基于ZSP500的高效程序优化设计
来源:岁月联盟
时间:2010-08-30
1 引言
DSP芯片自20世纪80年代诞生以来,在短短的二十多年取得了飞速的,随着DSP芯片性价比和应用范围的不断扩大,DSP处理器的品种越来越多,LSI Logic公司生产的具有开放式结构的数字信号处理器ZSP系列在许多领域都有广泛的应用,其中ZSP400在全球的无线、IP电话、消费类音频的具有广泛的接受度,ZSP500是针对3G无线和多媒体应用而设计的,ZSP600是基站和设备的理想选择[1]。 每一次序号的提升,都表示硬件性能的快速提高,硬件性能的提高可以减轻软件设计的压力,但是硬件性能的不断提高,产品的成本也在不断的提高,过度、过快的硬件升级换代对应用也有害处,而基于一定的硬件资源,进行优化软件,提高硬件资源的利用率,实现目标要求就变得比较重要,这样会减少产品成本,达到较高的性价比。本文是在与中兴公司合作开发新一代语音编解码器基础上的经验,基于ZSP500的硬件资源,介绍了基本的优化方法,充分挖掘硬件的潜力,取得了良好的效果。2 ZSP500芯片硬件资源介绍
ZSP500是针对3G和多媒体应用而设计的,在内存、功耗、性能方面有着优秀的表现,它是基于RISC的超标量架构,其硬件规划可以根据分组原则确定每个时钟周期要执行的指令条数,并且ZSP500具有静态分支预测功能,可以减少分支跳转惩罚,ZSP500的指令集简单、易懂,条件执行可以执行多达8条相邻指令,可以减少分支,加速数据依赖算法的实现等等。ZSP500的内核是一个四通道超标量、双MAC的数字信号处理器,时钟频率250MHz,拥有16个16位通用寄存器,相邻的两个16位寄存器可以合并为32位寄存器,与8个相应的8位引导寄存器可构成40位通用寄存器,8个32位基址寄存器,一个时钟周期最大可以执行64位数据的读取,双MAC可以达到每秒500M的MAC操作,同时具有双算术逻辑单元(ALU0,ALU1),双地址生成单元(AGU0,AGU1)[2][3][4]。 ZSP500指令执行的8级流水线线分别为取指/译码(F/D)、指令分组(GR)、读书据(RD)、地址生成(AG)、内存连接0(M0)、内存连接1(M1)、执行(EX)、数据写回(WB)[3],如图1所示。熟悉指令各个流水线阶段数据和寄存器内容变化的时序,可以规避各种数据和资源的冲突,保持流水线长时充满,硬件资源充分利用,程序高效、稳健。
图1 ZSP500 八级流水线
3 程序优化策略
程序优化总体原则:基于ZSP500的硬件资源,根据指令分组原则[3]编写简洁、高效的汇编指令,能够长时保证流水线的充满,充分发挥利用ZSP500强大的运算功能。评价标准:硬件资源的利用率和每时钟周期实际指令执行条数。 优化流程:基于ZSP IDE集成开发环境,测试纯C语言工程的执行效率,开发环境的设置上我们可以开起开发环境的自动优化选项-03级优化,这样开发环境可以对C语言程序自动进行三级速度优化[2],在这种设置下,根据开发环境提供的工具,测试寻找程序耗时较高的程序段或子函数,进行C语言级的优化,优化完毕后,测试优化结果,如果满足目标要求,则优化任务完成。如果不满足要求要求,则要进行汇编级程序优化,这时我们要将耗时较高的函数或程序段进行手工汇编并进行优化,直至满足优化要求。通常情况下,汇编程序的优化效果比较明显,也是优化要求能否达到的关键,整个流程如图2所示。3.1 C语言的优化
