量化容差关系的进一步研究
来源:岁月联盟
时间:2010-08-30
1 引言
粗糙集理论[1](Rough Sets Theory,简称RST)是一种用于处理含糊和不精确性问题而又不同于模糊集理论的新型数学工具。 Pawlak提出的RST仅仅适用于所有属性值都已知的完备信息系统,然而现实世界中由于各种原因存在着大量的不完备信息系统(Incomplete Information Systems[2],简称IIS),因此如何使用RST处理IIS正逐渐成为RST研究领域的一个热点问题。使用RST处理IIS,大致可以分为两种方式:1、间接处理,即数据补齐或数据删除方法;2、直接处理,对基于不可分辨关系(等价关系)的RST模型进行扩充。由于间接处理方法会损害到数据的原有分布特征,挖掘出的规则往往带有不确定性,因此使用直接方法处理IIS就具有其独特的优势。 随着理论研究的不断深入,目前已经涌现出了很多扩展RST模型以处理IIS,如容差关系模型[2]、量化容差关系模型[3]、限制容差关系模型[4]、相似关系模型[3]等等。由于量化容差关系是一种推广的容差关系,量化容差类是一个用关于元素的容差度作为成员函数的模糊集合,因此文中主要围绕量化容差关系在RST中的若干问题进行讨论。2 量化容差关系
2.1 容差关系
一个IIS是一个二元组: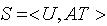 ,其中 U 是一个被称为论域的非空有限的对象集合;AT是一个非空有限的属性集合。 对于任意 a∈AT,有 a:U→Va,其中Va 是属性 a 的值域(可包含空值,文中用〝*〞表示);V 为全体属性值域,即
,其中 U 是一个被称为论域的非空有限的对象集合;AT是一个非空有限的属性集合。 对于任意 a∈AT,有 a:U→Va,其中Va 是属性 a 的值域(可包含空值,文中用〝*〞表示);V 为全体属性值域,即 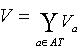 ;定义 f为信息函数,对于
;定义 f为信息函数,对于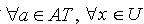 ,有 f(x,a)∈Va.定义1.1 令S为一IIS,属性集合
,有 f(x,a)∈Va.定义1.1 令S为一IIS,属性集合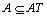 ,则由 A 决定的容差关系如下表示:
,则由 A 决定的容差关系如下表示: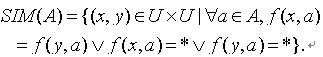
2.2 量化容差关系
量化容差关系是容差关系的推广,在容差关系中加入了描述对象之间的相似程度这一参考因素。令S 为一IIS,其中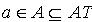 .假设对于
.假设对于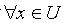 , x 在属性 a 上取值的概率为
, x 在属性 a 上取值的概率为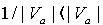 ( 表示集合Va 的基数).定义1.2 令S为一IIS,对于
( 表示集合Va 的基数).定义1.2 令S为一IIS,对于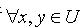 ,x,y 在属性集合 上取等值的概率(容差度)为
,x,y 在属性集合 上取等值的概率(容差度)为 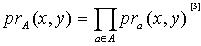 ,
,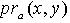 表示x,y在属性a上取等值的概率,其取值如下所示:
表示x,y在属性a上取等值的概率,其取值如下所示: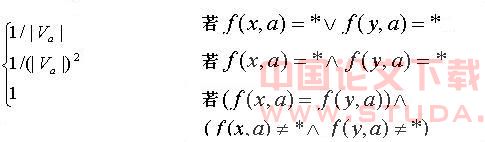 定义1.3 令S 为一IIS, ,容差度阈值 λ∈[0,1],则量化容差关系
定义1.3 令S 为一IIS, ,容差度阈值 λ∈[0,1],则量化容差关系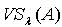 定义如下:
定义如下: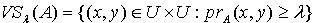
,容差度阈值 λ∈[0,1],对于 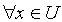 , x关于
, x关于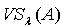 的量化容差类
的量化容差类 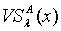 定义为:
定义为: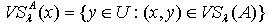 . 一般来说,在IIS中,量化容差关系对于论域构成了一个覆盖而非划分,若令
. 一般来说,在IIS中,量化容差关系对于论域构成了一个覆盖而非划分,若令 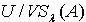 表示覆盖,则
表示覆盖,则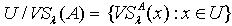 .
