基于多级指引索引的高效技术
来源:岁月联盟
时间:2010-08-30
1 引言
搜索引擎(Search Engine)是随着Web信息的迅速增加,从1995年开始逐渐起来的技术。它是一种Web上的应用软件系统,以一定的策略在Web上发现和收集信息,对信息进行组织和处理,为用户提供Web信息查询服务。 一个搜索引擎由搜索器、索引器、检索器和用户接口等四个部分组成。其中索引器是一个搜索引擎的核心部分,因此索引的好坏直接影响到整个搜索引擎的质量。采用多级指引索引数据结构,尽管建立时需要付出一定代价,但是极大地提高了查询效率。本文在多级指引索引的基础上,介绍了提高效率的策略,其中包括多级指引索引的压缩,置入文件阈值(posting list threshold)的方法。2 多级指引索引简介
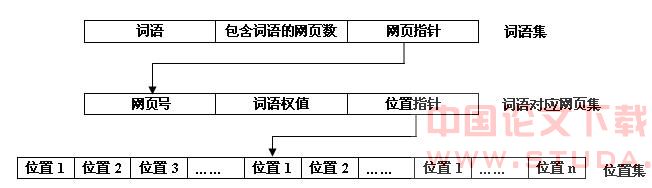
多级指引索引是倒排索引的进化,既满足检索接口的词语-网页结构的需要,又考虑到庞大数据量结构组织的可行性。在词语集设置网页指针,将包含该词语的网页分块放置,减少存储相同词语的空间,根据词语标识符直接找到网页分块首位置,并为下一级指引提供前提;同一个词语在不同网页中出现的位置是变值,设置位置指针可以减少存储相同网页号的空间。
3 多级指引索引的压缩
多级指引索引压缩的目标是通过减少存储需求来降低输入输出。需要压缩的内容包括:词语列表中的词语名,每一个置入文件列表记录(entry)中的词频,每一个置入文件列表记录文档标识符。如果多级指引索引减少存储量,I/O读写置入列表(posting list)的时间就会减少,也就减少了内存、磁盘空间的占用。而一个没有被压缩的多级指引索引通常需要超过30%的空间来存储可压缩的数据,压缩后的数据只占原可压缩数据的10%-15%。但是存在的问题是,要对数据编码解码,增加了CPU时间耗用,考虑到I/O是系统的瓶颈,CPU与I/O之间不断扩大的性能差距,以时间换取空间是可行的。压缩不仅提高查询时的效率,还能加快创建索引,从各方面提升系统性能。 多级指引索引压缩的方法有字节对齐压缩,Elias gamma编码,Elias delta编码,Golomb编码,二元插值编码。3.1 字节对齐压缩(Byte-Aligned)
字节对齐压缩[1]即对于一个给定的正整数,用一个或多个字节表示。表示该数首字节最左边的两位为长度指示器(length indicator),剩余位可以用来存储实际的数。文档ID不同,记为x,文档ID需要基于x的字节标识码,用前面所说的2bits写下长度指示器。写下x的二进制表示法,如下例:0-63 00xxxxxx64-(16K-1) 01xxxxxx xxxxxxxx16K-(4M-1) 10xxxxxx xxxxxxxx xxxxxxxx4M-(1G-1) 11xxxxxx xxxxxxxx xxxxxxxx xxxxxxxx 0 000000001 00000001… …63 0011111164 01000000 0100000065 01000000 01000001字节对齐压缩的优点是容易编码和解码,位操作少,占用CPU时间少,缺点是对很小的整数压缩率低,每个整数最少用一个字节的空间。3.2 Elias gamma(γ)编码
用γ[2]方法表示文档ID的x的数值: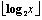 表示2的
表示2的 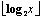 次幂不超过x的最大值;一个0作为标记位(marker);取x-
次幂不超过x的最大值;一个0作为标记位(marker);取x-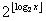 余数二进制编码的
余数二进制编码的 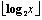 位。用2
位。用2 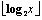 +1bits表示x的值,整数越小,则表示它值的位数就越少。大多数词频相对很小。举个例子:X=22