C语言的优化主要方法是(1)根据ZSP IDE编译原理编写合适的C语言源程序,使得开发环境能够自动将C语言转换成为高效的汇编程序;(2)合理的拆分C语言程序,良好的、易懂的C语言结构不代表高效的C语言执行效率;(3)利用内联函数,减少函数调用所造成的时间损耗,特别是被频繁调用的子函数,充分利用DSP库函数替代原有的具有相同功能的C函数,DSP库函数是针对DSP硬件资源编写的高效功能模块函数,能大大提高C语言程序的执行效率[5][6]。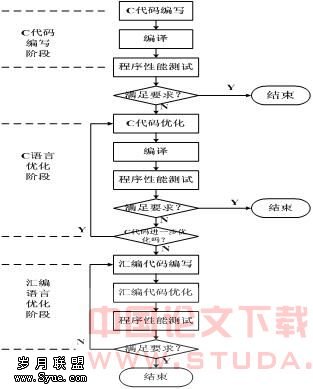
3.2 高效汇编程序的编写与优化
将优化后的C语言程序,在ZSP IDE环境下测试C语言的执行效率,具体根据程序执行所耗费的总时钟数(cycle),耗费的总cycle数目中1 group cycles,2 group cycles,3group cycles1,4 group cycles的各自数目,以上四种情况分别表示每个cycle执行的汇编语句(IPC),若4 group cycle的数目最多,则指令充分应用了提供的硬件资源,程序的执行效率较高[2]。编写出高效率的汇编程序,整体上可以从以下几点考虑: (1)最大限度的保持长时流水线充满,尽量避免在连续的大量程序中使用判断语句,或改变控制寄存器的汇编语句,这样会导致预取指令中途被冲,无指令执行的状态(IPC=0)。 (2)避免频繁的ZSP核与外界存储子系统进行信息的交互,对同一物理地址的内存存储和读取要间隔合适的时间,防止出现STALL现象[3]。同时数据的存储和读取最好应用字装载或双字装载指令,既可以避免频繁与存储系统的交互,又可以提前取出需要的数据,减少运算等待时间。 (3)明确各种指令使用的硬件资源,特别是有的指令可以使用多种硬件资源,而有的指令只能使用特有的硬件资源,明确各个时钟周期是否有相应的硬件资源可用,否则会出现资源冲突,引起时钟等待。 (4)主调程序和被调程序的空间安排要尽量安排较近,防止远跳带来的时钟损耗,若是频繁调用最好能够将子程序直接嵌入。3.2.1 一般手工汇编方法 利用ZSP开发环境的自动优化功能,编写线性汇编指令,线性汇编指令的编写,要考虑数据运算的相关性,这样自动优化的效果才能达到最高。手动优化要根据指令分组原则[3]和ZSP500的硬件资源和硬件资源的使用优先级,明确各个时钟周期指令的硬件资源需求,编写和调整汇编指令的顺序,达到同一时钟周期汇编指令执行的最大化和硬件资源利用率的最大化。硬件资源使用顺序为[3]: 1 ALU0 2 ALU1 3 ALU0和ALU1 4 MAU 以下为一个指令示例,例如: 周期1: add.e r0, r2 (使用ALU0和ALU1) shra r3, 1 (使用MAU) 周期2: add r7, r15 (使用ALU0) 由于周期1的第一条指令同时使用了两个ALU,导致第二条指令必须使用MAU,这样就浪费了MAU的处理能力。通过调整,以上指令可以调整为: add r7, r15 (使用ALU0) add.e r0, r2 (使用MAU) shra r3, 1 (使用ALU1) 这样三条指令在同一个周期中完成,并且符合指令的分组原则,速度提高100%,同时寄存器之间不存在数据的相关性,不仅节省了程序执行的时间3.2.2循环优化方法 对于运算量占用极大的循环程序,循环嵌套的展开,循环的展开,软件流水线的应用可以大大提高汇编语句执行的效率,循环次数的统计要应用硬件资源,避免出现判断语句存在于循环体,循环代码的优化是汇编代码优化的重点[3][8]。