.3 基本概念
a) 近似精度及粗糙熵定义2.1 令 S为一IIS, ,容差度阈值 λ∈[0,1],对于 , X关于 的上、下近似集合可表示为 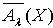 和
和 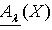 ,其中
,其中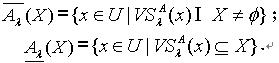 定理2.1 令 S为一IIS,属性集合 ,若容差度阈值 λ1,λ2∈[0,1],且
定理2.1 令 S为一IIS,属性集合 ,若容差度阈值 λ1,λ2∈[0,1],且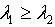 ,则
,则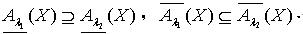
,因为 ,所以 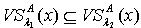 .若
.若 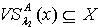 ,则必定有
,则必定有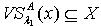 ;反之则不一定成立。所以
;反之则不一定成立。所以 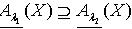 .同理可以证得
.同理可以证得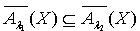 . 定理2.1说明粗糙集合的下近似集随着容差度阈值的减小而不断减小,上近似集却随着容差度阈值的减小而不断增大。定义2.2 令 S为一IIS, 且
. 定理2.1说明粗糙集合的下近似集随着容差度阈值的减小而不断减小,上近似集却随着容差度阈值的减小而不断增大。定义2.2 令 S为一IIS, 且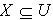 ,容差度阈值 λ∈[0,1],则 X关于 的近似精度
,容差度阈值 λ∈[0,1],则 X关于 的近似精度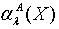 ,粗糙性
,粗糙性 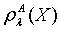 分别如下所示:
分别如下所示: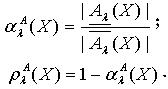 定理2.2 令 S为一IIS,属性集合 ,容差度阈值 λ1,λ2∈[0,1]且 ,则对于
定理2.2 令 S为一IIS,属性集合 ,容差度阈值 λ1,λ2∈[0,1]且 ,则对于 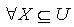 ,有
,有 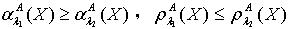 .证明:利用定理2.1的结果,易证。 定理2.2说明随着容差度阈值的减小,粗糙集合的近似精度在不断减小,粗糙性在不断增大。定义2.3 令S 为一IIS,属性集合 ,容差度阈值 λ∈[0,1],则知识A 的粗糙熵
.证明:利用定理2.1的结果,易证。 定理2.2说明随着容差度阈值的减小,粗糙集合的近似精度在不断减小,粗糙性在不断增大。定义2.3 令S 为一IIS,属性集合 ,容差度阈值 λ∈[0,1],则知识A 的粗糙熵 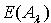 定义为:
定义为: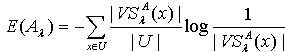 定理2.3 令 S为一IIS, ,若容差度阈值λ1,λ2∈[0,1]且 ,则
定理2.3 令 S为一IIS, ,若容差度阈值λ1,λ2∈[0,1]且 ,则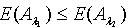 .证明:对于 ,因为 ,所以
.证明:对于 ,因为 ,所以 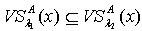 .于是可以得到不等式
.于是可以得到不等式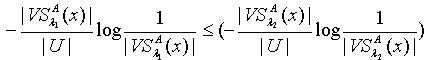 .扩充这个不等式就可以得到 . 为了对粗糙集的不确定性进行更为精确的测量,已有学者开始研究各种不同的粗糙集的粗糙熵[5]。根据量化容差关系,可以定义如下两种不同形式的粗糙集的粗糙熵。定义2.4 令 S为一IIS,属性集合 ,容差度阈值λ∈[0,1],对于 , X关于知识A 的粗糙熵
.扩充这个不等式就可以得到 . 为了对粗糙集的不确定性进行更为精确的测量,已有学者开始研究各种不同的粗糙集的粗糙熵[5]。根据量化容差关系,可以定义如下两种不同形式的粗糙集的粗糙熵。定义2.4 令 S为一IIS,属性集合 ,容差度阈值λ∈[0,1],对于 , X关于知识A 的粗糙熵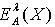 定义为:
定义为: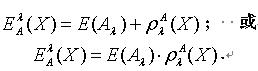 定理2.4 令 S为一IIS,属性集合 ,若容差度阈值 λ1,λ2∈[0,1]且 ,则对于 有
定理2.4 令 S为一IIS,属性集合 ,若容差度阈值 λ1,λ2∈[0,1]且 ,则对于 有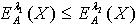 . 证明:利用定理2.2及2.3的结果,易证。 作为一种特殊的容差关系,量化容差关系当然也满足容差关系下的一些性质,如定理2.5所示。定理2.5 令 为一IIS,属性集合
. 证明:利用定理2.2及2.3的结果,易证。 作为一种特殊的容差关系,量化容差关系当然也满足容差关系下的一些性质,如定理2.5所示。定理2.5 令 为一IIS,属性集合 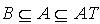 ,若容差度阈值λ∈[0,1],则
,若容差度阈值λ∈[0,1],则 ,
, 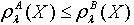 ,
,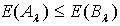 ,
, 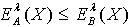 . b) 知识依赖 利用对象的分类,可以方便地研究两个不同属性子集,即知识之间的依赖关系[6]。定义2.5 令 S为一IIS,容差度阈值 λ1,λ2∈[0,1],属性集合 B对于属性集合A 的依赖关系表示为
. b) 知识依赖 利用对象的分类,可以方便地研究两个不同属性子集,即知识之间的依赖关系[6]。定义2.5 令 S为一IIS,容差度阈值 λ1,λ2∈[0,1],属性集合 B对于属性集合A 的依赖关系表示为 ,当且仅当对于
,当且仅当对于 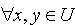 ,若
,若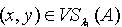 ,则必定有
,则必定有 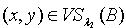 .定义2.6 令 S为一IIS,容差度阈值 λ1,λ2∈[0,1],则知识 A与B 之间存在等价依赖
.定义2.6 令 S为一IIS,容差度阈值 λ1,λ2∈[0,1],则知识 A与B 之间存在等价依赖  当且仅当
当且仅当  且
且 . 知识的部分依赖表示知识之间的推理可以是部分的,换言之,只有部分关于B 的知识可以从 A推导出来。知识的部分依赖一般用知识的正区域来表示。定义2.7 令 S为一IIS,
. 知识的部分依赖表示知识之间的推理可以是部分的,换言之,只有部分关于B 的知识可以从 A推导出来。知识的部分依赖一般用知识的正区域来表示。定义2.7 令 S为一IIS,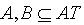 ,容差度阈值 λ1,λ2∈[0,1],则知识 A对于知识 B的正区域
,容差度阈值 λ1,λ2∈[0,1],则知识 A对于知识 B的正区域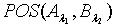 表示为:
表示为: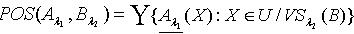
,容差度阈值 λ1,λ2∈[0,1],知识 B以程度 k依赖于知识 A,表示为 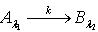 ,其中
,其中 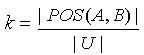 . 当k=0 时,知识依赖表示为
. 当k=0 时,知识依赖表示为 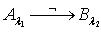 ;当k=1 时,知识依赖表示为
;当k=1 时,知识依赖表示为 .定理2.6 令 S为一IIS, ,容差度阈值 λ1,λ2,λ3∈[0,1]且,如果有知识依赖
.定理2.6 令 S为一IIS, ,容差度阈值 λ1,λ2,λ3∈[0,1]且,如果有知识依赖 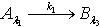 ,
, 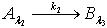 ,那么
,那么 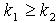 .证明:对于
.证明:对于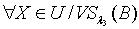 ,根据定理2.1,因为
,根据定理2.1,因为 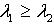 ,所以
,所以 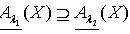 ,即