+1bits表示x的值,整数越小,则表示它值的位数就越少。大多数词频相对很小。举个例子:X=22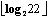 =4 24≤x<254为2的
=4 24≤x<254为2的 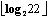 次幂不超过22的最大值,所以得出4位一元码(unary):1111x- =22-24=6用4位二进制数表示余数6:0110最后的γ编码为:1111 0 0110
次幂不超过22的最大值,所以得出4位一元码(unary):1111x- =22-24=6用4位二进制数表示余数6:0110最后的γ编码为:1111 0 0110| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | …… | 63 |
| γ | 0 | 100 | 101 | 11000 | 11001 | 11,0,10 | 11,0,11 | 11111,0,11111 |
Elias Gamma Encoding(γ):Gamma编码对于一元码很小的小整数是有效的,但是对于存储15个以上的整数效率就降低。
3.3 Elias Delta(δ)编码
Delta[2]编码实际上是Gamma编码的延伸,其中整数x由两部分表示,1+位由Gamma编码得出,之后标记位,接下来是x的二进制编码,其中x的最高位取反。Delta编码在表示小的整数的时候需要更多的空间存储,但对于压缩大整数是有效的。3.4 Golomb编码
在Golomb[8]编码中,整数x由两部分组成:商和余数。商q是由q= 得出的,余数r是由r=x-q*k-1出来的,这里的k是Golomb编码的基础。如果r<p,可被存储为位,反之则需要 位,这里的p是一个中心点(pivot point),是由 -k得到的。 当r<p时,Golomb编码是由q个0,一个1,r(用二进制表示)组成的;当r>=p时,它是由q个0,一个1,r+p(用二进制表示)组成的。例如,k=3,整数9就可由00,1,11表示。选择k对整个编码来讲是至关重要的。如果选的不合适,编码会变得很大而且解码也需要很长时间。这里可以考虑0.69*mean(a),a为整型数组。| 值 | 0 | 1 | 2 | 3 | 4 | … | 11 | 12 | 13 | 14 | 15 | … |
| 商 | 0 | 0 | 0 | 0 | 1 | … | 2 | 3 | 3 | 3 | 3 | … |
| 余数 | 0 | 1 | 2 | 3 | 0 | … | 3 | 0 | 1 | 2 | 3 | … |
| 编码 | 100 | 101 | 110 | 111 | 0100 | … | 00111 | 000100 | 000101 | 000110 | 000111 | … |
通过比较,可以将这三种编码方式结合起来,Golomb编码用于文档编号,Gamma编码用于词频,Delta编码用于表示偏移量。
3.5 二元插值编码(Binary Interpolative coding)
二元插值[6]编码利用相邻元素关系,应用于单调递增整数序列。如果在单调序列X1中,对于给定的整数xi,我们知道它的前一个整数是xi-1,后一个整数是xi+1, 由此我们知道存储xi所需要的最大位数。因为xi一定是在[xi-1+1,xi+1-1]的范围内,所以需要的最大比特数为㏒2(xi+1-xi-1-2),编码需要前面的xi-1和xi+1,所以序列X2可由原始的X1的第二个数开始与X1序列对应,编码可以递归的方法。 进一步优化的方法是根据整数序列的平均游程长度(mean run length),对位向量编码增加参数,称作局部模式。比较简单的一种方法是一个整数序列的个数是Pw,则它的平均游程长度是N/Pw,设b=0.69N/Pw,则取VG=(b,b,b,…)作压缩向量,前缀用一元编码,后缀是二进制编码(占用个位)。 在非全文索引当中,置入文件由文档号d和文档词频f组成,一个(d,f)平均可以用一个字节表示;单词t的置入文件可以根据t的IDF(Inverse Document Frequency)推算出来。 在全文索引中,单词出现的位置信息占据索引数据的主要部分,所以忽略文档号d和文档词频f。用变长压缩算法,单词出现的位置可以用少于8bit的位表示。设全部文档分词后的单词总数是TN,那么单词t总的出现次数是TN×TF(Term Frequency),它的置入文件的平均长度小于TN×TF字节。3.6 多级指引索引压缩