以一段C代码的优化过程为例:原始C代码如下: for(n=0,i=0;n<N;n=n+2,i++) C[i] = A[n]*A[n]+A[n+1]*A[n+1]; 手工汇编代码为: Mov %loop0 ,N-1 lda a0, C !!取数组C[n]的首地址 lda a1, A !!取数组A[n]的首地址 M_Aloop: 周期1: lddu r0, a1, 2 !!周期1, 取数 A[n] 周期2: mul2 r4, r0, r0 !!周期2 ,C[n]的计算 周期3 stu r4, a0,1 !!周期3, C[n]的存储 agn0 M_Aloop !!循环次数减1 以上循环汇编程序的编写,每个周期硬件资源没有得到充分的利用,指令执行的条数较少,IPC=1.33(instruction per cycle)一个循环需要3个时钟周期。可以从循环的展开、预取数、对数据进行双字操作方向进行优化。优化后的循环为: mov %loop0 ,(N/2)-1 ldqu r0, a1, 4 !!循环外预取数,对数据进行双字操作 M_Aloop: 周期1: mul2 r4, r0, r0 !!C[n] 的计算 周期2: mul2 r6, r2,r2 !! C[n+1]的计算 ldqu r0, a1, 4 !!第二次循环的预取数 周期3: stu r5, a0,2 !! C[n] 的存储 stu r7, a2,2 !! C[n+1]的存储 agn0 M_Aloop !!循环次数减1 改动后的一次循环仍然耗费3个时钟周期,但是循环次数减少了一半,IPC=2,效率提高了100%。ZSP500最高IPC=4,优化后的程序执行效果仍然不是很理想。为此继续进行优化,采用软流水的方法对汇编程序继续优化,软流水就是从一个循环环出发,构成多重并行执行的迭代运算,也就是在1次主迭代运算完成前,启动一次新的循环迭代运算。程序如下: mov %loop0 ,(N/2)-2 ldqu r0, a1, 4 !!循环外预取数,对数据进行 双字操作 mul2 r4, r0, r0 mul2 r6, r2,r2 ldqu r0, a1, 4 M_Aloop: 周期1: stu r5, a0,2 !! C[n] 的存储 (1次迭代的完成) stu r7, a2,2 !! C[n+1]的存储(1次迭代的完成) mul2 r4, r0, r0 !! C[n] 的计算 (2次迭代的开始) 周期2: mul2 r6, r2,r2 !! C[n+1]的计算(2次迭代的开始) ldqu r0, a1, 4 !!第二次循环的预取数 agn0 M_Aloop !!循环次数减1 采用软流水优化后的程序,循环次数为原始的一半,同时单循环耗费时钟周期为2,IPC=3。循环采用优化方法后,结果如表1循环优化效果所示,整体优化效果显著。表1 循环优化效果| 指标 优化方法 | 单循环指令数 | 循环次数 | 单循环耗费时钟数 | IPC(每时钟周期执行指令数) | 与源汇编程序比较效率提高百分比 | |
| 源汇编程序 | 4 | N | 3 | 1.33 | 0% | |
| 预取数、循环展开优化 | 6 | N/2 | 3 | 2 | 100% | |
| 软流水优化 | 6 | N/2 | 2 | 3 | 200% | |
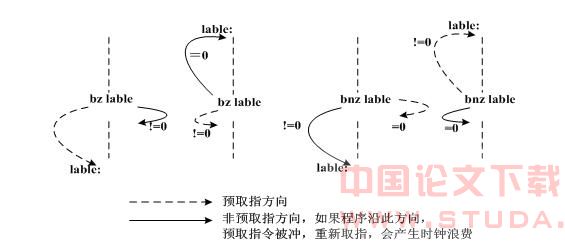