,即 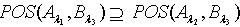 .所以 . 定理2.6说明随着知识依赖的被依赖部分的容差度阈值逐渐减少,依赖部分对于被依赖部分的依赖程度逐渐减小。定理2.7 令 S为一IIS, ,容差度阈值λ1,λ2,λ3∈[0,1]且
.所以 . 定理2.6说明随着知识依赖的被依赖部分的容差度阈值逐渐减少,依赖部分对于被依赖部分的依赖程度逐渐减小。定理2.7 令 S为一IIS, ,容差度阈值λ1,λ2,λ3∈[0,1]且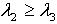 ,如果有知识依赖
,如果有知识依赖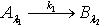 ,
, 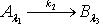 ,那么
,那么 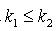 .证明:对于 ,因为 ,所以
.证明:对于 ,因为 ,所以 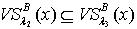 .对于
.对于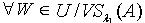 ,若
,若 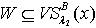 ,则
,则 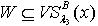 ,反之则不一定成立,所以
,反之则不一定成立,所以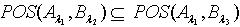 ,即 . 定理2.7说明随着知识依赖的依赖部分的容差度阈值逐渐减少,依赖部分对于被依赖部分的依赖程度逐渐增大。定理2.8 令 S为一IIS,若 且容差度阈值λ∈[0,1],则有知识依赖
,即 . 定理2.7说明随着知识依赖的依赖部分的容差度阈值逐渐减少,依赖部分对于被依赖部分的依赖程度逐渐增大。定理2.8 令 S为一IIS,若 且容差度阈值λ∈[0,1],则有知识依赖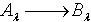 .证明:对于 ,若
.证明:对于 ,若 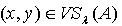 ,则
,则 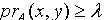 .因为 ,所以
.因为 ,所以 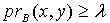 ,即
,即 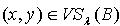 .满足定义2.5,所以 .定理2.9 令 S为一IIS,
.满足定义2.5,所以 .定理2.9 令 S为一IIS,  ,容差度阈值 λ1,λ2∈[0,1],如果有知识依赖
,容差度阈值 λ1,λ2∈[0,1],如果有知识依赖 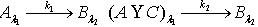 ,那么 .证明:对于 ,若
,那么 .证明:对于 ,若 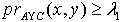 ,则
,则 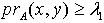 ,即
,即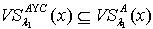 .对于
.对于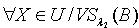 ,可以得到
,可以得到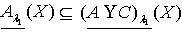 ,于是有
,于是有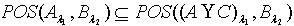 ,即 .定理2.10 令 S为一IIS, ,容差度阈值 λ1,λ2∈[0,1],如果有知识依赖
,即 .定理2.10 令 S为一IIS, ,容差度阈值 λ1,λ2∈[0,1],如果有知识依赖 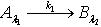 ,
, 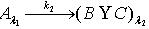 ,那么 .证明:类似于定理2.9的证明,对于
,那么 .证明:类似于定理2.9的证明,对于 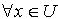 ,有
,有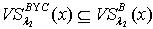 . 对于
. 对于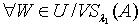 ,若
,若 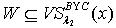 ,则
,则 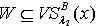 ,反之则不一定,所以
,反之则不一定,所以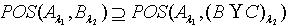 ,即 .