根据[10]这几种压缩方法的压缩效率,解压速度以及相对性能的比较如表一所示: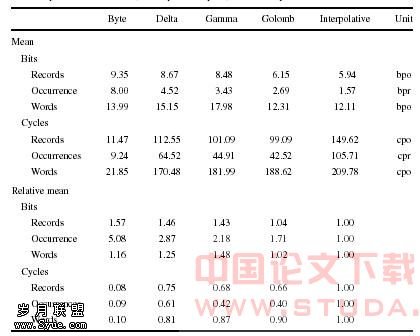
其中bpo-每个事件(occurrence)的比特数,bpr-每个记录的比特数,cpo-每个事件的周期数,cpr-每条记录的周期数。 我们可以假设1.4GB的多级指引文件列表通过最高效的方案(根据表1)被压缩,载入与解压的总代价如下: U≈T+EnA+dn,其中U是总时间,T是寻道时间(seek time),EnA是读需要的时间,dn是在内存中解压的时间,n是被读取的已压缩整数的量。 当n很大时,寻道时间就可以忽略,解压方案的性能P由读和解压时间来决定,P≈EA+d; 当n趋于0的时候,性能完全取决于寻道时间,P≈T,P≈T=(M-C)*R+C。 其中M表示测量的磁盘平均寻道时间,C是时钟周期固定寻道时间,R是压缩后的文件占压缩前的比率。 通过这个式子可得出当编码的整数数目很小的时候,二元插值编码性能最好,但是在速度上Golomb编码要超过其它的编码,当数目越来越大的时候,变长字节编码是最高效的。如图4示(其中横坐标表示记录数,纵坐标表示时钟周期数)。

总结起来,在多级指引文件信息检索的过程中,处理长的多级指引文件是一个瓶颈,所以随着多级指引文件的增加而提高性能是一个好的解决方法。当多级指引文件小的时候,吞吐量由磁盘寻道时间决定,这个时间是与磁盘文件的长度相关的。减少文件的长度就会减少磁盘寻道的长度,选择基于最小化文件的压缩是最好的(例如Golomb)。随着文件长度的不断增加,磁盘寻道时间变得不那么重要,吞吐量与解压速度密切相关,所以变长字节编码最合适。如果磁盘空间需要额外的开销,推荐用Golomb压缩算法,使用Golomb算法可以使文件压缩的更小并且解压速度比gamma和delta算法更快。由Moffat和Zobel提出的使用Golomb算法表示文档号gamma算法表示词频的方法不如使用Golomb同时表示文档号和词频高效。
4 置入文件阈值(Posting list threshold)
置入文件阈值也称Topdocs,实际上是一种有损压缩(lossy compression),就是说有的信息可能被丢弃。 这个算法的主要思想是,对多级指引索引I进行修剪,每一个词语t对应n个文档d,将那些权值A(d,t)很小并且对系统准确性影响很小的文档进行修剪,只保存权值最高的k篇(TOP K)。算法描述: 为了评价Topdocs算法对精确率的影响,我们应用TREC(Text Retrieval Conference)的官方结果[9],下表说明了提交给TREC运行的准确度,结果显示P@10(threshold为10)在索引修剪之后基本上没什么变化,并且在平均精确率(MAP)上的差别是可以忽略的。
为了评价Topdocs算法对精确率的影响,我们应用TREC(Text Retrieval Conference)的官方结果[9],下表说明了提交给TREC运行的准确度,结果显示P@10(threshold为10)在索引修剪之后基本上没什么变化,并且在平均精确率(MAP)上的差别是可以忽略的。| ε | 索引大小 | 修剪率(%) | MAP | P@10 |
| 0 | 3.53GB | 0 | 0.211 | 0.362 |
| 0.05 | 3.15GB | 10.7 | 0.207 | 0.362 |
| 0.1 | 2.9GB | 17.8 | 0.205 | 0.360 |