一种改进的关联规则挖掘方法
来源:岁月联盟
时间:2010-08-30
1 问题概述
关联规则的挖掘的形式化描述如下:令I={i1,i2,…im}为项目集(也称为模式),D为事务(又称交易)数据库,其中每个事务T是I中一组项目集合,即T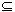 I,并令其有一个唯一的标识符TID。如果对于I中的子集X有X T,则事务包含项目集X。关联规则就是形如X
I,并令其有一个唯一的标识符TID。如果对于I中的子集X有X T,则事务包含项目集X。关联规则就是形如X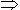 Y的逻辑蕴涵式,其中X I,Y I,且X∩Y=
Y的逻辑蕴涵式,其中X I,Y I,且X∩Y= 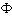 。如果D中S%交易包含X∪Y,关联规则X Y在D中具有支持s。如果D中c%的包含X的交易也同时包含Y,则关联规则X Y在D中可信度c成立。关联规则挖掘一般分为两步:①发现所有的频繁项目集,也就是说这些项目集在数据库中的支持计数必须不小于预先设定的一个阈值,即最小支持度;②由频繁项目集产生强关联规则,也就是说这些强关联规则必须满足最小支持度和最小可信度。其中第2步,一般采用如下方法:对于一个频繁项目集l的每一个非空子集s如果support_count(1)/ support_count(s)≥min_conf,(其后support_count(1)表示项目集l在数据库中的支持计数,而min_conf表示最小可信度)则规则输出:“s (1-s)”,该规则也称为强关联规则,第2步相对比较简单,目前大部分研究工作都针对第1步,以改进寻找频繁项目集的效率,本文针对第1步提出了一种称为ALT的改进算法。
。如果D中S%交易包含X∪Y,关联规则X Y在D中具有支持s。如果D中c%的包含X的交易也同时包含Y,则关联规则X Y在D中可信度c成立。关联规则挖掘一般分为两步:①发现所有的频繁项目集,也就是说这些项目集在数据库中的支持计数必须不小于预先设定的一个阈值,即最小支持度;②由频繁项目集产生强关联规则,也就是说这些强关联规则必须满足最小支持度和最小可信度。其中第2步,一般采用如下方法:对于一个频繁项目集l的每一个非空子集s如果support_count(1)/ support_count(s)≥min_conf,(其后support_count(1)表示项目集l在数据库中的支持计数,而min_conf表示最小可信度)则规则输出:“s (1-s)”,该规则也称为强关联规则,第2步相对比较简单,目前大部分研究工作都针对第1步,以改进寻找频繁项目集的效率,本文针对第1步提出了一种称为ALT的改进算法。2 研究现状
目前,关联规则挖掘算法中,最有影响的是AGRWAL和SRIKANT于1994年提出的Apriori算法[1]。在许多情况下,Apriori的候选产生-检查方法大幅度压缩了候选项目集的大小,并导致很好的性能,然而,它有两种开销微不足道:①可能产生大量候选项目集;②可能需要重复地扫描数据库,通过模式匹配检查有一个很大的候选集合,但有一种有趣的称为频繁模式增长(Frequent_Pattern Growth),或简称FP-增长解决了此问题。它采用如下分治策略:将提供频繁项目集的数据库压缩到一棵频繁模式树(FP-树),并仍保留项目集关联信息;然后将这种压缩后的数据库分成一组条件数据库(一种特殊类型的投影数据库),每个关联一个频繁项,并分别挖掘每个数据库。对于挖掘长的和短的频繁模式,FP-树方法都是有效的和可伸缩的,并且比Apriori方法快一个数量级。其它关联规则挖掘方法还有[1]中讨论且给出的AIS算法,参考文献[2]给出的SETM算法及文献[3]给出的IUA算法。3 ALT算法
Alt算法只需遍历事务数据库一次,用来生成频繁1—项目集。并由此可以得到频繁2—项目集,频繁3—项目集,……,频繁k项目集。对于频繁i(1≤i≤k)—项目集,采用了一种特殊的数据结构——链表簇来存贮。簇中的每一链表用来表示频繁i—项目集各项目的信息,表头节点(patternData)和表节点(tidData)存储结构如图1所示。| nextL | pattern | newed | count | nextP |
| tid | nextP |
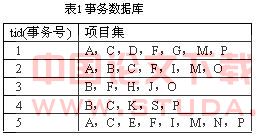
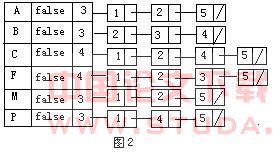
| 图2 频繁1-项目集链表簇构造 |
上一篇:关联规则的增量更新算法研究