,即 .4 基于量化容差关系的覆盖
1) 覆盖粒度定义3.1 在一IIS中,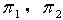 , 分别为论域 U 的两种不同覆盖,若对于
, 分别为论域 U 的两种不同覆盖,若对于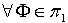 ,必定
,必定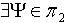 使得
使得 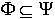 ,并且对于
,并且对于 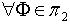 ,必定
,必定 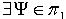 使得
使得 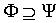 ,则称覆盖
,则称覆盖 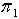 比覆盖
比覆盖 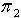 更为精细,或者说 比 更为粗糙,表示为 <.定理3.1 令 S为一IIS, ,若容差度阈值 λ1,λ2∈[0,1]且 ,则
更为精细,或者说 比 更为粗糙,表示为 <.定理3.1 令 S为一IIS, ,若容差度阈值 λ1,λ2∈[0,1]且 ,则 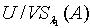 <
<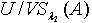 .证明:对于 ,因为 ,所以
.证明:对于 ,因为 ,所以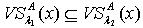 .满足定义3.1,所以
.满足定义3.1,所以 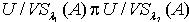 .定理3.2 令 S为一IIS,容差度阈值λ∈[0,1],若 ,则
.定理3.2 令 S为一IIS,容差度阈值λ∈[0,1],若 ,则 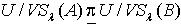 .证明:对于 ,因为 ,所以
.证明:对于 ,因为 ,所以 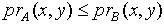 ,即
,即 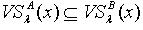 ,满足定义3.1,所以
,满足定义3.1,所以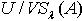 <
<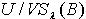 定理3.1和3.2说明在量化容差关系下,随着容差度阈值的减小,覆盖的精细程度也在不断地减小;随着知识的不断增加,覆盖的精细程度不断地增大。 2) 覆盖修正 令
定理3.1和3.2说明在量化容差关系下,随着容差度阈值的减小,覆盖的精细程度也在不断地减小;随着知识的不断增加,覆盖的精细程度不断地增大。 2) 覆盖修正 令 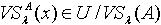 ,由定义1.4可知,
,由定义1.4可知, 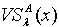 中的所有元素都只是与 x之间存在量化容差关系,而对于
中的所有元素都只是与 x之间存在量化容差关系,而对于 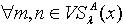 ,并不一定能保证 m,n之间也存在着量化容差关系。因此有必要重新定义由量化容差关系所产生的论域覆盖,以保证覆盖中任一模块中的任意两个元素之间都具有量化容差关系。定义3.2 令 S为一IIS,属性集合 ,容差度阈值 λ∈[0,1],则论域的覆盖
,并不一定能保证 m,n之间也存在着量化容差关系。因此有必要重新定义由量化容差关系所产生的论域覆盖,以保证覆盖中任一模块中的任意两个元素之间都具有量化容差关系。定义3.2 令 S为一IIS,属性集合 ,容差度阈值 λ∈[0,1],则论域的覆盖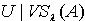 表示如下:
表示如下: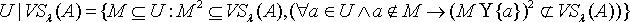
,容差度阈值λ∈[0,1],则 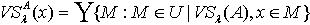
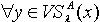 ,有
,有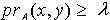 ,于是
,于是 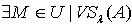 ,使得
,使得 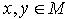 .所以
.所以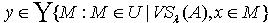 .又因为 y为
.又因为 y为 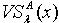 中任意取得,所以
中任意取得,所以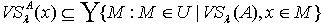
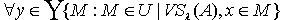 ,必定
,必定 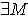 使得 且
使得 且 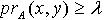 .而此时根据量化容差类的定义,有
.而此时根据量化容差类的定义,有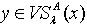 .又因为 y为
.又因为 y为 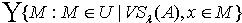 中任意取得,所以有
中任意取得,所以有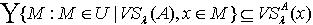 综合(1)(2),定理得证。 由定理3.3可得看出,覆盖
综合(1)(2),定理得证。 由定理3.3可得看出,覆盖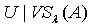 相比于覆盖
相比于覆盖 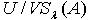 更为精细,即
更为精细,即 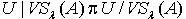 .定理3.4 令 S为一IIS, ,容差度阈值λ1,λ2∈[0,1]且 ,则对于
.定理3.4 令 S为一IIS, ,容差度阈值λ1,λ2∈[0,1]且 ,则对于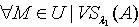 ,必定
,必定 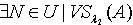 ,使得
,使得 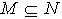 .证明:对于 ,令 ,则
.证明:对于 ,令 ,则 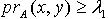 ,因为
