以上两步我们得出的和索赔情况有关而且实用的强关联规则为:(A4,B2,D1)→F1 (置信度为100%,支持度为40%)此规则可解释为投保单上年龄大于45岁,工作单位是外资的男性投保人,几乎都曾经向保险公司索赔过。3.4 关联规则挖掘结果的指导作用
根据挖掘结果,我们分析原因,发现对于工作在外资企业,年龄大于45岁的男性投保人来说,由于在外资企业工作压力大,生活节奏快,同时45岁左右的中年男性正处于家庭负担最严重阶段,生活压力也很大,这些因素导致这部分人群的健康状况不好,因此索赔率也相对比较高,保险公司可以考虑相对提高对这部分人群的保险金额。此结论对于保险公司的增值服务具有重要的指导意义。4 结束语
本文利用关联规则挖掘方法分析出了隐藏在人寿保险数据背后的有效信息,然而关联规则挖掘技术在人寿保险行业中的应用不只是文中提到的这几个方面,例如利用关联规则挖掘进行险种关联分析,即分析购买了某种保险的人是否同时购买另一种保险。我们应该利用数据挖掘技术来分析人寿保险行业中的海量历史数据,进而从中获取有意义的信息,并从中挖掘出业务的内在,以达到提高效益、减低成本、防范风险的目的。数据挖掘技术是具有广阔前景的数据处理与分析技术,它将在有大量信息的保险行业中发挥不可估量的作用。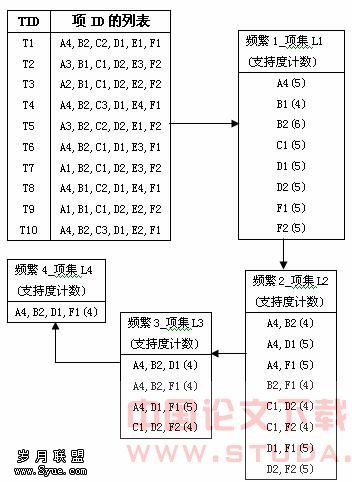
[1] Jiawei Han .数据挖掘概念与技术,北京:机械出版社,2004.6:149—180[2] 陈文伟,黄金才.数据仓库与数据挖掘,北京:人民邮电出版社,2004.1:143—149[3] 吉根林,帅克,孙志辉.数据挖掘技术及其应用[J].南京师大学报,2000.23(2)[4] 李俊斌.浅析数据挖掘技术在保险业中的应用[J].大众科技,2006.88(2)[5] Alex Berson, Stephen Smith, Kurt . Building Data Mining Applications for CRM[M]. 北京: 人民邮电出版社, 2001
上一篇:基于LOD的三维地形可视化