跳转指令会导致流水线的中断等待状态,ZSP核不知要到哪个分支取指令,为此ZSP500中的跳转指令设置了跳转预测功能[3],如bz lable指令有向前预取指令的功能,如果lable标签存于bz 指令下方,则程序将预取以lable标签开始的汇编指令,如果lable标签存于bz指令上方,则程序预取紧跟bz指令的汇编指令,而bnz指令则向后预取指令,具体如图3 bz bnz指令预测方向图所示[8],其他如bge、ble、br等指令预测方向皆不相同,满足编写程序的需要。有此预测功能,编写汇编程序时就要将发生几率最大的程序块放在跳转指令预测方向,减少由于跳转预测错误而引起流水线被冲,重新取指而带来的ZSP核的等待。3.2.4特殊硬件资源和指令资源的利用 ZSP500可以通过控制寄存器的设置开启四个数据缓冲区,此四个数据缓冲区采用比特反转寻址,并且当指向缓冲区底部时,会自动回转到缓冲区顶部,这种性能在应用ZSP500进行FFT算法实现时可以达到很好的效果。在软件设计上很难达到的速度优化效果,应用硬件特殊的物理器件功能,就变得十分容易实现了。同时ZSP500还提供特殊的汇编指令资源,如复合指令cmaci、cmuli,功能指令max、min等,其中max可以实现取两个数据的较大者,min指令可以实现取两个数据的较小者,特殊指令的应用,可以避免跳转指令、比较指令的使用,减少跳转指令预测错误造成的时钟浪费[8]。如: if (var2 < -32) var2 = -32 ; else if(var2>32) var2 = 32 ;对应的汇编指令: mov r0, -32 mov r1, 32 !!r2 = var2 max r2, r0 !!取比-32大的数 min r2, r1 !!取比32小的数 以上汇编程序没有跳转指令的应用。 以上详细分析了各种汇编优化策略,在具体的项目工程中要充分的应用以达到优化效果的最大化,程序各种优化方法的使用要结合硬件资源,在硬件资源足够的情况下合理的使用。以一段完整的程序优化为例:C代码如下: if(var1 = var2) //利用跳转预测的方法优化 {for (i = 0,n=0;n < 80; n=i+2,i++) c[i] = a[n]*a[n] + a[n+1]*a[n+1]; //利用软流水的方法优化 if (var2 < -32) var2= -32 ; //利用ZSP500提供的特殊指令优化 else if (var2>32) var2 = 32 ; c[41] = var2;} else{for(i = 0;i < 41 ;i++) c[i] = 0;} //利用循环优化 综合利用以上提供的优化策略和代码,整体进行汇编语言的编写和调整,程序执行的效率可由ZSP IDE中的统计工具ZSIM SRTATISTICS统计得出,由图4可以看出C源程序采用三级自动优化后耗费时钟206 clock,效率1.40 IPC,每时钟周期执行两条指令居多59.22%,由图5可得采用手工汇编并优化后整体耗费时钟48 clock,效率2.85 IPC,单时钟执行三条指令居多达79.17%,大大提高了程序的执行效率,优化后整体没有流水线保护、停顿状态(0 group cycle = 0),优化后程序执行速度提高了3倍。
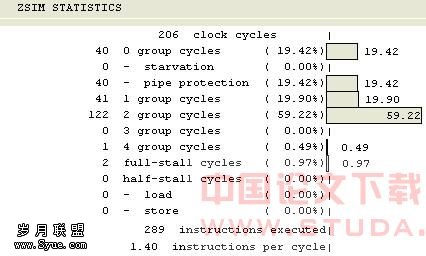
图4 C源程序进行自动三级优化效率统计
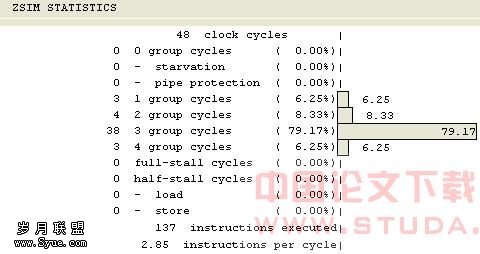 图5 手工汇编并优化执行效率统计
图5 手工汇编并优化执行效率统计