,因为 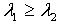 ,所以
,所以 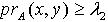 ,即必定有
,即必定有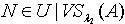 使得
使得 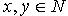 .因为 x,y为 M中任意取得,所以
.因为 x,y为 M中任意取得,所以 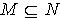 .定理3.5 令 S为一IIS, ,容差度阈值 λ∈[0,1],对于
.定理3.5 令 S为一IIS, ,容差度阈值 λ∈[0,1],对于 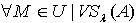 ,必定
,必定 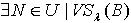 ,使得
,使得 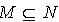 .证明:对于
.证明:对于 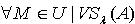 ,令 ,则
,令 ,则 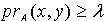 .因为 ,所以
.因为 ,所以 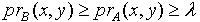 ,即必定存在
,即必定存在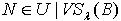 使得
使得 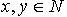 .因为 x,y为 M中任意取得,所以 .定义3.3 令 S为一IIS, ,容差度阈值λ∈[0,1],对于
.因为 x,y为 M中任意取得,所以 .定义3.3 令 S为一IIS, ,容差度阈值λ∈[0,1],对于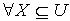 ,论域覆盖为
,论域覆盖为 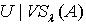 ,X 的上、下近似集合可表示为
,X 的上、下近似集合可表示为 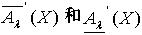 ,其中
,其中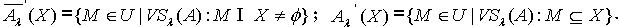
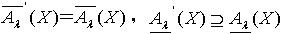 , .证明:(1)令
, .证明:(1)令 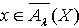 ,则
,则 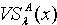 ∩
∩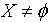 .根据定理3.3,必定
.根据定理3.3,必定 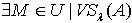 ,使得
,使得 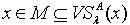 且M∩X≠Φ ,即
且M∩X≠Φ ,即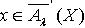 .所以
.所以 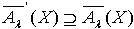 .令
.令 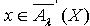 ,则
,则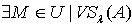 使得x∈M 且M∩X≠Φ .由定理3.3可知,
使得x∈M 且M∩X≠Φ .由定理3.3可知, 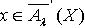 ,即 ∩,
,即 ∩,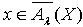 .所以
.所以 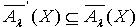 .(2)令
.(2)令 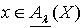 ,则
,则 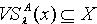 .由定理3.3,对于
.由定理3.3,对于 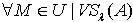 且 x∈M,必定
且 x∈M,必定 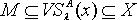 ,即
,即 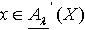 .所以
.所以 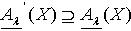 .
.5 结束语
作为一种RST扩展模型以便于直接处理IIS,量化容差关系用容差度描述对象之间的相似程度,是容差关系的进一步拓展。 本文对基于量化容差关系的RST中的一些基本概念,如覆盖的精细程度、粗糙集的近似精度、粗糙熵、知识的粗糙熵以及函数依赖进行了讨论,研究了容差度阈值的变化对这些概念的度量的影响。分析了由量化容差关系产生的论域的覆盖,发现在这个覆盖里,任一模块中的元素都只是与模块的生成元素存在量化容差关系,于是重新定义了基于量化容差关系的覆盖,使得任一模块中的任意两个元素之间都具有量化容差关系,并联系原有覆盖进行了相关性质的讨论。[1] Pawlak. Z. Rough sets and intelligent data analysis[J]. Journal of Information Sciences. 2002,(147) :1-12[2] Kryszkiewicz. M. Rough set approach to incomplete information systems[J]. Journal of Information Sciences. 1998,(112) :39-49[3] Jerzy. Stefanowski. Incomplete information tables and rough classification[J]. Journal of Computational Intelligence. 2001,(17) :545-566[4] 王国胤. Rough集理论不完备信息系统中的扩充. 机研究与. 2002,39(10):1238-1243[5] Qiang Li,Jianhua Li,Xiang Li,and Shenghong Li. Evaluation incompleteness of knowledge in data mining[J]. Springer-Verlag,LNCS(3309). 2004,278-284[6] D.A.Bell,J.W.Guan. Computational methods for rough classification and discovery[J]. Journal of the American Society for Information Science. 1998,(49) :403-414下一篇:图像压缩加密新算法